
也可以把多进程放在函数里,用main函数来运行。
from multiprocessing import Process def task(arg): pass def run(): p = Process(target=task, args=(‘xxx’, )) p.start() if name == ‘__main__’: run()
在python中基于multiprocessing模块操作的进程,start methods主要有三种: 1. fork:可以拷贝几乎所有资源,支持文件对象/线程锁等传参,unix系统适用,任意位置开始; 2. spwan:run参数必备资源,不支持文件对象/线程锁等传参,unix、win适用,main代码模块开始; 3. forkserver:run参数必备资源,不支持文件对象/线程锁等传参,部分unix适用,main代码模块开始。 ### (二)案例 #### 1、示例一:fork模式下复制列表元素到子进程中 先创建一个子进程,然后设置模式为fork,我们可以运行一下子进程,看看线程里的name长什么样,实验结果显示,主线程的name被复制到子进程里。
import multiprocessing def task(): print(name) if name == ‘__main__’: multiprocessing.set_start_method(“fork”) #fork、spawn、forkserver name = []
p1 = multiprocessing.Process(target=task) p1.start()
#[]
在子进程里面修改name,增加列表元素,在子进程和主进程里分别打印name观察,可以发现:进程中改变的name并不会影响主进程中的name。
import multiprocessing import time def task(): print(name) #[] name.append(123) print(name) #[123] if name == ‘__main__’: multiprocessing.set_start_method(“fork”) #fork、spawn、forkserver name = []
p1 = multiprocessing.Process(target=task) p1.start() time.sleep(2) print(name) #[]
但是如果append操作放在主线程里,那么经过append操作的name会被复制到进程中,在子进程中打印name可以发现是多了123元素的列表。
import multiprocessing import time def task(): print(name) #[123] if name == ‘__main__’: multiprocessing.set_start_method(“fork”) #fork、spawn、forkserver name = [] name.append(123)
p1 = multiprocessing.Process(target=task) p1.start()
#### 2、示例二:spawn模式下复制列表元素到子进程中 切换到spawn模式后,我们可以发现在spawn模式下,name并不能直接复制到进程中,会报错,所以只能当作参数传入到task中。
import multiprocessing import time def task(data): print(data) #[] if name == ‘__main__’: multiprocessing.set_start_method(“spawn”) #fork、spawn、forkserver name = []
p1 = multiprocessing.Process(target=task, args=(name, )) p1.start()
同样的,在子进程中对name进行append操作,结果发现子进程中的改变并不会影响主进程中的name。
import multiprocessing import time def task(data): print(data) #[] data.append(999) print(data) #[999] if name == ‘__main__’: multiprocessing.set_start_method(“spawn”) #fork、spawn、forkserver name = []
p1 = multiprocessing.Process(target=task, args=(name, )) p1.start() time.sleep(2) print(name) #[]
#### 3、示例三:在fork模式下复制文件对象到子进程中 spawn并不支持特殊对象:文件或锁的传参,而且即使是普通对象也只能通过传参的形式进行传递。
import multiprocessing import time def task(): print(name) #[] file_object.write(‘闫曦月\n’) file_object.flush() #高宇星和闫曦月这两个内容已经刷到硬盘中了 if name == ‘__main__’: multiprocessing.set_start_method(“fork”) #fork、spawn、forkserver name = [] file_object = open(‘x1.txt’, mode=‘a+’, encoding=‘utf-8’) file_object.write(‘高宇星\n’) #写入到内存中,内容还没有写到文件里,在子进程运行完之后才会将该内容刷到硬盘上
p1 = multiprocessing.Process(target=task) p1.start()
txt的内容是: 高宇星 闫曦月 高宇星 在本案例中,我们创建了一个txt文件,并将高宇星复制到子进程中,子进程在flush的时候把两个数据都写到了硬盘中,最后等子进程运行完之后,主进程再次将高宇星这条数据刷到硬盘中。
import multiprocessing import time def task(): print(name) #[] file_object.write(‘闫曦月\n’) file_object.flush() if name == ‘__main__’: multiprocessing.set_start_method(“fork”) #fork、spawn、forkserver name = [] file_object = open(‘x1.txt’, mode=‘a+’, encoding=‘utf-8’) file_object.write(‘高宇星\n’) file_object.flush()
p1 = multiprocessing.Process(target=task) p1.start()
txt的内容是: 高宇星 闫曦月 这里有不同点,是在主进程里,已经进行了flush,所以已经将内存中的信息高宇星刷到硬盘上了,所以在子进程运行结束之后就不会再刷高宇星到硬盘上了。 #### 4、示例四:在fork模式下复制锁到子进程中 spawn模式下,锁没有办法被传参。
import multiprocessing import threading def task(): print(file_object, lock) #<_io.TextIOWrapper name=‘x1.txt’ mode=‘a+’ encoding=‘utf-8’> if name == ‘__main__’: multiprocessing.set_start_method(“fork”) #fork、spawn、forkserver name = [] file_object = open(‘x1.txt’, mode=‘a+’, encoding=‘utf-8’) lock = threading.RLock()
p1 = multiprocessing.Process(target=task) p1.start()
当我们在主进程中申请了锁之后,主进程中打印出来的锁是已经进行locked过的。
import multiprocessing import threading def task(): pass if name == ‘__main__’: multiprocessing.set_start_method(“fork”) #fork、spawn、forkserver name = [] lock = threading.RLock() print(lock) # lock.acquire() print(lock) # lock.release() print(lock) # lock.acquire() print(lock) #
p1 = multiprocessing.Process(target=task) p1.start()
当我们在主进程中申请了锁之后,子进程中打印出来的锁是已经进行locked过的,是子进程的主线程锁的。
import multiprocessing import threading def task(): #拷贝的锁也是申请走的状态,被谁申请走了?被子进程中的主线程申请走了 print(lock) # lock.acquire() print(666) if name == ‘__main__’: multiprocessing.set_start_method(“fork”) #fork、spawn、forkserver name = [] lock = threading.RLock() # lock.acquire()
p1 = multiprocessing.Process(target=task) p1.start()
锁被子进程中的主线程申请走了,所以在子进程中如果创立其他线程的话,其他线程是获取不到锁的,所以程序代码都会卡住,只有将子线程中将主线程的锁进行释放,子进程中其他子线程才会获取到锁并执行下去。
import multiprocessing import threading import time def func(): print(“来了”)
with lock: print(666) time.sleep(1)
def task(): for i in range(10): t = threading.Thread(target=func) t.start() if name == ‘__main__’: multiprocessing.set_start_method(“fork”) #fork、spawn、forkserver name = [] lock = threading.RLock() # lock.acquire()
p1 = multiprocessing.Process(target=task) p1.start()
‘’’ 来了 来了 来了 来了 来了 来了 来了 来了 来了 来了 ‘’’ #程序卡住了,运行不下去
将子线程中的主线程里的lock锁进行释放后,子线程可以正常执行代码。
import multiprocessing import threading import time def func(): print(“来了”)
with lock: print(666) time.sleep(1)
def task(): for i in range(10): t = threading.Thread(target=func) t.start() time.sleep(1) lock.release() if name == ‘__main__’: multiprocessing.set_start_method(“fork”) #fork、spawn、forkserver name = [] lock = threading.RLock() # lock.acquire()
p1 = multiprocessing.Process(target=task) p1.start()
‘’’ 来了 来了 来了 来了 来了 来了 来了 来了 来了 来了 666 666 666 666 666 666 666 666 666 666 ‘’’
### (三)常见功能 #### 1、p.start() 当前进程准备就绪,等待被CPU调度(工作单元其实就是进程中的线程) #### 2、p.join() 等待当前进程的任务执行完毕后再向下继续执行
import multiprocessing from multiprocessing import Process import threading import time def task(arg): time.sleep(2) print(“执行中。。。”) if name == ‘__main__’: multiprocessing.set_start_method(“spawn”) #fork、spawn、forkserver p = Process(target=task, args=(‘xxx’, )) p.start() p.join()
print("继续执行。。。")
‘’’ 执行中。。。 继续执行。。。 ‘’’
#### 3、p.daemon() 是布尔值,守护进程(必须放在start之前) p.daemon = True :设置为守护进程,主进程执行完之后,子进程也自动关闭。 p.daemon = False :设置为非守护进程,主进程等待子进程,子进程执行完之后,主进程才结束。
import multiprocessing from multiprocessing import Process import threading import time def task(arg): time.sleep(2) print(“执行中。。。”) if name == ‘__main__’: multiprocessing.set_start_method(“spawn”) #fork、spawn、forkserver p = Process(target=task, args=(‘xxx’, )) p.daemon = True p.start()
print("继续执行。。。")
‘’’ 继续执行。。。 ‘’’
上述代码在执行完主进程之后就自动关闭了,子进程并没有得到执行。 #### 4、进程名称的设置和获取
import multiprocessing from multiprocessing import Process import threading import time def task(arg): time.sleep(2) print(“当前进程的名称:”, multiprocessing.current_process().name) if name == ‘__main__’: multiprocessing.set_start_method(“spawn”) #fork、spawn、forkserver p = Process(target=task, args=(‘xxx’, )) p.name = ‘new bee’ p.daemon = False p.start()
print("继续执行。。。")
‘’’ 继续执行。。。 当前进程的名称: new bee ‘’’
#### 5、自定义进程类 将进程定义为类,直接僵线程需要做的事儿写到run方法中
import multiprocessing class MyProcess(multiprocessing.Process): def run(self): print(‘执行此进程’, self._args) if name == ‘__main__’: multiprocessing.set_start_method(‘spawn’) p = MyProcess(args=(‘xxx’, )) p.start() print(“继续执行”) ‘’’ 继续执行 执行此进程 (‘xxx’,) ‘’’
#### 6、获取进程和子进程id号
import multiprocessing from multiprocessing import Process import threading import time import os def func(): time.sleep(1) def task(arg): for i in range(10): t = threading.Thread(target=func) t.start() #time.sleep(2) print(os.getpid(), os.getppid()) print(“当前进程的名称:”, multiprocessing.current_process().name) print(len(threading.enumerate())) #获取线程个数 #11 if name == ‘__main__’: print(os.getpid()) multiprocessing.set_start_method(“spawn”) #fork、spawn、forkserver p = Process(target=task, args=(‘xxx’, )) p.name = ‘new bee’ p.daemon = False p.start()
print("继续执行。。。")
‘’’ 8517 主进程id号 继续执行。。。 当前进程的名称: new bee 8558 子进程id号 8554 副进程id号 11 ‘’’
#### 7、cpu的个数 为了利用cpu多核优势,一般需要看看有多少个cpu,定义相同数量的进程
import multiprocessing print(multiprocessing.cpu_count()) #4
## 二、进程间数据的共享 进程是资源分配的最小单元,每个进程中都维护自己独立的数据,不共享。如果想要进程之间的数据进行共享,可以借助一些中介来实现。 当我们在子进程中修改列表数据时,主进程中的列表数据并没有发生变化,说明主进程和子进程之间是割裂的,数据并不共享。
import multiprocessing def task(data): data.append(666) print(data) #[666] if name == “__main__”: data_list = [] p = multiprocessing.Process(target=task, args=(data_list,)) p.start() p.join()
print("主进程:", data_list) #主进程: []
### (一)共享 #### 1、share memory: Value / Array 通过Value和Array在子进程中更改元素的变量值,改变后的值同样也能共享到主进程中 字母所代表的含义: 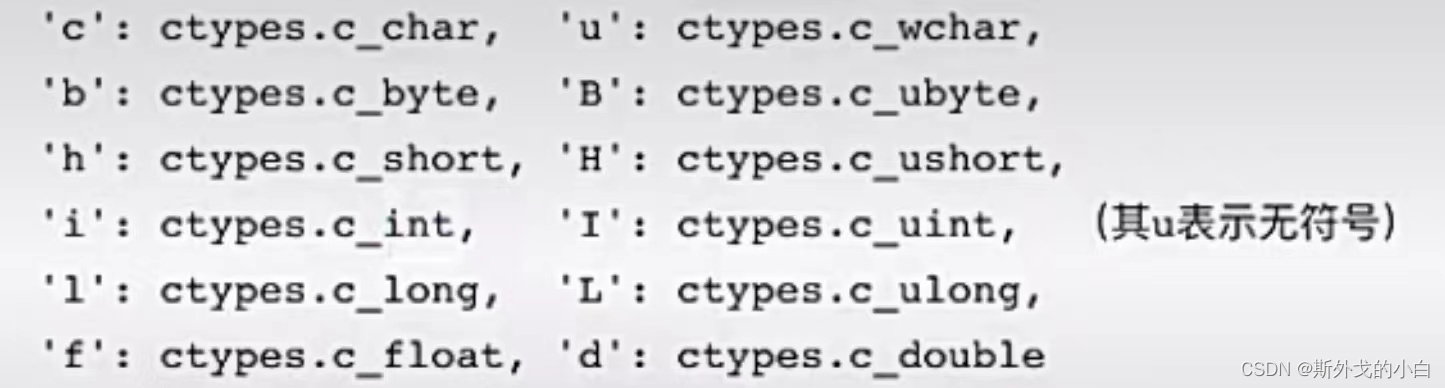
from multiprocessing import Process, Value, Array def func(n, m1, m2): n.value = 888 m1.value = ‘a’.encode(‘utf-8’) m2.value = “武” if name == ‘__main__’: num = Value(‘i’, 666) v1 = Value(‘c’) v2 = Value(‘u’)
p = Process(target=func, args=(num, v1, v2)) p.start() p.join() print(num.value) #888 print(v1.value) #a print(v2.value) #武
Array可以更改数组的元素值
from multiprocessing import Process, Value, Array def func(data_array): data_array[0] = 666 if name == ‘__main__’: arr = Array(‘i’, [11, 22, 33, 44, 55, 66]) #数组:元素类型必须是int
p = Process(target=func, args=(arr, )) p.start() p.join() print(arr[:]) #[666, 22, 33, 44, 55, 66]
#### 2、Manager() 通过Manager来更改列表、字典的值
from multiprocessing import Process, Manager def func(d, l): d[‘高宇星’] = ‘18岁’ d[‘闫曦月’] = ‘68岁’ d[0.25] = None l.append(666) if name == ‘__main__’: with Manager() as manager: d = manager.dict() l = manager.list()
p = Process(target=func, args=(d, l)) p.start() p.join() print(d) #{'高宇星': '18岁', '闫曦月': '68岁', 0.25: None} print(l) #[666]
### (二)交换 #### 1、Queue 通过Queue将数据进行排队处理 
import multiprocessing def task(q): for i in range(10): q.put(i)
最后
Python崛起并且风靡,因为优点多、应用领域广、被大牛们认可。学习 Python 门槛很低,但它的晋级路线很多,通过它你能进入机器学习、数据挖掘、大数据,CS等更加高级的领域。Python可以做网络应用,可以做科学计算,数据分析,可以做网络爬虫,可以做机器学习、自然语言处理、可以写游戏、可以做桌面应用…Python可以做的很多,你需要学好基础,再选择明确的方向。这里给大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
👉Python所有方向的学习路线👈
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

👉Python必备开发工具👈
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

👉Python全套学习视频👈
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。

👉实战案例👈
学python就与学数学一样,是不能只看书不做题的,直接看步骤和答案会让人误以为自己全都掌握了,但是碰到生题的时候还是会一筹莫展。
因此在学习python的过程中一定要记得多动手写代码,教程只需要看一两遍即可。

👉大厂面试真题👈
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。

