
前言
前段时间我把微信小号接入了AI语言模型,同事们直呼过瘾,每天在群里聊得风生水起
这不前段时间看了《流浪地球2》,在感叹国产科幻片如此优秀的同时,心中萌生出了一个想法,我是不是也能把语音技术结合到AI语言模型中,做个语音对话机器人玩玩?
说干就干,参照之前的文章,我们使用nodejs实现了AI语言模型接口,现在只需在前端页面中实现语音识别以及语音合成就行了
起步
说到语音功能,浏览器已经提供了对应的Web Speech API,其中有两个对象,分别是
- webkitSpeechRecognition:语音识别对象
- speechSynthesis:语音合成对象
借助这两个对象,我们可以调用麦克风和扬声器,对浏览器进行交互
下面是一个简单的流程,用户使用webkitSpeechRecognition中的函数进行语音识别,将字符发送到之前做的接口中,AI模块调用openai换取AI模型输出结果,返回到浏览器,浏览器通过speechSynthesis合成音效,完成一个对话周期

实现过程
webkitSpeechRecognition
// 创建语音识别对象 const recognition = new webkitSpeechRecognition(); // 语音设置成中文 recognition.lang = "zh-CN"; // 开始识别 recognition.start(); // 当识别到语音时触发事件 recognition.addEventListener("result", (event) => { console.log(event.results); });
使用上述代码后,页面中会弹出权限请求,点击允许

然后我们直接说话就会有识别结果(需要挂vpn)

如果打开了麦克风,但是说话没有反应的,大概率是因为识别服务没请求到,需要挂vpn
此外, webkitSpeechRecognition类还有以下常用配置:
recognition.continuous = true 持续识别,直到调用stop,默认为false,识别一次就会自动关闭
recognition.interimResults = true 识别时是否打断并更新结果,默认为false,设置为true时会有如下效果

speechSynthesis
接下来看看语音合成
const speakText = new SpeechSynthesisUtterance("hello world"); speechSynthesis.speak(speakText);
在控制台输入以下代码,即可合成hellow world的语音效果
小例子
了解了上述用法,我们可以在浏览器上实现模仿自己说话的功能,代码如下
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8" /> <meta http-equiv="X-UA-Compatible" content="IE=edge" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <title>ASR-Node</title> <style> * { margin: 0; padding: 0; } #app { width: 1000px; margin: 100px auto 0; text-align: center; } h3 { margin-bottom: 20px; } </style> </head> <body> <div id="app"> <h3>ASR-Bot</h3> <main> <span>发送:</span> <span id="send_msg"></span> <br /> <span>接收:</span> <span id="rec_msg"></span> </main> </div> <script type="module"> const speak = (str) => { rec_msg.textContent = str; const speakText = new SpeechSynthesisUtterance(str); // 转换字符 speechSynthesis.speak(speakText); // 语音合成 }; const listen = () => { // 创建语音识别对象 const recognition = new webkitSpeechRecognition(); // 语音设置成中文 recognition.lang = "zh-CN"; // 当识别到语音时触发事件 recognition.addEventListener("result", (event) => { const { results } = event; console.log(results); const len = results.length; const { transcript } = results[len - 1][0]; send_msg.textContent = transcript; speak(transcript); }); return recognition; }; // 开始识别 listen().start(); </script> </body> </html>
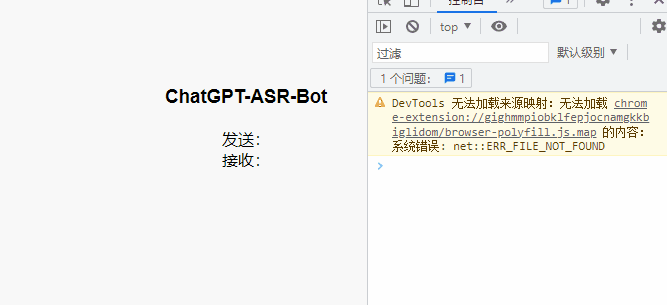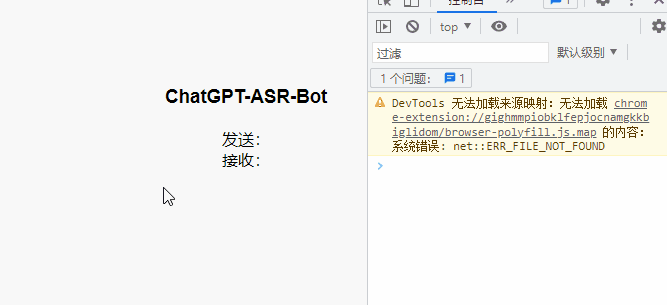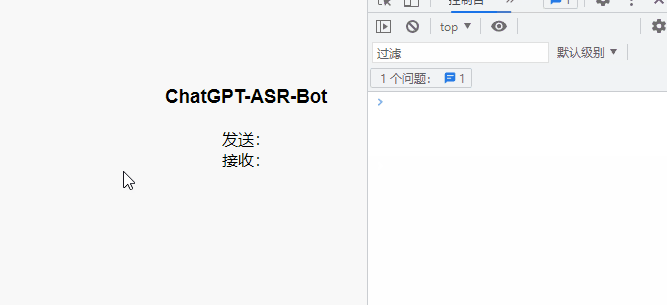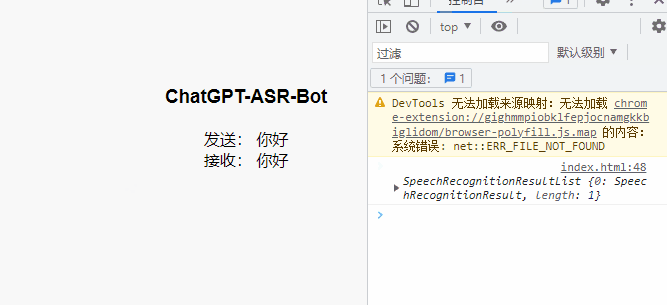
虽然放不了声音,但是效果还是很直观的:
遇到的问题
虽然在识别时使用了continuous:true属性。webkitSpeechRecognition仍然会超时自动关闭。解决方式是在其end事件钩子中执行重新识别的操作
效果展示
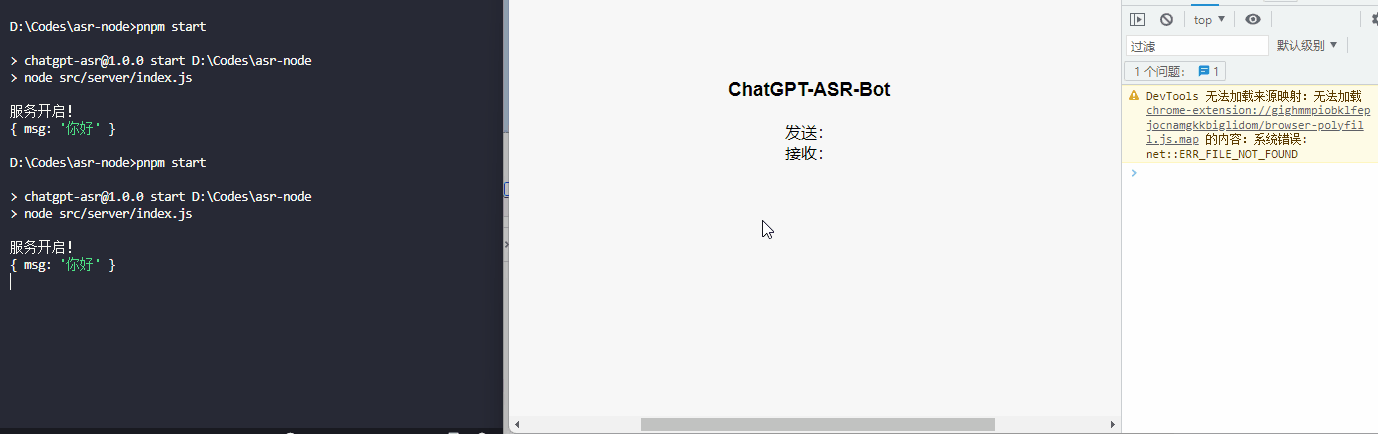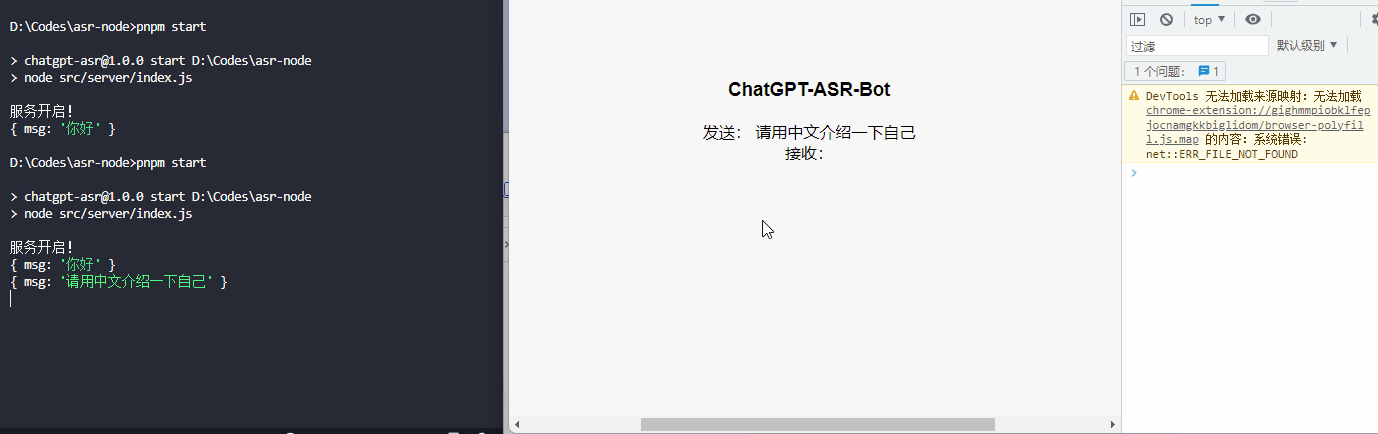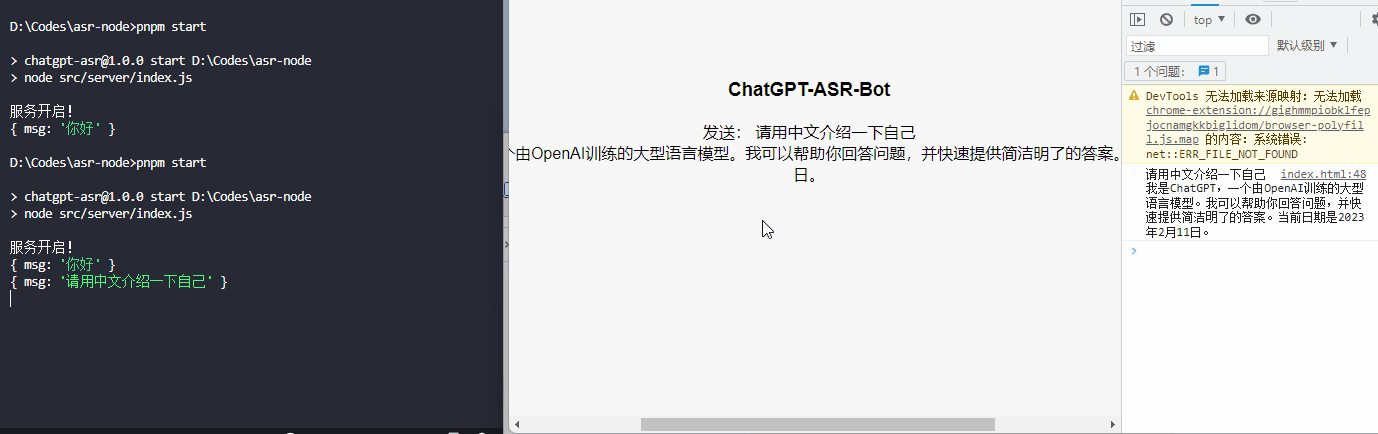
总结
本文带领各位认识了Web Speech API的两个对象以及常用的函数,实现了一个模仿自己说话的案例,并接入最近比较火的AI模型,以实现一个类似小爱同学的语音助手的语音对话功能。
最后,感谢你的阅读,如果文章对你有帮助,还希望支持一下作者。
在这里我也抛砖引玉,期待看到大家的进阶玩法


