
本文来源:支付宝体验科技公众号

我们小时候都玩过乐高积木。通过堆砌各种颜色和形状的积木,我们可以构建出城堡、飞机、甚至整个城市。现在,想象一下如果有一个数字世界的乐高,我们可以用这样的“积木”来构建智能程序,这些程序能够阅读、理解和撰写文本,甚至与我们对话。这就是大型语言模型(LLM)能够做到的,比如 GPT-4,它就像是一套庞大的乐高积木套装,等待我们来发掘和搭建。
- LangChain 概念和结构
- LangChain 实际案例:人脸技术问题的智能排查助手
- 智能体的快速发展
- 结语
- 引用
LangChain 概念和结构
LangChain 是什么?
LangChain 就是那个让我们能将这些语言模型乐高积木组合成有趣应用的工具箱。它不是一个实物,而是一个开源的软件框架,帮助开发者像搭乐高一样快速构建和优化基于语言模型的应用。
为什么需要 Langchain?
想一想,虽然我们有了乐高积木,但如果没有说明书或者构建工具,那么要搭建出一个复杂的模型将是非常困难的。同样地,即使我们有了强大的 LLM,比如 GPT-4,它们也需要“说明书”和“工具”来更好地服务于现实世界的需求。GPT-4 有无与伦比的能力去处理语言,但是它还是需要额外的组件和连接才能完全发挥潜力,比如访问最新的数据、与外部 API 互动、处理用户的上下文信息等。LangChain 就是这样一套“说明书”和“工具”,让 GPT-4 能够更好地融入到我们的应用中去。
LangChain 的乐高世界
举个例子,假设你想要用 GPT-4 建一个旅行顾问机器人。单独的 GPT-4 就像是一堆杂乱无章的乐高积木。它可能知道很多关于世界各地的信息,但如果不能实时查找最新的航班信息或者酒店价格,它提供的旅行建议可能就不够准确或实用。LangChain 就好比是提供了一本指导手册和一套辅助工具,它能让你的旅行顾问机器人链接到航班数据库,记住用户的旅行偏好,甚至根据用户以往的提问历史来提供个性化的建议。
假设你正计划一场旅行,你向智能旅行问答助手提问:“我该带些什么去泰国旅行?”如果只有 GPT-4,它可能会基于以往的数据提供一般性的建议,如防晒霜、泳衣等。但配备了 LangChain 的问答系统,它可以查询实时的天气预报 API,了解当前泰国的季节和天气情况,提供更精确的建议,比如“泰国正处于雨季,记得带上雨具和防潮包”。同样地,如果你问:“泰国哪里的垂钓体验最佳?”LangChain 可以帮助连接到最新的旅行博客和垂钓爱好者论坛,甚至直接查阅最近的旅行者评论,给你提供最受推荐的目的地。
另一个例子,如果你想要一个可以帮你总结长篇报告的工具,单用 GPT-4 可能会因文章太长而无法处理。LangChain 提供的工具就像是设计用来构建复杂构造的专用乐高积木,它可以帮你把长篇报告切分成小部分让 GPT-4 处理,再将结果整合起来,最终生成一个完整的摘要。
LangChain 主要概念
Langchain 主要提供了 6 大类组件帮助我们更好的使用大语言模型,可以视为开源版的 GPT 插件,提供了丰富的大语言模型工具,可以在开源模型基础上快速增强模型的能力。想象一下,你手中有一盒乐高积木,但这不是普通的积木,而是能够编程、交流甚至思考的智能积木。LangChain 就像是这样一盒特殊的积木盒,里面装满了不同功能的积木块,这些积木组件集成了数十种大语言模型、多样的知识库处理方法以及成熟的应用链,几十种可调用的工具箱,为用户提供了一个快速搭建和部署大语言模型智能应用程序的平台。

Models(模型)
LLMs(大型语言模型)
这些模型是 LangChain 积木盒中的基础积木。如同用乐高搭建房屋的地基,LLMs 为构建复杂的语言理解和生成任务提供了坚实的基础。
Chat Models(聊天模型)
这些模型就像是为你的乐高小人制作对话能力。它们能够让应用程序进行流畅的对话,好比是给你的乐高积木人注入了会说话的灵魂。
Text Embedding Models(文本嵌入模型)
如果说其他模型让积木能够理解和生成文本,文本嵌入模型则提供了理解文本深度含义的能力。它们就像是一种特殊的积木块,可以帮助其他积木更好地理解每个块应该放在哪里。
Prompts(提示)
Prompt Templates(提示模板)
想象一下,你正在给乐高小人编写剧本,告诉他们在不同场景下应该说什么。Prompt Templates 就是这些剧本,它们指导模型如何回答问题或者生成文本。
Indexes(索引)
LangChain 通过 Indexs 索引允许文档结构化,让LLM更直接、更有效地与文档互动。
Document Loaders(文档加载器)
这些就像是一个个小仓库,帮助你的乐高世界中的智能模型存储和访问信息。Document Loaders 能够将文档加载到系统中,方便模型快速查找。
Text Splitters(文本分割器)
有时候你需要将一大块乐高板分成几个小块来构建更复杂的结构。Text Splitters 可以将长篇文本拆分成易于处理的小块。
Vector Stores(向量存储)
这些是一种特殊的存储设施,帮助你的乐高模型记住文本的数学表示(向量)。这就像是让积木块记住它们在整个结构中的位置。
Retrievers(检索器)
想象一下你需要从一堆积木中找到一个特定的小部件。Retrievers 能够快速在向量存储中检索和提取信息,就像是乐高世界里的搜索引擎。 
Memory(记忆):对话的连贯性
LangChain 通过 Memory 工具类为 Agent 和 Chain 提供了记忆功能,让智能应用能够记住前一次的交互,比如在聊天环境中这一点尤为重要。
Chat Message History(聊天消息历史)
最常见的一种对话内容中的 Memory 类,这就好比是在你的乐高角色之间建立了一个记忆网络,使它们能够记住过去的对话,这样每次交流都能在之前的基础上继续,使得智能积木人能够在每次对话中保持连贯性。
Chains(链)
Chain、LLM Chain、Index-related Chains
CHAIN 模块整合了大型语言模型、向量数据库、记忆系统及提示,通过 Agents 的能力拓展至各种工具,形成一个能够互相合作的独立模块网络。它不仅比大模型API更加高效,还增强了模型的各种应用,诸如问答、摘要编写、表格分析和代码理解等。 
Chain 是连接不同智能积木块的基本方式,而 LLM Chain 是最简单的 LLM+Prompts 的一种 chain,专门用于链接语言模型。Index-related Chains 则将索引功能集成进来,确保信息的高效流动。

Agents(代理)
在 LangChain 的世界里,Agent 是一个智能代理,它的任务是听取你的需求(用户输入)和分析当前的情境(应用场景),然后从它的工具箱(一系列可用工具)中选择最合适的工具来执行操作。这些工具箱里装的是 LangChain 提供的各种积木,比如 Models、Prompts、Indexes 等。
如下图所示,Agent 接受一个任务,使用 LLM(大型语言模型)作为它的“大脑”或“思考工具”,通过这个大脑来决定为了达成目标需要执行什么操作。它就像是一个有战略眼光的指挥官,不仅知道战场上的每个小队能做什么,还能指挥它们完成更复杂的任务。

LangChain 中 Agent 组件的架构图如下,本质上也是基于 Chain 实现,但是它是一种特殊的 Chain,这个 Chain 是对 Action 循环调用的过程,它使用的 PromptTemplate 主要是符合 Agent Type 要求的各种思考决策模版。Agent 的核心思想在于使用 LLM 进行决策,选择一系列要执行的动作,并以此驱动应用程序的核心逻辑。通过 Toolkits 中的一组特定工具,用户可以设计特定用例的应用。

Agent 执行过程:AgentExecutor
AgentExecuter 负责迭代运行代理,直至满足设定的停止条件,这使得 Agent 能够像生物一样循环处理信息和任务。

观察(Observation)
在这个阶段,代理通过其输入接口接收外部的触发,比如用户的提问或系统发出的请求。代理对这些输入进行解析,提取关键信息作为处理的基础。观察结果通常包括用户的原始输入或预处理后的数据。
思考(Thought)
在思考阶段,代理使用预先设定的规则、知识库或者利用机器学习模型来分析观察到的信息。这个阶段的目的是确定如何响应观察到的情况。代理可能会评估不同的行动方案,预测它们的结果,并选择最合适的答案或行为。
在 LangChain 中,这个过程可能涉及以下几个子步骤:
1.理解用户意图:使用 NLP(自然语言处理)技术来理解用户的问题是什么。
2.推断所需工具:确定哪个工具(或工具组合)能解决用户的问题。
3.提取参数:提取所需工具运行的必要参数。这可能涉及文本解析、关键信息提取和验证等过程。
行动(Action)
根据思考阶段的结果,代理将执行特定的行动。行动可能是提供答案、执行任务、调用工具或者与用户进行进一步的交云。
在 LangChain 代理中,这通常涉及以下几个子步骤:
1.参数填充:将思考阶段提取的参数填入对应的工具函数中。
2.工具执行:运行工具,并获取执行结果。这可能是查询数据库、运行算法、调用 API 等。
3.响应生成:根据工具的执行结果构建代理的响应。响应可以是纯文本消息、数据、图像或其他格式。
4.输出:将生成的响应输出给用户或系统。
Agent 推理方式:AgentType
代理类型决定了代理如何使用工具、处理输入以及与用户进行交互,就像给机器人挑选不同的大脑一样,我们有很多种"智能代理"可以根据需要来选择。有的代理是为聊天模型(接收消息,输出消息)设计的,可以支持聊天历史;有的代理更适合单一任务,是为大语言模型(接收字符串,输出字符串)而设计的。而且,这些代理的能力也不尽相同:有的能记住你之前的对话(支持聊天历史),有的能同时处理多个问题(支持并行函数调用),也有的只能专心做一件事(适用于单一任务)。此外,有些代理需要我们提供一些额外信息才能更好地工作(所需模型参数),而有些则可以直接上手,不需要额外的东西。所以,根据你的需求和你所使用的模型,你可以选择最合适的代理来帮你完成任务,常见的代理类型如下:
| 智能代理类型 | 预期模型类型 | 支持聊天历史 | 支持多输入工具 | 支持并行函数调用 | 需要的模型参数 | 何时使用 | API参考 |
| OpenAI Tools | 聊天型 | ✅ | ✅ | ✅ | tools | 如果你使用的是较新的OpenAI模型(1106及以后) | Ref |
| OpenAI Functions | 聊天型 | ✅ | ✅ | functions | 如果你使用的是OpenAI模型,或者是经过微调以支持函数调用的开源模型,并且暴露与OpenAI相同的函数参数 | Ref | |
| XML | 大型语言模型 | ✅ | 如果你使用的是Anthropic模型,或者其他擅长XML的模型 | Ref | |||
| Structured Chat | 聊天型 | ✅ | ✅ | 如果你需要支持具有多个输入的工具 | Ref | ||
| JSON Chat | 聊天型 | ✅ | 如果你使用的是擅长JSON的模型 | Ref | |||
| ReAct | 大型语言模型 | ✅ | 如果你使用的是简单模型,推理观察再行动 | Ref | |||
| Self Ask With Search | 大型语言模型 | 如果你使用的是简单模型,并且只有一个搜索工具,追问+中间答案的技巧,who/when/how | Ref |
Agent 与 Chain 的关系
如果说 Chain 是 LangChain 中的基础连接方式,那么 Agent 就是更高阶的版本,它不仅可以绑定模板和 LLM,还能够根据具体情况添加或调整使用的工具。简单来说,如果 Chain 是一条直线,那么 Agent 就是能够在多个路口根据交通情况灵活选择路线的专业司机。
LangChain 实际案例:人脸技术问题的智能排查助手
使用 LangChain 处理人脸识别问题的排查
随着人脸识别服务的线上线下日调用量和应用场景快速发展,人脸识别团队正在面临一个巨大的挑战,每天反馈到团队的各种识别问题的 case 过多,排查起来费时费力,为了快速诊断问题,团队决定使用 LangChain 来构建一个智能排查助手。这个助手可以分析用户问题,错误日志,与人脸识别的 APIs 进行交互,甚至生成修复建议。
在 LangChain 框架中,工具(Tools)是用于解决特定问题的可调用的功能模块。它们可以是简单的函数,也可以是更复杂的对象,能够实现一项或多项特定任务。下面将详细介绍几种不同的工具定义及其在人脸识别问题排查过程中的应用。
首先,我们需要导入依赖的函数,主要来自各个现有日志系统的接口,能够提取比对分,黑名单,读取人脸库大小等信息:
from face_functions import ( extract_compare_scores, extract_local_group_size, extract_actual_group_size, perform_logic_judgement, search_by_exact_query, search_by_fuzzy_query, blacklist )
zmng_query 工具
当用户遇到人脸比对失败的情况时,人脸的日志系统都在 zmng 平台上,我们现在通过 zmng_query 工具提取 UID,根据 UID 查询相关的用户信息,包括他们是否在黑名单上,提取比对分数,并获取机具端及实际的人脸库大小信息,判断是什么原因识别不通过。
# 定义 zmng_query 工具的具体实现函数 def zmng_query(uid): # 实现查询 zmng 平台以获取与 uid 相关的错误详情 # 查询可能包括黑名单状态、比对分数和 groupSize # 返回查询结果 return "需要调用compare_scores_tool extract_local_group_size extract_actual_group_size blacklist_query perform_logic_judgement 这五个tool,用于问题的排查输入" # 创建 zmng_query 工具实例 zmng_query_tool = Tool( name="zmng_query", func=zmng_query, description=( "当用户刷脸比对不通过,需要确认是否为黑名单或其他原因时使用此工具。" "此工具能查询黑名单状态,提取比对分数,并获取机具端及实际的groupSize信息," "以便于准确诊断比对失败的原因。需要通过uid或zid进行查询," "这是一个9位数编码,能唯一识别一个人。使用此工具时,至少提供一个参数['uid']或['zid']。" ) )
extract_compare_scores 工具
这个工具用于从日志文件中提取比对分数,这对于诊断是人脸比对技术问题还是用户本身的问题非常关键。
compare_scores_tool = Tool( name="extract_compare_scores", func=extract_compare_scores, description=( "当用户刷脸比对不通过时,用于提取日志中的比对分数。" ) )
extract_local_group_size 和 extract_actual_group_size 工具
这两个工具分别用于提取机具端和实际的人脸库大小(groupSize)。这项信息有助于判断是否所有必要的人脸数据都已经下发到机具端。
local_group_size_tool = Tool( name="extract_local_group_size", func=extract_local_group_size, description=( "当用户刷脸比对不通过时,用于提取日志中机具端的人脸库大小groupSize。" ) ) actual_group_size_tool = Tool( name="extract_actual_group_size", func=extract_actual_group_size, description=( "当用户刷脸比对不通过时,用于提取实际的人脸库大小groupSize。" ) )
blacklist_query 工具
此工具用于查询指定用户是否在黑名单中,这是人脸识别系统中的一项常见检查。
blacklist_query_tool = Tool( name="blacklist_query", func=blacklist, description="查询指定UID是否在黑名单中。" )
perform_logic_judgement 工具
根据比对分数和本地库与实际库的大小,此工具能够给出比对不通过的分析结论。
logic_judgement_tool = Tool( name="perform_logic_judgement", func=perform_logic_judgement, description="根据比对分数和本地与实际库的大小,给出比对不通过的分析结论。" )
在 LangChain 框架中,tools 是一系列用于执行特定任务的函数或类的实例,它们可以被智能代理(Agent)调用以完成用户请求。在提供的上下文中,需要用到的 tool 已经定义好了
tools = [ compare_scores_tool, #"当用户刷脸比对不通过时,用于提取日志中的比对分数。" local_group_size_tool, #"当用户刷脸比对不通过时,用于提取日志中机具端的人脸库大小groupSize。" actual_group_size_tool, #"当用户刷脸比对不通过时,用于提取实际的人脸库大小groupSize。" blacklist_query_tool, #"查询指定UID是否在黑名单中。" zmng_query_tool ]
将所有这些工具组装到一个列表中,然后可以使用这个列表来初始化一个智能代理(Agent),该代理能够运行工具并与用户进行互动。在 LangChain 中,智能代理负责管理用户的输入,并决定调用哪个工具来处理特定的请求或问题。通过这种方式,我们可以构建一个强大的、能够解决人脸识别相关问题的智能系统。
聊天模型实例化
LangChain 使用大型语言模型(LLM)如 GPT-4 来处理自然语言的理解和生成。在这里,我们创建一个聊天模型实例,这将允许我们的代理与用户进行自然语言交互:
# LLM实例化 llm = OpenAI(temperature=0) # 聊天模型实例化 chat_model = ChatOpenAI(model="gpt-4", temperature=0)
temperature 参数控制生成文本的创造性;较低的 temperature 值(例如 0 )将导致更确定性和一致性的响应。
用户交互
一旦工具和聊天模型都被实例化,我们就可以初始化智能代理。在 LangChain 中,代理(Agent)是与用户进行交云的主体,它使用上面定义好的 tools 和 LLM 来处理用户的输入并提供响应。
# 代理初始化,结合工具和聊天模型 agent = initialize_agent(tools, chat_model, agent=AgentType.STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
现在,我们可以开始与用户的交互:
print("您好,有什么能帮助您? (输入 'exit' 结束对话)") while True: user_input = input("You: ") if user_input.lower() in "exit", "goodbye", "quit": print("再见!") break # 运行代理并获取当前用户输入的响应 response = agent.run(user_input) # 打印出代理的响应 print("Agent:", response)
在这个交互式循环中,智能代理会根据用户的输入运行相应的工具,并使用聊天模型生成自然语言响应。这使得用户可以以对话方式提出问题,并得到解答。
智能代理运行过程
在 LangChain 框架中,智能代理(Agent)通常按照观察(Observation)- 思考(Thought)- 行动(Action)的模式来处理任务。这个模型相当于一个决策循环,代理首先观察外部输入,然后进行内部思考以产生相应的行动方案。下面详细解释这个技术链路和逻辑:
#AgentExecutor的核心逻辑,伪代码: next_action = agent.get_action(...) while next_action != AgentFinish: observation = run(next_action) next_action = agent.get_action(...,next_action, observation) return next_action
#实际AgentExecutor中的部分相关代码: for agent_action in actions: if run_manager: run_manager.on_agent_action(agent_action, color="green") # Otherwise we lookup the tool if agent_action.tool in name_to_tool_map: tool = name_to_tool_map[agent_action.tool] return_direct = tool.return_direct color = color_mapping[agent_action.tool] tool_run_kwargs = self.agent.tool_run_logging_kwargs() if return_direct: tool_run_kwargs["llm_prefix"] = "" # We then call the tool on the tool input to get an observation observation = tool.run( agent_action.tool_input, verbose=self.verbose, color=color, callbacks=run_manager.get_child() if run_manager else None, **tool_run_kwargs, )
完整的技术链路示例
我们构建了一个关于人脸识别的问答智能代理,用户询问:“为什么我的脸无法被系统识别?”以下是这个代理按照 Observation-Thought-Action 模式处理此请求的过程:

利用 LangChain 与人脸问答知识库进行交互
下面这些技术模块共同构成了一个基于 LangChain 与人脸知识库进行交互的系统。
模块 1: 问题与答案数据的加载
这个模块负责读取问题和答案对,并将它们存储在一个字典结构中,以便后续检索。
def load_qa_data(filepath): qa_data = {} with open(filepath, 'r', encoding='utf-8') as file: lines = file.readlines() current_question = None answer_lines = [] # 用于累积多行答案的列表 for line in lines: if line.startswith('问题: '): if current_question: # 将之前问题的答案存储到字典中 qa_data[current_question] = ' '.join(answer_lines).strip() # 去除"问题: "部分,并去除两端空白字符 current_question = line[len('问题: '):].strip() answer_lines = [] # 为新的问题重置答案行列表 elif current_question: # 这是一个答案的一部分,可能不是第一行 answer_lines.append(line.strip()) # 不要忘记处理文件中的最后一个问题 if current_question and answer_lines: qa_data[current_question] = ' '.join(answer_lines).strip() return qa_data
模块 2: 嵌入向量的生成和 Faiss 索引创建
Faiss 是 Facebook AI Research (FAIR) 精心打造的一款强大向量数据库,专为高效执行相似性搜索和稠密向量聚类而设计。在处理大型数据集时表现尤为出色,能迅速在海量向量中锁定与查询向量最为匹配的项,极大地加速了搜索流程。无论是机器学习还是数据挖掘,Faiss 都是一个不可或缺的工具,常见的应用场景包括但不限于推荐系统、图像搜索和自然语言处理。
除了 Faiss,LangChain 支持的向量数据库范围广泛,覆盖了多种语言和平台。这些数据库包括阿里云的 OpenSearch、AnalyticDB、Annoy、Atlas、AwaDB,以及 Azure Cognitive Search、BagelDB、Cassandra、Chroma、Clarifai 等。此外,还有 ClickHouse Vector Search、Activeloop's Deep Lake、Dingo,以及各种 DocArray 搜索能力,如 DocArrayHnswSearch 和DocArrayInMemorySearch。ElasticSearch、Hologres、LanceDB、Marqo、MatchingEngine、Meilisearch、Milvus、MongoDB Atlas 和 MyScale 也在支持之列。OpenSearch 和 pg_embedding 也提供了优质的搜索服务。这些多样化的数据库选择使得 LangChain 能够在不同的环境和需求下提供灵活、高效的搜索能力。
OpenAIEmbeddings() 初始化
embeddings_model = OpenAIEmbeddings()
这一行创建了一个 OpenAIEmbeddings 实例,它是用来生成文本 embedding 的。这些 embedding 是高维向量,可以捕捉文本内容的语义信息,用于文本之间的相似性比较。
创建FAISS索引
#创建FAISS索引 def create_faiss_index(embedding_matrix): dimension = embedding_matrix.shape[1] # 获取向量的维度 index = faiss.IndexFlatL2(dimension) # 创建基于L2距离的FAISS索引 index.add(embedding_matrix.astype(np.float32)) # 向索引中添加向量 return index
create_faiss_index 函数接受一个 embedding 矩阵(通常是二维数组,其中每行是一个向量),初始化一个 FAISS 索引,并将这些向量添加到索引中。这个索引后续将用于相似性搜索。
在 FAISS 索引中搜索
def search_faiss_index(query_embedding, index): query_embedding = np.array(query_embedding).astype(np.float32) # 确保查询向量为float32类型 _, indices = index.search(np.array([query_embedding]), 1) # 在索引中搜索最相似的向量 return indices[0][0] # 返回最相似向量的索引
search_faiss_index 函数获取一个查询向量和一个 FAISS 索引作为输入,然后使用这个索引来找到与查询向量最相似的存储向量。函数返回最相似项的索引,这通常用来在一个数据库或列表中检索具体项。
模块 3: 精确匹配查询
当用户提出一个特定的问题时,这个功能会根据用户的输入在知识库中查找精确匹配的问题。
def search_by_exact_query(user_query): # 从文件加载问题和答案 qa_data = load_qa_data(filepath) # 获取答案并打印 return(get_answer(qa_data, user_query))
模块 4: 模糊匹配查询
这个模块使用嵌入向量和Faiss索引来找到与用户查询最相似的问题,并返回相应的答案。
1.初始化文本嵌入模型。2.使用文本嵌入模型将文本转换为向量。3.使用这些嵌入向量创建 FAISS 索引。4.当用户提出查询时,将查询文本也转换为嵌入向量。5.使用 FAISS 索引找到最相似的嵌入向量。
def search_by_fuzzy_query(user_query): # 从文件加载问题和答案 qa_data = load_qa_data(filepath) # Get embedding vectors for all questions and convert to numpy array questions = list(qa_data.keys()) question_embeddings_list = embeddings_model.embed_documents(questions) question_embeddings = np.array(question_embeddings_list) # Create the faiss index faiss_index = create_faiss_index(question_embeddings) # # Prompt user for a query and process user_query_embedding_list = embeddings_model.embed_documents([user_query]) user_query_embedding = np.array(user_query_embedding_list[0]) # Search the faiss index for the most similar question closest_question_index = search_faiss_index(user_query_embedding, faiss_index) closest_question = questions[closest_question_index] # Print the closest question's answer return(qa_data[closest_question])
search_by_exact 和 search_by_fuzzy 工具
在 tools 列表中,增加 search_by_exact 和 search_by_fuzzy 两个工具能力,其他逻辑不变
tools = [ Tool( name="search_by_exact", func=search_by_exact_query, description="当需要准确回答用户问题时使用此工具。使用时需提供参数['query']。如果查询为错误代码,直接查询并返回对应的错误原因和解决方法;如果观察结果显示有必要或可选发送邮件,请调用send_email工具。" ), Tool( name="search_by_fuzzy", func=search_by_fuzzy_query, description="当需要回答用户问题时使用此工具。使用时需提供参数['query']。如果查询为错误代码,直接查询并返回对应的错误原因和解决方法;如果查询非错误代码,可咨询此工具相关解决方案;如果观察结果显示有必要或可选发送邮件,请调用send_email工具。" ), send_email_tool, # Assuming definition is provided elsewhere compare_scores_tool, local_group_size_tool, actual_group_size_tool, blacklist_query_tool, zmng_query_tool ]
通过 LangChain 的灵活性和模块化,这个能够自动化处理人脸识别问题的智能排查助手,大大提高了问题诊断的效率并减轻了人工负担。
注意观察下面 agent 的 Observation Thought Action 三个阶段,agent 会自动提取出 tool 需要的参数,形成 action

智能体的快速发展
智能体的基本概念
智能体是什么?
一句话总结,Langchain 这个开发框架,是为了让我们更容易更低成本的构建大语言模型的智能应用,其中有自主行动能力,能够思考跟外部环境/工具交互的叫 Agent,智能体。
AI Agent 业界定义是具有环境感知、决策制定和行动执行能力的智能实体,并且能够通过独立思考和工具调用来逐步实现既定目标。随着大型语言模型(LLM)的出现,AI Agent 又被定义为基于 LLM 驱动的 Agent 实现对通用问题的自动化处理。当 AI Agent 被赋予一个目标时,它能独立地进行思考和行动,详细规划出完成任务所需的每一个步骤,并通过外部反馈与自我思考来创建解决问题的 prompt。例如,当要求 ChatGPT 购买咖啡时,它可能会回应“无法购买咖啡,因为它仅是一个文字型 AI 助手”。AI Agent 的关键特征包括自治性、知觉、反应能力、推理与决策能力、学习能力、通信能力以及目标导向性,这些特性使得智能体能成为真正释放 LLM 潜能的关键,它能为 LLM 核心提供强大的行动能力。
智能体的发展方向
智能体(AI Agent)的发展可谓是人工智能领域的一个重要里程碑。大语言模型不再局限于处理文本信息,它们的能力正在扩展到与世界各种软件工具的直接交互中。通过调用 APIs,这些模型现在可以获取信息、执行分析、生成报告、发送通知,甚至访问网络,访问数据库,使其功能变得无比强大。这种变化,让这些模型从单纯的文本处理者转变为真正的数字助理,能够理解用户的需求,并使用正确的工具为用户提供服务。
随着技术的发展,大语言模型使用工具能力与日俱增。早期的模型可能需要明确的、结构化的指令才能正确调用几十个工具,而现在,部分模型可以根据目标自由的调用上万个工具,并采取相应的行动。想象一下,仅通过简单的对话,你的智能代理就能为你预订餐厅、安排行程、购物,甚至编程。这种灵活性和智能度的提升,极大地增强了用户的体验。
另一个领域的进步是智能体正在从单一的智能代理到多代理系统的转变。初期,一个代理只能单一地执行任务,而现在,多个代理能够同时工作,协同完成更加复杂的任务。例如,一个代理可以负责数据收集,而另一个代理同时进行数据分析,第三个代理则负责与用户沟通结果。这些代理之间的协同工作像是一个高效的团队,每个成员都在其擅长的领域发挥作用。
同时,智能代理与人类用户之间交互也在往更自然化的方向发展,多代理系统工作过程中,可以引入人类的决策。这种人机交互的深度,使得智能代理不仅是工具的操作者,更是人类的合作者。
正是这些技术进步,塑造了我们今天所见证的智能体技术景观,大语言模型在工具使用能力上的显著提升以及智能代理的发展,为未来的可能性打下了坚实的基础。全球范围内,新兴的智能体技术如 OpenAI 的 WebGPT 为模型赋予了利用网页信息的能力,Adept 培养的 ACT-1 能独立于网站操作并使用 Excel、Salesforce 等软件,谷歌的 PaLM 项目旗下的 SayCan 和 PaLM-E 尝试将 LLM 与机器人相结合,Meta 的 Toolformer 探索使 LLM 能够自主调用 API,而普林斯顿的 Shunyu Yao 所做的 ReAct 工作则结合了思维链 prompting 技术和“手臂”概念,使 LLM 能够搜索并利用维基百科信息。随着这些技术的不断完善和创新,我们有望完成更多曾经难以想象的任务,开启智能体技术的崭新篇章。
智能体的分类

增强智能体的工具使用能力
智能代理和工具之间的关系可以类比为人类使用工具来完成任务的方式。就像人类使用锤子敲打钉子一样,代理可以调用一个 API 来获取数据、使用翻译服务来翻译文本或者执行其他功能以协助或完成它们的任务。通过增强代理的工具使用能力,它们能够执行更复杂、更精细的任务,并在更广泛的场景中提供帮助。
最近一些开源的大语言模型能够自由地与各种外部工具交互,比如 Toolformer、Gorilla、ToolLLama 等模型,它们是一类设计为优化和改进代理工具使用能力的模型,使代理更有效地与工具集成,完成任务,从而扩展 LLMs 的能力范围。
Gorilla: 
精准调用 1600+ API 的智能体进步
Gorilla 是一个基于检索感知的 LLaMA-7B 大型语言模型,也是一种基础的智能体,它能够使用各种 API 工具。这个模型通过分析自然语言查询,精准地找出并调用合适、语义语法均正确的 API,从而提升了大型语言模型执行任务的能力和准确性。
Gorilla 的一个主要特点是它能够准确地调用超过 1600 个 API,并且这个数量还在增长。这一成就展示了如何利用语言模型的理解和生成能力,来扩展其在自动化工具使用上的潜力。为了进一步提高 Gorilla 的性能,开发团队通过模拟聊天式对话,对 LLaMA-7B 模型进行了微调,让其能够更自然地与用户进行交流,并生成相应的 API 调用。
此外,Gorilla 也能够处理带有约束条件的 API 调用,这要求模型除了理解 API 的基本功能外,还必须能够识别和考虑各种参数约束。这一能力让 Gorilla 在处理特定要求的任务时显得更加智能和可靠。
在训练过程中,Gorilla 不仅在无检索器的情况下学习,还在有检索器的环境中进行训练,以提升其适应和理解不断更新的 API 文档的能力。这种训练方式使得 Gorilla 不仅能响应用户的直接指令,还能够针对检索到的相关 API 文档生成精确的调用指令,减少了错误幻觉的发生。

总的来说,Gorilla 不仅增强了语言模型在 API 调用和工具使用上的能力,还提高了处理带约束任务的复杂性,展现了智能体在自动化和人机交互方面的巨大潜力。
Gorilla-CLI:提升命令行互动体验
Gorilla-CLI 是一个由加州大学伯克利分校开发,基于 Gorilla 模型的提升命令行交互体验的工具,它通过智能化的命令预测和补全,使得命令行操作更加直观和高效。当开发者在终端中输入命令时,Gorilla-CLI 能够根据上下文提示可能的命令补全,甚至可以根据过去的操作模式预测下一步可能的命令,从而加速开发流程。https://github.com/gorilla-llm/gorilla-cli
安装步骤:
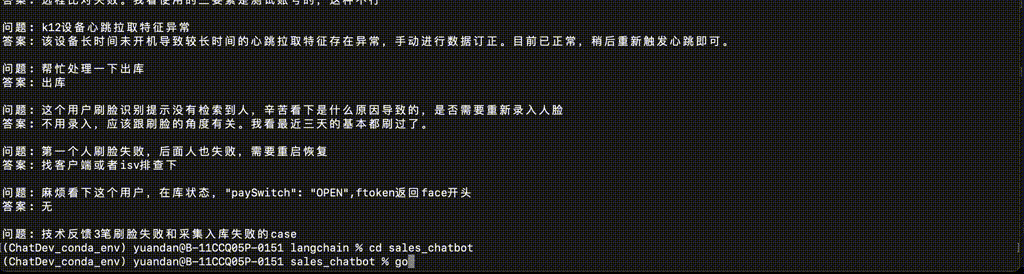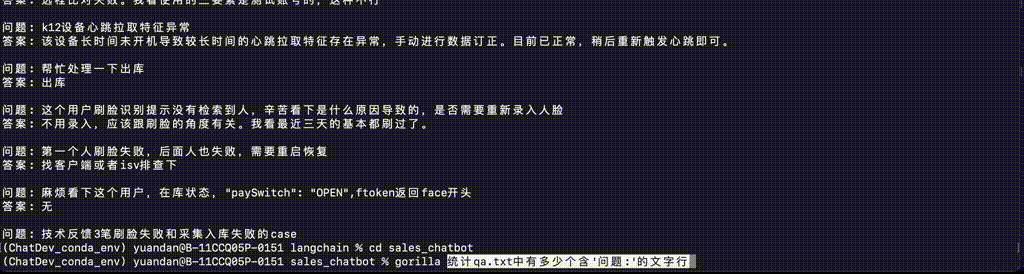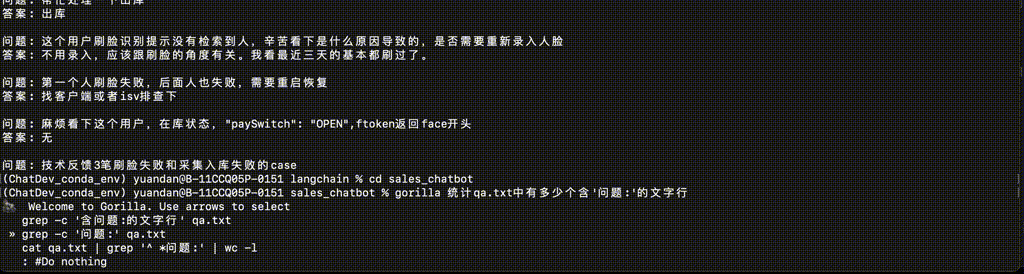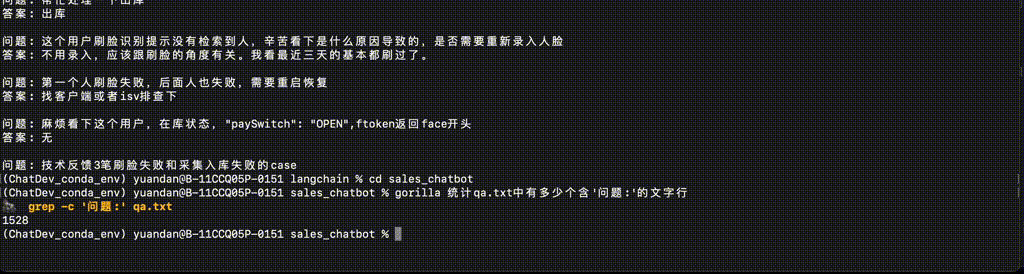
#通过pip安装Gorilla CLI pip install gorilla-cli # Gorilla命令生成示例 $ gorilla 从当前目录下找到qa.txt文件 # 命令建议: find . -name "qa.txt" # Gorilla命令生成示例 $ gorilla 统计qa.txt文件中有多少个问题? # Gorilla命令生成示例 $ gorilla 把qa.txt中的问题单独写到一个新的文件中
实验效果:

ToolLLaMa:实现 16000+ API 的精准协同调用
ToolLLaMA 也是一个基于开源 LLaMA-7B 语言模型的框架,旨在增强模型执行复杂任务的能力,特别是遵循指令使用外部工具 API。通过扩展传统 LLMs 的功能,ToolLLaMA 可以处理真实世界的应用场景,这些场景需要结合多个 API 工具来完成任务。(gorilla 5 月份刚发布, ToolLLaMa 8 月份就紧跟着发布了,卷)
ToolLLaMA 的关键特点在于支持大量的真实世界 API,共 16464 个,覆盖 49 个类别。这种丰富的 API 支持为用户提供了更多的工具选项,以满足各种应用需求。ToolLLaMA 使用 ChatGPT 生成的指令调整数据集 ToolBench,这些数据集包含单工具和多工具使用场景的指令,使得模型能够学习如何解析和执行包含多个 API 调用的指令。
为了提高在这些复杂任务中的效率,ToolLLaMA 采用了 DFSDT 算法,它是一种基于深度优先搜索的决策树,能够帮助模型在多个潜在解决方案中做出更好的选择。此算法增强了模型规划任务路径和推理的能力。
ToolLLaMA 训练了一个 API 检索器,能够为给定的用户指令推荐合适的 API,从而省去了手动筛选API的步骤,使得整个使用流程更加高效。
在性能评估方面,ToolEval 结果表明,ToolLLaMA 在执行复杂指令及泛化到未见 APIs 方面的效果与封闭源码的高级模型 ChatGPT 相似。这一发现表明,通过适当的训练方法和数据集,开源 LLMs 能够实现类似于封闭源码LLMs的工具使用能力。ToolLLaMA 项目的代码、训练模型和演示都已在 GitHub 公开,以促进社区的进一步发展和应用。
总体而言,ToolLLaMA 不仅在 API 支持数量上超越了类似 Gorilla 的模型,更在任务规划、API 检索和泛化能力上提供了新的优势,这些都是推动开源 LLMs 在复杂应用场景中应用的重要因素。https://github.com/OpenBMB/ToolBench

安装步骤:
#克隆这个仓库并导航到ToolBench文件夹。 git clone git@github.com:OpenBMB/ToolBench.git cd ToolBench #安装包(python>=3.9) pip install -r requirements.txt #或者只为ToolEval安装 pip install -r toolbench/tooleval/requirements.txt #使用我们的RapidAPI服务器进行推理 #请首先填写表单,审核后我们会发送给您toolbench密钥。然后准备您的toolbench密钥: export TOOLBENCH_KEY="your_toolbench_key" #对于ToolLLaMA,要使用ToolLLaMA进行推理,请运行以下命令: export PYTHONPATH=./ python toolbench/inference/qa_pipeline.py \ --tool_root_dir data/toolenv/tools/ \ --backbone_model toolllama \ --model_path ToolBench/ToolLLaMA-7b \ --max_observation_length 1024 \ --observ_compress_method truncate \ --method DFS_woFilter_w2 \ --input_query_file data/test_instruction/G1_instruction.json \ --output_answer_file toolllama_dfs_inference_result \ --toolbench_key $TOOLBENCH_KEY #如果想要尝试自己训练,参考下面的流程 #准备数据和工具环境: wget --no-check-certificate 'https://drive.google.com/uc?export=download&id=1XFjDxVZdUY7TXYF2yvzx3pJlS2fy78jk&confirm=yes' -O data.zip unzip data.zip 数据预处理,以G1_answer为例: export PYTHONPATH=./ python preprocess/preprocess_toolllama_data.py \ --tool_data_dir data/answer/G1_answer \ --method DFS_woFilter_w2 \ --output_file data/answer/toolllama_G1_dfs.json #训练代码基于FastChat。您可以使用以下命令使用我们的预处理数据data/toolllama_G123_dfs_train.json来训练2 x A100(80GB)的ToolLLaMA-7b的lora版本。对于预处理的细节,我们分别将G1、G2和G3数据分割成训练、评估和测试部分,并在我们的主要实验中合并训练数据进行训练: export PYTHONPATH=./ deepspeed --master_port=20001 toolbench/train/train_lora.py \ --model_name_or_path huggyllama/llama-7b \ --data_path data/toolllama_G123_dfs_train.json \ --eval_data_path data/toolllama_G123_dfs_eval.json \ --conv_template tool-llama-single-round \ --bf16 True \ --output_dir toolllama_lora \ --num_train_epochs 5 \ --per_device_train_batch_size 4 \ --per_device_eval_batch_size 2 \ --gradient_accumulation_steps 2 \ --evaluation_strategy "epoch" \ --prediction_loss_only \ --save_strategy "epoch" \ --save_total_limit 8 \ --learning_rate 5e-5 \ --weight_decay 0. \ --warmup_ratio 0.04 \ --lr_scheduler_type "cosine" \ --logging_steps 1 \ --source_model_max_length 2048 \ --model_max_length 8192 \ --gradient_checkpointing True \ --lazy_preprocess True \ --deepspeed ds_configs/stage2.json \ --report_to none
实验效果:
如果你正在计划一个给最好朋友的惊喜派对,并希望为每位参加聚会的人提供一些鼓舞人心的话语,那么可以使用 toolLLama 这样的语言模型,它能够让你轻松地调用一个工具来生成或查找各种名人的励志名言,特别是关于爱情、梦想和成功的话语。例如,其中一个例子返回了:“成功不是终点,失败也不是致命的:真正重要的是继续前进的勇气。”--丘吉尔

智能体的发展:从单任务到多代理协同与人代理交互
随着人工智能技术的不断进化,我们见证了智能体(AI Agent)的发展:从只能执行单一任务的简单代理,到如今能够进行多代理协同与人类代理交互的复杂系统。这种进步不仅拓宽了智能应用的边界,使其能够在更加复杂的环境中同时处理多种任务,还提升了与用户合作的能力,共同做出更加精细化的决策。
我们正步入一个新纪元,其中最新的开源大型语言模型(LLMs)能够自由地与多样化的外部工具交互,完成更加丰富和复杂的任务。这不仅推动了AI技术的民主化,还为社区驱动的创新和发展打开了新的大门。
尽管 LLMs 的智能和精准的提示输入提供了巨大优势,但有效利用这些模型仍然需要用户掌握相应的技巧,这已导致培训市场的出现。然而,prompt 工程的复杂性也对普通用户的体验造成了挑战。AI 智能体,作为能够感知环境、做出决策和执行动作的独立实体,可能是解决这一挑战的关键。AI 智能体不仅能够自主完成任务,也能够主动与环境交互。随着 LLMs 的发展,AI 智能体为这些模型提供了实际行动力,不仅仅是作为工具,而是作为能够自动化处理通用问题的智能实体。通过释放 LLMs 的潜能,AI 智能体将成为未来技术的关键驱动力。例如,AutoGPT 将复杂任务分解为更易管理的子任务,并生成相应的提示(prompts)。MetaGPT 将高级人类流程管理经验编码到智能体的提示中,促进了多智能体之间的结构化合作。ChatDev 受到软件开发的经典瀑布模型的启发,通过模拟一个虚拟软件公司的环境,展示了智能体在专业功能研讨会中的合作潜力。在这个环境中,多个智能体扮演不同的角色,遵循开发流程,通过聊天进行协作。
MetaGPT
MetaGPT 是由 Deep Wisdom 联合几个大学发布的一个基于大型语言模型(LLMs)专门为高效整合人类工作流程而设计的多智能体合作框架。通过将标准化操作程序(SOPs)编码到智能体的提示序列中, MetaGPT 简化了工作流程,使智能体能够以类似于人类专家的方式来校验中间成果,这有助于减少错误的发生。
在 MetaGPT 系统中,智能体根据装配线原则被分配不同的角色,以协同完成复杂任务。任务被分解为多个子任务,每个子任务由相应的智能体负责。这种方法不仅提高了任务执行的一致性,还提升了解决方案的质量。例如,在软件工程的协作任务中,MetaGPT 展现出了相较于传统基于聊天的多智能体系统更一致的解决方案生成能力。
广泛接受的 SOPs 在任务分解和有效协调中扮演了关键角色,尤其是在确定团队成员职责和中间产物标准方面。在软件开发领域,产品经理通常依据 SOP 来创建产品需求文档(PRD),这有助于指导整个开发过程。
MetaGPT 框架吸取了 SOPs 的重要经验,并允许智能体生成结构化且高质量的需求文档、设计文档、流程图和界面规格。这种结构化的中间输出能够显著提升目标代码生成的成功率。MetaGPT 模拟了一个高度规范化的公司流程环境,在这个环境中,所有智能体必须严格遵守已确立的标准和工作流程。在角色扮演构架中,智能体被分配了各种各样的角色,以高效协同工作、分解复杂任务。这种角色扮演的设计有助于减少无效交流,并降低大模型幻觉风险。
MetaGPT 通过"编程促进编程"(programming to program)的方法,提供了一个有前景的元编程框架。智能体不仅是代码的执行者,还主动参与到需求分析、系统设计、代码生成-修改-执行、以及运行时调试的全过程。每个智能体都拥有特定的角色和专业知识,并遵循既定的标准。如此一来,MetaGPT 成为了一种独特的解决方案,在自动化编程任务中展现出巨大的潜力,并推动了元编程的高效实现。

MetaGPT 接受单行需求作为输入,并输出用户故事、竞争分析、需求、数据结构、API、文档等。在内部,MetaGPT 包括产品经理、架构师、项目经理和工程师。它提供了一个软件公司的整个流程,以及精心编排的标准操作程序(SOP)。代码 = SOP (团队) 是其核心理念。我们将 SOP 具体化,并将其应用到由大型语言模型(LLMs)组成的团队中。

在通信协议中,智能体通过共享消息池发布和订阅结构化消息,以此来协调工作和交换信息。这允许智能体根据自己的角色和任务需求,获取相关信息并执行任务。

MetaGPT 中的工程师智能体可以生成代码,运行代码检查错误。如果遇到错误,智能体会查阅存储在记忆中的消息,并将它们与产品需求文档、系统设计和代码文件进行对比,以识别问题并进行修正。这一过程涉及迭代编程和可执行反馈,使得智能体可以不断优化其解决方案。
整个软件开发过程图强调了 MetaGPT 对 SOPs 的依赖性。这些 SOPs 规定了从项目开始到完成的每一步,确保智能体可以高效、系统地完成任务。

MetaGPT 实验流程
安装步骤:
#步骤1:确保您的系统上安装了Python 3.9或更高版本。您可以使用以下命令来检查: #您可以使用conda来初始化一个新的python环境 conda create -n metagpt python=3.9 conda activate metagpt python3 --version #步骤2:克隆仓库到您的本地机器以获取最新版本,并进行安装。 git clone https://github.com/geekan/MetaGPT.git cd MetaGPT pip3 install -e . # 或者 pip3 install metagpt # 用于稳定版本 #步骤3:设置您的OPENAI_API_KEY,或确保它已经存在于环境变量中 mkdir ~/.metagpt cp config/config.yaml ~/.metagpt/config.yaml vim ~/.metagpt/config.yaml #步骤4:运行metagpt命令行工具 metagpt "Create a 2048 game in python" #步骤5 [可选]:如果您想要保存工作区中的产物,如象限图、系统设计、序列流程图等,可以在执行步骤3之前执行此步骤。默认情况下,框架是兼容的,整个过程可以完全不执行此步骤而运行。 如果执行,请确保您的系统上安装了NPM。然后安装mermaid-js。(如果您的计算机中没有npm,请前往Node.js官方网站安装Node.js https://nodejs.org/,然后您的计算机中将有npm工具。) npm --version sudo npm install -g @mermaid-js/mermaid-cli
运行过程:

实验效果:

ChatDev
ChatDev 是 OpenBMB 联合清华大学 NLP 实验室共同开发的大模型全流程自动化软件开发框架,它模拟了一家虚拟软件公司,由担任不同职能的多个智能代理运作,包括首席执行官(CEO)、首席产品官(CPO)、首席技术官(CTO)、程序员、审查员、测试员和设计师。这些智能代理构成了一个多代理组织架构,并共同致力于一个使命:"通过编程革新数字世界。" 在 ChatDev 中,代理们通过聊天参与研讨会协作,涵盖设计、编码、测试以及文档撰写等多种专业任务。
ChatDev 的主要目标是提供一个易于使用、高度可定制和可扩展的框架,该框架基于大型语言模型(LLMs),旨在成为研究集体智能的理想场景。https://github.com/OpenBMB/ChatDev

ChatDev 通过模拟软件开发的瀑布模型,实现了智能的分阶段、分聊天的协作。每个阶段包含多个原子聊天,而在每个聊天中,两个扮演不同角色的智能体通过任务导向的对话来协同完成子任务。这个流程不仅包括了智能体之间基于指令的互动,还包括了角色专业化、记忆流、自省等机制,以确保智能体能够高效、准确地执行任务,并持续优化决策过程。

角色专业化使每个智能体都能在对话中有效地扮演其指定的角色,比如程序员、审查员等。记忆流记录了聊天中的对话历史,使智能体在做决策时有足够的上下文信息。自省机制则是在达成共识的情况下,让智能体反思并验证决策,确保没有违反终止条件。

在编码和测试阶段,为了减少代码幻觉——即智能体生成与现有代码库不一致的代码——ChatDev 引入了思维指令机制。智能体通过角色交换,明确询问或解释代码中的具体问题,这样可以更精确地定位问题所在,并通过更具体的指令指导程序员修复问题。这种机制加强了智能体对代码的理解,提高了编程和测试的准确性。

ChatDev 实验流程
安装步骤:
克隆GitHub仓库:使用以下命令开始克隆仓库: git clone https://github.com/OpenBMB/ChatDev.git 设置Python环境:确保你有一个3.9或更高版本的Python环境。你可以使用以下命令创建并激活这个环境,将ChatDev_conda_env替换为你喜欢的环境名称: conda create -n ChatDev_conda_env python=3.9 -y conda activate ChatDev_conda_env 安装依赖项:移动到ChatDev目录,并通过运行以下命令安装必需的依赖项: cd ChatDev pip3 install -r requirements.txt 设置OpenAI API密钥:将你的OpenAI API密钥作为环境变量导出。将"your_OpenAI_API_key"替换为你实际的API密钥。记住,这个环境变量是会话特定的,所以如果你打开一个新的终端会话,你需要再次设置它。在Unix/Linux系统上: export OPENAI_API_KEY="your_OpenAI_API_key" 构建你的软件:使用以下命令开始构建你的软件,将[description_of_your_idea]替换为你的想法描述,将[project_name]替换为你想要的项目名称:在Unix/Linux系统上: python3 run.py --task "[description_of_your_idea]" --name "[project_name]" 运行你的软件:一旦生成,你可以在WareHouse目录下的特定项目文件夹中找到你的软件,例如project_name_DefaultOrganization_timestamp。在该目录下使用以下命令运行你的软件:在Unix/Linux系统上: cd WareHouse/project_name_DefaultOrganization_timestamp python3 main.py
# 安装完成后,我们创建了一个字谜游戏: python3 run.py --task "创建一个猜英文字谜的游戏" --name 'puzzle' # 可视化智能代理对游戏的生成过程: python3 visualizer/app.py
运行过程:

ChatDev 包含一个仓库(warehouse)目录,上面的命令会先在该目录下创建一个名为 puzzle 的项目目录。
游戏效果

可视化游戏生成过程:
ChatDev 中,项目的创建和开发过程涉及多个团队成员或"角色"之间的协作,他们通过对话的方式来生成语言模型的 prompts,促进项目的进展。团队成员通过聊天界面编写代码、讨论问题、想法和解决方案。这个项目的创建过程可以通过visualizer进行回放。

MetaGPT 和 ChatDev 的异同
MetaGPT 和 ChatDev 都支持自动化软件开发,但在架构设计、技术实现、支持功能等方面存在一些差异。
| 功能特点 | MetaGPT | ChatDev |
| 流程标准化 | 标准化操作程序 | 聊天链 |
| 任务解决模式 | 按指令操作 | 智能体间通信 |
| 架构设计 | 系统接口 | —① |
| 缓解代码幻觉 | — | 思维指令 |
| 艺术设计 | — | 文字到图片设计师 |
| 记忆 | 上下文检索 | 短时记忆共享 |
| 消息共享 | 智能体层面广播 | 阶段层面传递 |
| 版本管理 | — | Git |
| 自动化测试 | —② | 解释器反馈 |
| 自然语言文档 | 产品需求文档 | 用户手册 |
①MetaGPT 通过序列流程显式设计架构;而 ChatDev 的架构设计是通过生成性基础模型隐式实现的。
②截至 2023 年 9 月 19 日,MetaGPT 的官方代码库目前不支持软件开发的自动化测试。
各种智能体在快速发展

全球范围内,多个AI智能体产品如 AiAgent.app 和 GPT Researcher 已被推出,并在媒体报道、行业分析、研究助理等领域获得成功应用。这些智能体设计得足够灵活,能够调用软件应用和硬件设备,大大提升了工作效率和便利性。尽管AI智能体的发展时间短暂,它们迅速在各行业中得到认可。随着大型语言模型(LLMs)的多模态能力和计算力的增强,早年提出的智能体理念得以迅速实现,并广泛应用于多个领域。各种开源AI智能体的出现,加速了技术供应商和创业团队引入智能体的步伐,并帮助更多组织认识到并接受了AI智能体的概念,这可能成为 LLMs 落地的主要模式,并助力多个行业更好地利用 LLMs。
结语
LangChain 为大型语言模型提供了一种全新的搭建和集成方式,正如乐高积木提供了无尽的创造可能。通过这个强大的框架,我们可以将复杂的技术任务简化,让创意和创新更加易于实现。在第一篇的内容中,我们穿越了 LangChain 的世界,体验了如同搭建乐高积木般构建语言模型应用的乐趣。从 LangChain 的核心概念到其在现实世界中人脸问题的智能排查应用,我们见证了这一框架如何助力智能体的创新与成长。
在第二篇的内容中,我们讨论了智能体的发展,目前主要呈现两大方向。首先,我们看到了诸如 Gorilla 和 ToolLLaMa 这样的进步,它们通过增强大型语言模型(LLMs)本身的工具使用能力,为我们带来直观、高效的互动体验。这些工具的发展将大语言模型的潜力发挥到极致,为智能体提供了更为强大的支持功能。
另一方向是多代理协同,像 MetaGPT 和 ChatDev 这样的系统展示了通过多智能体的合作可以如何高效解决问题。这种多代理模式模拟了人类团队工作的方式,每个智能体扮演特定的角色,共同完成任务。这不仅提高了任务执行的效率,也开启了智能代理未来无限的可能性。
随着技术的不断进化,智能代理正在从单一任务执行者转变为能够协同工作的团队成员。这一转变不仅扩大了智能体在各行各业中的应用范围,也为未来出现的人与智能体之间的互动提供了基础。让我们携手前进,共同迎接智能体技术带来的充满惊喜的新时代。
引用
- https://arxiv.org/pdf/2305.15334.pdfGorilla: Large Language Model Connected with Massive APIs
- https://arxiv.org/abs/2312.17025ChatDev: Communicative Agents for Software Development
- https://arxiv.org/abs/2307.16789ToolLLM: Facilitating Large Language Models to Master
- https://arxiv.org/abs/2308.00352MetaGPT: Meta Programming for A Multi-Agent
- https://www.sohu.com/a/723783296_116132,全球 AI Agent 大盘点,大语言模型创业一定要参考的 60 个 AI 智能体
- https://36kr.com/p/2203231346847113, LangChain:Model as a Service 粘合剂,被 ChatGPT 插件干掉了吗?



