是的,Hadoop是一个分布式计算框架,它包含了大量的参数,这些参数允许用户根据他们的具体需求和环境来配置Hadoop集群。这些参数覆盖了Hadoop生态系统中的多个组件,如HDFS(Hadoop Distributed FileSystem)、MapReduce、YARN(Yet Another Resource Negotiator)等。
以下是一些常见的Hadoop配置参数及其用途的简要概述:
HDFS相关参数
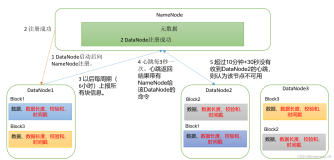
dfs.replication:数据块的默认副本数。dfs.blocksize:HDFS中文件块的大小。dfs.namenode.name.dir:NameNode存储元数据(fsimage和edits)的本地文件系统目录。dfs.datanode.data.dir:DataNode存储数据块的本地文件系统目录。
MapReduce相关参数
mapred.map.tasks:每个作业的最大映射任务数。mapred.reduce.tasks:每个作业的最大归约任务数。mapred.tasktracker.map.tasks.maximum:每个TaskTracker上同时运行的最大映射任务数。mapred.tasktracker.reduce.tasks.maximum:每个TaskTracker上同时运行的最大归约任务数。
YARN相关参数
yarn.nodemanager.resource.memory-mb:NodeManager上可用的物理内存总量,以MB为单位。yarn.scheduler.minimum-allocation-mb:每个容器请求的最小内存量,以MB为单位。yarn.scheduler.maximum-allocation-mb:每个容器请求的最大内存量,以MB为单位。yarn.nodemanager.vmem-pmem-ratio:虚拟内存与物理内存的比率。
其他常见参数
hadoop.tmp.dir:Hadoop的临时目录,通常用于存储NameNode和DataNode的本地文件。io.file.buffer.size:用于读写文件的缓冲区大小,以字节为单位。fs.defaultFS(或fs.default.name,在旧版本中):HDFS的URI,客户端使用的默认文件系统。
这只是Hadoop参数的一个小部分示例。实际上,Hadoop的配置文件(如core-site.xml、hdfs-site.xml、yarn-site.xml和mapred-site.xml)中包含了许多其他参数,允许用户进行更详细的配置和优化。
为了有效地配置Hadoop集群,用户需要了解他们的具体需求、硬件资源和工作负载特性。此外,还可以参考Hadoop的官方文档和社区资源,以获取更多关于参数配置和优化的信息。