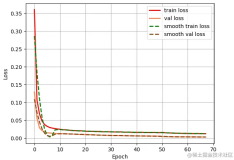
YOLOv3中的非极大值抑制(Non-Maximum Suppression, NMS)是一种关键的后处理步骤,用于从模型的预测中去除重叠的边界框,从而提高检测的准确性。NMS参数的调整直接影响到模型的准确率(Precision)和召回率(Recall),具体如下:
1. NMS阈值(`nms_thresh`):
- 提高NMS阈值:会减少被抑制的边界框数量,从而保留更多的边界框。这可能会提高召回率,因为更多的真实目标被保留,但同时也可能降低准确率,因为更多的误检(非目标)也被保留。
- 降低NMS阈值:会使得更多的边界框被抑制,特别是那些重叠度较高的框。这可能会提高准确率,因为更多的误检被去除,但同时可能会降低召回率,因为一些真实目标可能因为与其他目标重叠而被错误地抑制。
2. 置信度阈值(`conf_thresh`):
- 在NMS之前,所有置信度低于`conf_thresh`的边界框会被丢弃。提高这个阈值会减少NMS处理的框的数量,可能会提高准确率,因为置信度低的框通常意味着它们更可能是误检,但这也可能会降低召回率。
- 降低这个阈值会让更多的边界框进入NMS阶段,可能会提高召回率,但可能会降低准确率。
3. IoU计算方式:
- 使用不同的IoU计算方式(如DIoU或CIoU)可能会改善模型在特定情况下的性能,如遮挡目标的检测。这些改进的IoU计算方式可以更精确地衡量边界框之间的重叠,从而在NMS过程中做出更好的决策。
4. 类别得分:
- 在某些实现中,类别得分可以与置信度结合使用来调整NMS的行为。对于某些类别,可能需要更严格的NMS阈值来提高检测质量。
5. 软NMS(Soft-NMS):
- 与传统NMS相比,软NMS会降低重叠框的得分,而不是完全移除它们。这种方法可以提高召回率,同时保持一定的准确率。
6. 动态NMS:
- 动态调整NMS阈值可以根据目标的密度来优化检测性能,在目标密集区域使用更高的阈值,而在稀疏区域使用较低的阈值。
调整NMS参数是一个平衡准确率和召回率的过程,通常需要通过实验来找到最佳的参数设置。在实际应用中,根据项目的具体需求,可能会更关注准确率或召回率中的一个。例如,在一些对误检非常敏感的应用中,可能会倾向于提高准确率;而在其他一些需要尽可能检测出所有目标的应用中,则可能会更关注召回率。