Hadoop作为一种分布式计算框架,在处理大数据时提供了诸多优势,但同时也面临一些安全性问题。以下是Hadoop面临的一些主要安全性问题:
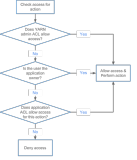
- 缺乏安全认证机制:Hadoop在基本的用户名和密码措施之外,缺乏完善的用户认证管理机制。这可能导致恶意用户轻易伪装成其他用户,窜改权限或进行非法访问。例如,未经授权的用户可能能够提交作业、修改JobTracker状态、修改HDFS上的数据,甚至伪装成DataNode或TaskTracker接收NameNode的数据和JobTracker的任务。
- 缺乏适合的访问控制机制:具有Hadoop使用权限的用户可能能够不受限制地浏览DataNode上存储的数据,甚至轻易修改和删除这些数据。这种缺乏细粒度访问控制的情况可能导致数据泄露或滥用。
- 数据传输和存储安全问题:Hadoop集群中数据的传输和存储也可能面临安全风险。未经加密的数据在传输过程中可能被截获,而存储在HDFS中的数据也可能被未经授权的用户访问。
为了解决这些问题,可以采取以下措施来加强Hadoop的安全性:
- 使用身份验证和授权:实施强密码策略,并使用Kerberos等身份验证机制来确保只有授权用户可以访问Hadoop集群。同时,通过角色级别的授权,可以更好地管理和控制访问权限。
- 数据加密:对敏感数据进行加密处理,确保数据在传输和存储过程中的安全性。可以使用TLS/SSL等加密协议来加密数据在集群内的传输过程,同时使用HDFS的加密存储功能来保护数据的机密性。
- 网络安全:配置防火墙和其他安全设备来保护Hadoop集群免受网络攻击。同时,确保各个节点之间的通信是安全的,使用网络隔离、VPN等方法保护数据在传输过程中的安全。
- 定期更新和补丁:定期更新Hadoop集群的软件和补丁,以修复已知的安全漏洞和错误。这有助于保持Hadoop集群的安全性和稳定性。
- 审计与监控:配置Hadoop以记录所有重要操作,例如文件访问、用户登录等,以便进行审计和监控。同时,使用专门的安全信息和事件管理工具来监控集群中的安全事件,检测潜在的安全漏洞或攻击。
综上所述,通过实施这些安全措施,可以大大增强Hadoop集群的安全性,保护数据的安全性和隐私性。