Spark01 —— Spark基础
一、为什么选择Spark?
1.1 MapReduce编程模型的局限性
- 1、繁杂:只有Map和Reduce两个操作,复杂的逻辑需要大量的样板代码
- 2、处理效率低:
- 2.1、Map中间结果写磁盘,Reduce写HDFS,多个Map通过HDFS交换数据
- 2.2、任务调度与启动开销大
- 3、不适合迭代处理、交互式处理和流式处理
1.2 Spark与MR的区别
Spark是类似Hadoop MapReduce的通用【并行】框架(仿照MR的计算流程)
- 1、Job中间输出结果可以保存在内存,不再需要读写HDFS
- 1.1、内存不够也可以写盘
- 2、比MapReduce平均快10倍以上
1.3 版本
| 2014 | 1.0 |
|---|---|
| 2016 | 2.x |
| 2020 | 3.x |
1.4 优势
1、速度快
基于内存数据处理,比MR快100个数量级以上(逻辑回归算法测试)
基于硬盘数据处理,比MR快10个数量级以上
为了容灾,会将==少量核心数据==进行持久化。即在计算过程中,会将检查点的数据写入磁盘中,当数据计算失败时,可以基于检查点数据进行恢复。
2、易用性
- 支持Java、【Scala】、【Python:pyspark】、R语言(主流使用Scala,pyspark存在缺陷:==只能在单机上计算,对单机内存和算力的要求过高==)
- 交互式shell方便开发测试
3、通用性
- 一栈式解决方案:
- 批处理:将数据分批次加载到内存中进行计算
- 交互式查询
- 实时流处理(微批处理)
- 图计算
- 机器学习
1.5 Spark其他知识
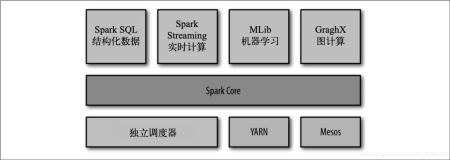
1、多种运行模式
==YARN== ✔、Mesos、EC2、Kubernetes、==Standalone==、==Local[*]==
Local[*]:在本地模式下运行,且尝试使用所有可用的核心。
2、技术栈
- Spark Core:核心组件,分布式计算引擎 RDD
- Spark SQL:高性能的基于Hadoop的SQL解决方案
- Spark Streaming:可以实现高吞吐量、具备容错机制的准实时流处理系统
Spark GraphX:分布式图处理框架
Spark MLlib:构建在Spark上的分布式机器学习库
3、spark-shell:Spark自带的交互式工具
- local:spark-shell --master local[*]
- alone:spark-shell --master spark://MASTERHOST:7077
- yarn :spark-shell --master yarn(需要先启用Hadoop)
4、Spark服务
- Master:Cluster Manager
- Worker:Worker Node
二、Spark的基础配置
Spark在IDEA工程中的基础配置
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<spark.version>3.1.2</spark.version>
<spark.scala.version>2.12</spark.scala.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${spark.scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
</dependencies>
三、Spark实例
Spark WordCount
val conf: SparkConf = new SparkConf()
.setAppName("spark01")
.setMaster("local[*]")
val sc: SparkContext = SparkContext.getOrCreate(conf) // 获取SparkContext,Spark应用程序的入口点
val storyPath = "E:\\BigData\\projects\\scala01\\data\\story.txt"
sc.textFile(storyPath,4)// 读取文本文件,将其转化为一个RDD
.flatMap(_.split("[^a-zA-Z]+")) // 将文本文件按段落按句子分割单词
.filter(_.nonEmpty) // 过滤掉空单词
.map((_, 1)) // 将单词映射成(单词,1)
.reduceByKey(_ + _) // 将相同单词出现的次数求和 reduceByKey()的含义是:对相同键对应的值进行聚合操作,这个函数是Spark独有的
.sortBy(_._2, false) // 按出现次数降序排序
.collect() // 获取结果 Spark的转换操作是惰性的,仅仅定义了要进行的计算,而不立即执行它们。当调用collect()时,Spark会触发所有前面定义的转换操作,实际进行数据的处理。
.foreach(println)
sc.stop()
四、Spark运行架构
运行架构
①、在驱动程序Driver Program中,通过SparkContext主导应用的执行
②、SparkContext可以连接不同类型的 CM(CM的类型==与运行模式相关==),连接后,获得节点上的 Executor
③、一个节点默认一个Executor,可通过SPARK_WORKER_INSTANCES调整
④、Executor一般Spark启动时由Cluster Manager创建并管理,创建Executor是一个初始化过程的一部分,其中包括为每个Executor分配资源(CPU、内存等),Executor的作用是并行处理Driver分配的多个任务。
⑤、每个Task处理一个RDD分区


- Application 建立在Spark上的==用户程序==,包括==Driver代码==和==运行在集群各节点Executor中的代码==
- Driver program 驱动程序,Application中的==main函数==,并==创建SparkContext==
- Spark Context 整个应用程序的入口
- Cluster Manager 在==集群(StandAlone、Mesos、YARN)上获取资源的外部服务==
- Worker Node 集群中任何可以==运行Application代码==的节点
- Executor 某个Application==运行在Worker节点上的一个进程==
- Task 被送到某个Executor上的==工作单元==
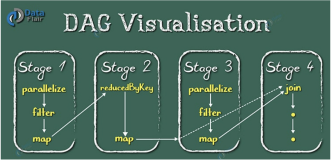
- Job ==多个Task组成的并行计算==,由Action触发生成,一个Application中含多个Job
- Stage ==每个Job会被拆分成多组Task,作为一个TaskSet==,其名称为Stage
- ZooKeeper 用于管理Spark集群中的Master节点,确保在一个Master节点故障时,能够迅速切换到备用的Master节点,以保证集群的高可用性。
SparkContext
连接Driver和Spark Cluster(Workers)
Spark执行的主入口
每个JVM仅能有一个活跃的SparkContext,需要有多个SparkContext需要开多台虚拟机。
- 配置
SparkContext
val conf:SparkConf = new SparkConf()
.setAppName(name:String)
.set(key:String,value:String) // 多项设置
.setMaster(master:String)
val sc: SparkContext = SparkContext.getOrCreate(conf)
masterlocal[*]【推荐】:CPU核数为当前环境的最大值local[2]:CPU核数为2local:CPU核数为1yarn
实例:
SparkContext的工厂化方法- 使用
lazy val对重要资源实现=="需要时再创建"== - 使用
Seq()实现对配置项的包装
- 使用
package cha05
import org.apache.spark.api.java.JavaSparkContext.fromSparkContext
import org.apache.spark.{SparkConf, SparkContext}
class SparkCom(appName:String,master:String,options:Seq[(String,String)]){
private lazy val _conf:SparkConf = {
val conf = new SparkConf()
conf.setAppName(appName)
conf.setMaster(master)
options.foreach(o => conf.set(o._1,o._2))
conf
}
private lazy val _sc = SparkContext.getOrCreate(_conf)
def this(appName:String) = {
this(appName,"local[*]",Seq())
}
def sc = _sc
def logLevel(level:String): Unit = {
if(level.matches("ERROR|INFO|WARN|FATAL")){
_sc.setLogLevel(level)
}
}
def close(): Unit = {
_sc.stop()
}
}
object SparkCom{
def apply(appName:String,master:String,options:Seq[(String,String)]): SparkCom = new SparkCom(appName,master,options)
def apply(appName:String): SparkCom = new SparkCom(appName)
}
- 调用示例
// 引入必要的 Spark 类库
import org.apache.spark.{SparkConf, SparkContext}
// 定义一个包含配置选项的SparkCom对象
val customOptions = Seq(
("spark.executor.memory", "4g"), // 为每个执行器分配4GB内存
("spark.executor.cores", "4"), // 为每个执行器分配4个核心
("spark.cores.max", "40"), // 最多使用40个核心
("spark.local.dir", "/tmp/spark-temp") // 指定Spark的临时目录
)
// 创建一个SparkCom实例,应用名称为"MySparkApp",使用本地模式运行
val sparkApp = SparkCom("MySparkApp", "local[*]", customOptions)
// 获取SparkContext
val sc = sparkApp.sc
// 可以使用sc来进行一些Spark操作,例如读取数据、执行转换等
// 示例:读取本地系统的一个文件并计算其行数
val lines = sc.textFile("path/to/your/file.txt")
val lineCount = lines.count()
println(s"Total lines in the file: $lineCount")
// 设置日志级别为ERROR,减少控制台日志量
sparkApp.logLevel("ERROR")
// 应用完成后,关闭SparkContext
sparkApp.close()
五、Spark分区
分区过程

1 File —— N Blocks —— 1 InputSplit —— 1 Task —— 1 RDD Partition
RDD
RDD的相关概念
RDD是描述数据存储位置的(主要数据抽象),并不实际存储数据。
RDD是一个大的不可变、分区、并行处理的数据集合,每个子集合就是一个分区,存储在集群的工作节点上的内存和硬盘。
RDD是数据转换的接口,数据规模经过转换越来越小,最终指向目标数据类型,
RDD指向了
或存储在Hive(HDFS)、Cassandra、HBase等
或缓存(内存、内存+磁盘、仅磁盘等)
或在故障或缓存收回时重新计算其他RDD分区中的数据
RDD是弹性分布式数据集(Resilient Distributed Datasets)
分布式数据集
RDD是只读的、==分区记录==的集合,每个分区==分布在集群的不同节点==上。
RDD并不存储真正的数据,只是【==对数据和操作==】的描述。
弹性
- RDD默认存放在内存中,当内存不足,Spark自动将RDD写入磁盘
容错性
- 根据==数据血统==,可以自动从节点失败中恢复分区。

- RDD的特性
- 一系列的分区(分片)信息,每个任务处理一个分区
- 每个分区上都有
compute函数,计算该分区中的数据 - RDD之间有一系列的依赖
- 分区器决定数据会被分在那个分区
- 将计算任务分派到其所在处理数据块的存储位置
RDD可以==跨集群的多个节点==存储数据,支持两种类型的操作:转换和行动。
RDD操作类型:分为lazy和non-lazy两种
转换操作(
lazy):定义了一个操作序列,实际计算则被推迟到触发动作时。常见的转换操作包括map,filter,flatMap,reduceByKey等。每一个RDD都由转换操作生成,一个 RDD 由另一个 RDD 通过某种转换操作生成时,原始的 RDD 称为
父 RDD,新生成的 RDD 称为子 RDD转换操作普遍会丢失父RDD的分区信息,因为分器依赖于键的不变性,但是转换操作可能改变元素的数量和类型。
动作算子(
non-lazy):动作会触发前面定义的所有转换的实际执行。常见的动作操作包括count,collect,reduce,foreach等。
一个InputSplit对应的多个Blocks只能位于一个File中。
这些Task会被分配到集群上的某个节点的某个Executor去执行,会尽量使执行任务的计算节点(Worker)与存储数据的节点(DataNode)是同一台机器。
每个Executor由若干core组成,每个Executor的每个core一次只能执行一个Task。
每个Task的执行结果就是生成了RDD的一个Partition。
RDD创建方式
// 集合创建:小数据集,可通过 numSlices 指定并行度(分区数)
val rdd: RDD[T] = sc.parallelize(seq:Seq[T], numSlices:Int) // ✔
val rdd: RDD[T] = sc.makeRDD(seq:Seq[T], numSlices:Int) // 调用了 parallelize
// 将序列分为3个分区,并且进行数字的频次统计
// val rddInt: RDD[Int] = sc.makeRDD(Seq(2, 3, 4, 5, 6, 7, 8, 9, 10), 3)
val rddInt: RDD[Int] = sc.parallelize(Seq(2, 3, 4, 5, 6, 7, 8, 9, 10), 3)
rddInt
.map((_,1))
.reduceByKey(_+_)
.foreach(println)
// 外部数据源创建: 可通过 minPartitions 指定最小分区数
// 文件系统:local(file:///...)或hadoop(hdfs://)
val rdd: RDD[String] = sc.textFile(path:String, minPartitions:Int)
val rdd: RDD[String] = sc.wholeTextFiles(dir:String, minPartitions:Int)
RDD分区
分区概念
- 每个分区都是被分发到不同
worker node的候选者 - 每个分区对应一个
Task
- 每个分区都是被分发到不同
分区数量
- 分区数量最好从源头设计,尽量不在过程中修改分区数量,会造成数据迁移,增加网络负载。同时引发不必要的
Shuffle过程。
- 分区数量最好从源头设计,尽量不在过程中修改分区数量,会造成数据迁移,增加网络负载。同时引发不必要的
- 使用
textFile()方法创建RDD时可以传入第二个参数指定==最小分区数量==,最小分区数量只是期望的数量,Spark会根据实际文件大小、Block大小等情况确定最终分区数量。
- 分区数要等于集群CPU核数,也要等于
1/Block数
分区方式
- 分区器主要用于==键值对的RDD==,如通过
reduceByKey等操作创建的RDD。 - 有
HashPartition(默认)和RangePartition两种分区方式HashPartitioner:它使用键的哈希值来分配记录,尽量保证数据在不同分区间的均匀分布。RangePartitioner:它将键排序后分成若干连续的范围,每个范围对应一个分区,这样可以让范围内的键都分到一个分区。
- 分区器主要用于==键值对的RDD==,如通过
RDD与DAG

每个Stage由n个Task组成,每个Task构成一个TaskSet。
有多少个Partition,TaskSet中就有多少个Task
Spark Shuffle
在Spark中,Shuffle是代价较大的操作,应该尽量避免。
- 过程:基本与MR中的
Shuffle过程类似。- 分区Partition
- Sort根据Key排序
- Combiner进行Value的合并
- 需要进行
Shuffle的Spark算子reduceByKey:需要通过网络对不同的Executor中相同key对应的值进行分组Pull(拉取)操作repartition:当RDD的分区数量和父RDD分区数量不同时,就会引起数据的重新组织。sortByKey:当需要进行排序操作时
再分区
默认算子间的分区数不发生变化,如果需要进行==再分区操作==,可以==通过在可带分区参数的方法调用时设置分区参数==或==调用重新设置分区的算子==
numPartitions:指定分区数partitioner:指定分区器repartition(numPartitions:Int):进行重分区操作,必定会触发Shuffle操作
六、Spark算子
转换算子
/*
简单类型 RDD[T]
*/
// 【逐条处理】
val rdd2: RDD[U] = rdd.map(f:T=>U)
// 【扁平化处理】:TraversableOnce : Trait用于遍历和处理集合类型元素,类似于java:Iterable
val rdd2: RDD[U] = rdd.flatMap(f:T=>TraversableOnce[U])
/* 【分区内逐行处理】:以分区为单位(分区不变)逐行处理数据 ✔
*/
val rdd2: RDD[U] = rdd.mapPartitions(f:Iterator[T]=>Iterator[U][,preservePar:Boolean])
// 【分区内逐行处理】:以分区为单位逐行处理数据,并追加分区编号。
val rdd2: RDD[U] = rdd.mapPartitionsWithIndex(f:(Int,Iterator[T])=>Iterator[U][,preservePar:Boolean])
mapPartitions- 如何判断是否需要保留父RDD的分区器设置?
- 优化键值对操作:如果输入数据已经根据键正确分区,Spark可以在每个分区内独立地进行规约,无需跨节点传输大量数据。
- 如果某个操作(如
map)不改变键的映射关系(则数据的键仍然映射到同一个分区)
map和mapPartitions的区别- 1.IO数量:
map:对==每个输入RDD中的元素==都执行一次转换函数,因此输入和输出的元素数量是一致的,==一进一出==。mapPartitions:对==每个分区中的元素进行处理,每个分区只会产生一个输出==。因此,如果有多个分区,输入和输出的元素数量不一定是一致的,多进多出。
- 2.性能:
map:对于每个元素,都会启动一次函数调用,适用于简单的转换。但是,如果有大量的小任务,这可能会导致性能下降,因为函数调用的开销可能会很高。mapPartitions:对于每个分区,只会启动一次函数调用。这样可以减少函数调用的开销,特别是当处理的操作比较复杂时,效率更高。此外,可以在每个分区中累积一些状态信息,从而进一步提高性能。
- 3.内存占用:
map:由于每个元素都会单独处理,可能会占用大量的内存,尤其是在处理大规模数据时容易导致OOM(Out Of Memory)错误。mapPartitions:由于对每个分区进行处理,可以控制每次处理的数据量,因此更容易管理内存。
- 总结:
map适用于简单的转换操作,而mapPartitions适用于复杂的转换操作,当数据量较大时,map针对每个元素都进行单独处理的特性会导致过高的性能和内存开销。
- 1.IO数量:
- 如何判断是否需要保留父RDD的分区器设置?
val storyPath = "E:\\BigData\\projects\\scala01\\data\\story.txt"
// 按顺序形成四个分区
sc.textFile(storyPath,4)
// mapPartitions()的第一个参数是应用于每个分区的函数,第二个参数`preservePartitioning`指示是否保持父RDD的分区器设置。如果设置为`true`,Spark将使用相同的分区器来创建结果RDD。
.mapPartitions(_.flatMap(_.split("^[a-zA-Z]+")).map((_,1)),true)
.reduceByKey(_+_)
.foreach(println)
mapPartitionsWithIndex
sc.textFile("hdfs://single01:9000/hadoop/data/movies.csv", 4)
.mapPartitionsWithIndex((parIx, it) => { // (parIx,it) => (分区索引,迭代器)
// 对第一个分区,删除第一行 => 即删除全文的首行
if (parIx == 0) {
it.drop(1)
}
it.flatMap(_.lat2)
.toArray
.groupBy(_._1)
.map(tp2=>(tp2._1,tp2._2.size))
.toIterator // mapPartitionsWithIndex()需要迭代器作为返回类型
}).reduceByKey(_+_) // 在不同分区间对具有相同键的值进行汇总。
.foreach(println)
七、Spark优化
数据的本地化读取
SparkContext会从NameNode获取数据片存储在哪些DataNode上面,SparkContext在建任务的时候会通过Cluster Manager获取这些位置机器的Executor,并直接从DataNode读取数据,实现数据的本地化读取。

八、拓展
数据处理提取指标 基本思路:
查询集群资源 - 确认==可用的机器数量==和==每台机器的配置==(CPU核心数、线程数、内存大小)。这有助于了解集群的计算能力和分配任务的基础。
数据和指标概览 - 明确要提取的若干个指标,并了解这些指标==涉及的数据及其规模==。
检查分组聚合操作 - 确定是否需要对数据进行分组和聚合。
处理数据倾斜 - 分组聚合操作可能会导致数据倾斜,即某些分组的数据量远大于其他分组。通过==数据抽样==来评估倾斜程度,并根据需要启用倾斜优化配置。
set hive.groupby.skewindata=true;
- 优化并行处理 - 分析各个数据处理阶段(stage)的==依赖关系==,确定是否可以通过并行处理来优化性能。
set hive.exec.parallel=true;
附:3、4、5属于常见思路,还可以存在有其他思路。