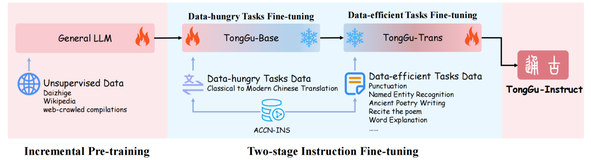
如今,大语言模型如雨后春笋般涌现,为自然语言处理领域带来了前所未有的变革。然而,直接使用这些大规模预训练模型在特定任务上可能并不总是能达到最佳效果。这时,LoRA(Low-Rank Adaptation)技术就成为了实现大模型微调的有力工具。
LoRA 的核心思想是通过低秩矩阵分解来减少模型微调所需的参数数量。在传统的全模型微调中,需要调整大量的参数,这不仅计算成本高,而且容易导致过拟合。而 LoRA 则通过将模型参数的更新矩阵分解为两个低秩矩阵的乘积,从而大大降低了参数数量和计算成本。
那么,LoRA 是如何具体实现大模型微调的呢?首先,我们需要选择一个预训练的大语言模型作为基础模型。这个模型通常已经在大规模的文本数据上进行了训练,具有强大的语言理解和生成能力。然后,我们可以使用特定的任务数据对模型进行微调。
在微调过程中,LoRA 会在模型的每一层中插入一个可训练的低秩矩阵。这个矩阵的作用是捕捉特定任务的信息,而不会对模型的整体结构产生太大的影响。通过调整这个低秩矩阵的参数,我们可以使模型更好地适应特定任务的需求。
为了更好地理解 LoRA 的工作原理,我们可以看一个简单的示例代码。假设我们有一个预训练的语言模型,我们想要使用 LoRA 对其进行微调以进行文本分类任务。
import torch
import torch.nn as nn
# 假设这是一个预训练的语言模型
class PretrainedModel(nn.Module):
def __init__(self):
super(PretrainedModel, self).__init__()
self.embedding = nn.Embedding(10000, 512)
self.layers = nn.Sequential(
nn.Linear(512, 1024),
nn.ReLU(),
nn.Linear(1024, 1024),
nn.ReLU(),
nn.Linear(1024, 2) # 假设是二分类任务
)
def forward(self, x):
x = self.embedding(x)
return self.layers(x)
# 使用 LoRA 进行微调
class LoRAFinetunedModel(nn.Module):
def __init__(self, pretrained_model):
super(LoRAFinetunedModel, self).__init__()
self.pretrained_model = pretrained_model
# 在每一层插入低秩矩阵
for layer in self.pretrained_model.layers:
if isinstance(layer, nn.Linear):
in_features = layer.in_features
out_features = layer.out_features
rank = min(in_features, out_features) // 4
self.lora_A = nn.Parameter(torch.randn(in_features, rank))
self.lora_B = nn.Parameter(torch.randn(rank, out_features))
def forward(self, x):
x = self.pretrained_model.embedding(x)
for layer in self.pretrained_model.layers:
if isinstance(layer, nn.Linear):
x = layer(x) + torch.matmul(torch.matmul(x, self.lora_A), self.lora_B)
else:
x = layer(x)
return x
通过这个示例代码,我们可以看到如何在预训练模型的基础上使用 LoRA 进行微调。在实际应用中,我们可以根据具体的任务和数据进行更加复杂的调整和优化。
总的来说,LoRA 为大模型的微调提供了一种高效、灵活的方法。它不仅可以降低计算成本,减少过拟合的风险,还可以使我们更好地利用预训练模型的强大能力。随着大语言模型的不断发展,LoRA 技术无疑将在自然语言处理领域发挥越来越重要的作用。让我们一起深入探索 LoRA 的奥秘,为构建更加智能的自然语言处理系统贡献自己的力量。