大家好,我是你们的技术小伙伴小米!今天我们来聊聊如何在数据处理过程中保证顺序消费的问题。这个话题非常重要,尤其是在大数据处理和消息队列系统中,顺序消费是实现数据一致性和正确性的关键步骤。那么,如何才能有效地保证顺序消费呢?接下来,我将详细分享几种常见的方案和它们的优缺点。
单 Topic,单 Partition,单 Consumer,单线程消费
首先,让我们来看一种最简单也是最直接的方案:单 Topic,单 Partition,单 Consumer,单线程消费。
这种方案的优势在于简单直接,因为只有一个 Consumer,所以可以确保消息是按顺序消费的。但是,它也有明显的劣势,那就是吞吐量低,不能满足高并发和大数据量场景的需求。
为什么吞吐量低?
- 单线程限制:由于只有一个 Consumer 在单线程中处理消息,这意味着无法利用多核 CPU 的并行处理能力,性能瓶颈明显。
- 单 Partition 限制:Kafka 的设计中,Partition 是并行处理的基本单位。如果只有一个 Partition,那么无论 Consumer 如何优化,都无法突破单 Partition 的吞吐量限制。
适用场景
这种方案适用于数据量小、并发量低,并且对顺序性要求非常高的场景。例如,某些金融交易系统中的重要交易日志记录,或者一些小型的监控报警系统等。
单 Key 顺序消费方案
在大多数实际应用中,我们通常需要保证的是某个特定 Key 的消息顺序性,而不是所有消息的全局顺序性。例如,在一个用户行为日志系统中,我们希望同一个用户的操作日志是有序的,但不同用户之间的日志则没有严格的顺序要求。
方案设计
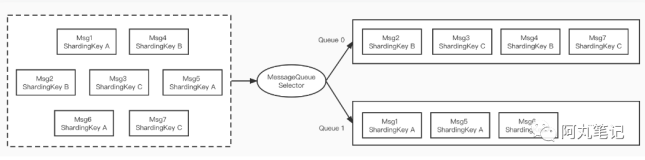
针对这种需求,我们可以设计一种更高效的方案:为每个 Key 申请一个单独的内存队列(Memory Queue),然后由多个线程分别消费这些内存队列,从而保证每个 Key 的顺序性。
具体实现步骤如下:
- 消息路由:在消息生产阶段,根据消息的 Key(例如用户 ID 或活动 ID)将消息路由到对应的内存队列中。
- 内存队列:每个 Key 对应一个内存队列,保证同一个 Key 的消息进入同一个队列,从而保证顺序。
- 多线程消费:启动多个 Consumer 线程,每个线程消费一个或多个内存队列,从而实现并行处理,提升整体吞吐量。
优点
- 保证顺序性:同一个 Key 的消息始终由同一个队列和线程处理,确保消息顺序。
- 提高吞吐量:通过多线程并行消费多个队列,充分利用多核 CPU 的性能,提升系统的整体吞吐量。
关键技术点
- 负载均衡:需要合理分配 Key 到各个队列,避免某些队列过载,而另一些队列空闲。可以采用一致性哈希算法来实现负载均衡。
- 线程管理:需要确保每个线程的稳定性和高效性,防止线程间的竞争导致性能下降。
- 内存管理:对于内存队列的管理非常重要,防止内存泄漏或内存溢出,可以采用定期清理和内存池技术来优化。
适用场景
这种方案适用于大多数需要保证单 Key 顺序性的场景,例如电商网站的订单处理系统、社交网络的消息推送系统、用户行为日志系统等。
详细实现示例
为了更好地理解这种方案,下面我们以一个用户行为日志系统为例,详细介绍如何实现单 Key 顺序消费。
1. 消息路由
在消息生产阶段,我们可以根据用户 ID 将消息路由到对应的内存队列。例如,使用一致性哈希算法来确定消息所属的内存队列:

2. 多线程消费
在消费阶段,我们可以启动多个线程,每个线程消费一个或多个内存队列:

3. 启动消费线程
最后,我们启动多个消费线程,分别消费不同的内存队列:

注意事项
- 消息堆积:如果某些 Key 的消息生产速度过快,可能会导致内存队列堆积。需要设计合理的限流和清理机制。
- 异常处理:在消费过程中,可能会遇到异常情况,需要设计合理的重试和失败处理机制。
- 系统监控:需要对系统的性能和稳定性进行监控,及时发现和解决问题。
END
通过以上介绍,我们了解了如何通过单 Key 顺序消费方案来提高系统的吞吐量,同时保证消息的顺序性。希望这些内容对大家有所帮助!
如果你有任何问题或建议,欢迎在评论区留言,咱们一起讨论!别忘了关注小米的公众号,获取更多有趣的技术分享哦!
谢谢大家,我们下次再见!
我是小米,一个喜欢分享技术的29岁程序员。如果你喜欢我的文章,欢迎关注我的微信公众号“软件求生”,获取更多技术干货!