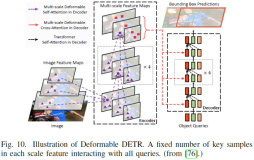
问题一:如何模拟人类绘画过程的能力?
如何模拟人类绘画过程的能力?
参考回答:
Mask并行解码通过确定大致轮廓和逐步填充细节来模拟人类绘画过程。模型首先学会捕获整体结构和重要特征,类似于初步勾画草图。然后,在后续步骤中细化预测,增加细节和深度,类似于在素描中逐步填充细节。
关于本问题的更多回答可点击原文查看:
https://developer.aliyun.com/ask/659427
问题二:Muse模型是如何生成高分辨率图像的?
Muse模型是如何生成高分辨率图像的?
参考回答:
Muse模型采用“生成+超分”的级联方式生成高分辨率图像。首先,通过Base Transformer生成一个低分辨率的图,然后使用一个叫做SuperRes Transformer的超分模型来扩大生成图像的分辨率并修饰局部细节,从而得到高分辨率的图像。
关于本问题的更多回答可点击原文查看:
https://developer.aliyun.com/ask/659428
问题三:Base Transformer和SuperRes Transformer在训练过程中分别实现什么功能?
Base Transformer和SuperRes Transformer在训练过程中分别实现什么功能?
参考回答:
在训练过程中,Base Transformer实现的功能是输入被Mask掉的image tokens,并基于text embedding预测被mask掉的token。而SuperRes Transformer则负责输入被Mask掉的image tokens,并基于text embedding和生成阶段的结果预测被mask掉的token,以实现图像的超分辨率生成。
关于本问题的更多回答可点击原文查看:
https://developer.aliyun.com/ask/659429
问题四:在inference阶段,Base Transformer和SuperRes Transformer分别需要多少次迭代来生成图像tokens?
在inference阶段,Base Transformer和SuperRes Transformer分别需要多少次迭代来生成图像tokens?
参考回答:
在inference阶段,Base Transformer使用MaskGIT中的并行加速方法,仅需24次迭代就可以生成16×16个image tokens。而SuperRes Transformer也采用相同的加速方法,在inference时仅需8次迭代就可以生成64×64个image tokens。
关于本问题的更多回答可点击原文查看:
https://developer.aliyun.com/ask/659430
问题五:TECO代码中的编码流程是怎样的?
TECO代码中的编码流程是怎样的?
参考回答:
TECO代码中的编码流程包括几个关键步骤。首先,通过查询码本embeddings,将输入的编码indices转换为embeddings。然后,添加一个sos token到序列的最前面。接着,在时间轴上,将t和t+1的embedding concat到特征维度上。之后,将concat后的序列输入到ResNetEncoder中进行编码。最后,对编码后的主体部分进行量化处理,得到量化embedding和量化索引等。
关于本问题的更多回答可点击原文查看: