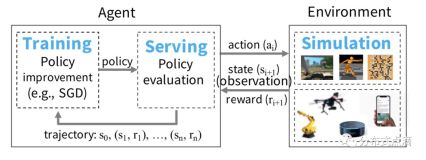
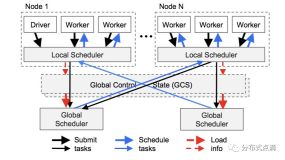
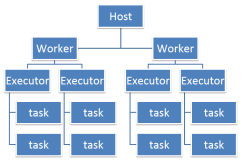
为了解决Spark在深度学习中的资源消耗问题,可以采取以下措施:
- 优化资源配置:合理分配和调整Spark作业的内存和CPU资源,确保资源得到充分利用而不至于浪费。例如,可以通过调整Spark的配置参数来限制单个任务的资源使用,或者根据任务的实际需要动态分配资源。
- 利用GPU加速:由于深度学习算法通常涉及大量浮点运算,使用GPU进行并行计算可以显著提高处理速度和效率。因此,可以考虑在Spark集群中集成GPU资源,以支持更复杂的深度学习模型。
- 分布式训练:利用Spark的分布式计算能力进行模型训练,可以将大规模数据集分散到多个节点上进行处理,从而减少单个节点的负载。此外,可以使用像Horovod-on-Spark或TensorFlowOnSpark这样的解决方案来进一步优化分布式训练过程。
- 算法优化:选择适合大规模数据处理的深度学习算法,并对现有算法进行优化,以提高其在Spark上的执行效率。例如,可以选择那些对内存和计算要求较低的算法或模型。
- 数据预处理:在进行深度学习之前,对数据进行有效的预处理,如特征选择和降维,可以减少模型的复杂度和资源消耗。同时,通过数据筛选和采样,可以减少实际处理的数据量。
- 监控和调优:定期监控Spark作业的性能指标,如执行时间、资源使用情况等,并根据监控结果调整配置和参数。这有助于发现潜在的性能瓶颈并及时进行优化。
- 使用高效的库和工具:利用专门针对Spark优化的深度学习库,如Deeplearning4j,可以提高深度学习任务的效率。同时,可以考虑使用MLlib等库中的高级功能来简化深度学习流程。
- 服务器和服务优化:对于提供深度学习服务的服务器,可以通过优化服务配置和资源分配来提高整体性能。例如,可以使用Thrift server服务来减少资源消耗。
- 社区和支持:关注Spark社区的最新动态和最佳实践,利用社区提供的支持和资源来解决遇到的性能问题。例如,可以参考其他用户的经验教训,或者寻求专家的帮助。
总的来说,通过上述措施,可以有效地减少Spark在深度学习中的资源消耗,提高计算效率,同时也能够保证深度学习模型的准确性和性能。