背景
关于sql调参数、数据倾斜可以搜到很多文章,本文主要讲解常见的SQL开发场景、‘奇葩’SQL写法并深入执行计划,带你了解如何快速写出高效率SQL。
高效写法
union直接使用效率低吗?
场景介绍
在一些业务场景中,需要将多份数据合并在一起,比如要取客户信息,客户信息存在两张表中有交叉(假设两张表中交叉的客户信息是一致的),需先将两份数据合并在一起。
写法&执行计划探查
因为两张表中数据有交叉,所以需要会先将数据去重,然后再去join。去重方式常见于:
SELECT cst_id,cst_info FROM ( SELECT cst_id,cst_info FROM @cst_info_a WHERE dt = '${bizdate}' UNION SELECT cst_id,cst_info FROM cst_info_b WHERE dt = '${bizdate}' )cst_info ;
这种情况下,会理解为先将两两份数据不做任务处理就合并在一起,导致shuffle、中间临时写入的数据量和读取数据量和数据源都是一致的,然后再去做去重。因为数据量在中间过程没有没有减少,所以效率相对来说会低一些。现在来看一下执行计划:

发现执行计划是做过的优化的,已经是最优执行计划了。
接下来按照理解中的高效sql写法来看一下执行计划:
-- 方式一 SELECT cst_id,cst_info FROM ( SELECT cst_id,cst_info FROM @cst_info_a WHERE dt = '${bizdate}' GROUP BY cst_id,cst_info UNION SELECT cst_id,cst_info FROM @cst_info_b WHERE dt = '${bizdate}' GROUP BY cst_id,cst_info )cst_info; --方式二 SELECT cst_id,cst_info FROM ( SELECT cst_id,cst_info FROM @cst_info_a WHERE dt = '${bizdate}' GROUP BY cst_id,cst_info UNION ALL SELECT cst_id,cst_info FROM @cst_info_b WHERE dt = '${bizdate}' GROUP BY cst_id,cst_info )cst_info GROUP BY cst_id,cst_info;
两种写法的执行计划一致,如下:

发现自己另外加的聚合处理,反而增加了复杂度。
总结
ODPS已经对union做过优化,直接使用就可以了。并且对三个及以上的(X张)表做union,执行计划是X个MAP任务+1个REDUCE任务;不会像hive是X个MAP任务+(X-1)个REDUCE任务,还需要调整SQL才能实现最优的执行计划。
count distinct真的慢吗?
场景介绍
在开发过程中,经常会遇到一些数据探查,比如探查资产信息表中,有多少用户数,探查过程中经常会用到count distinct,那么它的效率如何?
写法&执行计划探查
探查资产信息表中近5天的用户数,常见的写法与常规认为的优化写法:
--选择近5天的资产来看 --常见写法,count distinct写法 SELECT COUNT(DISTINCT cst_id) AS cst_cnt FROM @pc_bill_bal WHERE dt BETWEEN '${bizdate-5}' AND '${bizdate}' ; --优化写法 SELECT COUNT(1) AS cst_cnt FROM ( SELECT cst_id FROM @pc_bill_bal WHERE dt BETWEEN '${bizdate-5}' AND '${bizdate}' GROUP BY cst_id )base ;
一般都会认为直接count distinct效率很低,是这样吗?接下来看一下两个执行计划对比
常规写法:

优化写法:

从执行计划可以看出,直接count distinct的写法被优化成了两次去重处理,一次计算总和,并不是直接全量来去重计算。再看优化写法,两次去重处理,两次计算总和,反而比count distinct多了一步,不过运行效率还是很快的。最后看一下运行时间和消耗资源,常规写法比优化写法快了28%(62s、86s),资源消耗少28%。
那么count distinct可以肆无忌惮的使用了吗?
接下来看另外一种场景,探查资产信息表中近5天每天的用户数,常见的写法与常规认为的优化写法:
--选择近5天的资产来看 --常见写法,count distinct写法 SELECT dt ,COUNT(DISTINCT cst_id) AS cst_cnt FROM @pc_bill_bal WHERE dt BETWEEN '${bizdate-5}' AND '${bizdate}' GROUP BY dt ; --优化写法 SELECT dt ,COUNT(cst_id) AS cst_cnt FROM ( SELECT dt ,cst_id FROM @pc_bill_bal WHERE dt BETWEEN '${bizdate-5}' AND '${bizdate}' GROUP BY dt ,cst_id )base GROUP BY dt ;
看一下这种场景下两种执行计划对比
常规写法(此处额外看一下分配的task):

优化写法:


从执行计划可以看出,直接count distinct的写法进行了一次去重,就将3亿条数据给到了5个task进行去重计算总和,每个task的压力相当大。再看优化写法,两次去重处理,两次计算总和,每一步都运行的很快,没有长尾。最后看一下运行时间和消耗资源,常规写法比优化写法慢了26倍,资源消耗多出2倍。
总结
ODPS对count distinct做了执行计划优化,但是限于从数据源只读取1个字段的情况下。当从数据源读取了多个字段时,应将count distinct写法改为group by count写法。
多张大表join提速(聚合类型)
场景介绍
在日常的开发工作中,经常会遇到多张表关联取属性的情况,比如计算用户在过去一段时间A、B、C...N行为的次数,或者是在资管领域中,统计一个资产池中的所有资产(日初资产+放款资产+买入资产)。
写法&执行计划探查
假设有3份数据需要关联得到属性,常规的写法为使用2次full outer join + coalesce来关联取值;或者先将3份数据主体合并在一起,再使用3次left join。
-- 举例为资产池得到每个用户的所有资产 -- 使用full outer join + coalesce的写法 SELECT COALESCE(tt1.cst_id, tt2.cst_id) as cst_id ,COALESCE(tt1.bal_init_prin, 0) AS bal_init_prin ,COALESCE(tt1.amt_retail_prin, 0) AS amt_retail_prin ,COALESCE(tt2.amt_buy_prin, 0) AS amt_buy_prin FROM ( SELECT COALESCE(t1.cst_id, t2.cst_id) as cst_id ,COALESCE(t1.bal_init_prin, 0) AS bal_init_prin ,COALESCE(t2.amt_retail_prin, 0) AS amt_retail_prin FROM @bal_init t1 -- 日初资产 FULL OUTER JOIN @amt_retail t2 -- 当天放款资产 ON t1.cst_id = t2.cst_id )tt1 FULL OUTER JOIN @amt_buy tt2 -- 当天买入资产 ON tt1.cst_id = tt2.cst_id ;
接下来看优化写法:
-- 写法一 SELECT cst_id ,SUM(bal_init_prin) as bal_init_prin ,SUM(amt_retail_prin) as amt_retail_prin ,SUM(amt_buy_prin) as amt_buy_prin FROM ( SELECT cst_id, bal_init_prin, 0 AS amt_retail_prin, 0 AS amt_buy_prin FROM @bal_init -- 日初资产 union ALL SELECT cst_id, 0 AS bal_init_prin, amt_retail_prin, 0 AS amt_buy_prin FROM @amt_retail -- 当天放款资产 UNION ALL SELECT cst_id, 0 AS bal_init_prin, 0 AS amt_retail_prin, amt_buy_prin FROM @amt_buy -- 当天买入资产 )t1 GROUP BY cst_id ; -- 优化写法二 SELECT cst_id ,SUM(IF(flag = 1, prin, 0)) as bal_init_prin ,SUM(IF(flag = 2, prin, 0)) as amt_retail_prin ,SUM(IF(flag = 3, prin, 0)) as amt_buy_prin FROM ( SELECT cst_id, bal_init_prin AS prin, 1 AS flag FROM @bal_init -- 日初资产 union ALL SELECT cst_id, amt_retail_prin AS prin, 2 AS flag FROM @amt_retail -- 当天放款资产 UNION ALL SELECT cst_id, amt_buy_prin AS prin, 3 AS flag FROM @amt_buy -- 当天买入资产 )t1 GROUP BY cst_id ;
对比join写法和优化写法的执行计划(这两个执行计划内部做的事情和任务名称理解一致,就不展开看了)
join写法:

优化写法:

从执行计划可以看出,join写法的执行步骤要更多,多次shuffle也会消耗更多的资源,串行运行的时间也会更长。优化写法只需要在读取所有数据之后,做一次reduce就可以完成。最后对比一下运行时间和资源消耗,优化写法运行时间快20%,资源使用减少30%。(场景越复杂,效果越好)
总结
由于JOIN是离线数据开发中最常出现低效的环节,那么直接干掉JOIN其实是更好的选择。当多张表的关联键相同取int类型、聚合的值的场景下,union all + group by写法运行更快、更节省资源、代码开发运维更加简单,并且在表行数越多、关联表越多、关联键越多的场景下,优势会更加突出。关于两种优化写法,优化写法二更加灵活、更好维护、资源占用更少,但是对于需要使用占位数据的场景(比如聚合map),方法一更加适合。
多张大表join提速(字符串类型)
场景介绍
日常开发中,经常遇到从一个主体多张表取属性的情况,比如客户信息相关的数据,A表取地址、B表取电话号、C表取uv、D表取身份信息、E表取偏好。
写法&执行计划探查
假设有3份数据需要关联得到属性,常规的写法为使用2次full outer join + coalesce来关联取值;或者先将3份数据主体合并在一起,再使用3次left join。
-- 本案例和上边案例类似,使用先将主体合并在一起,再使用三次left join SELECT base.cst_id AS cst_id ,t1.bal_init_prin AS bal_init_prin ,t2.amt_retail_prin AS amt_retail_prin ,t3.amt_buy_prin AS amt_buy_prin FROM ( SELECT cst_id FROM @bal_init -- 日初资产 UNION SELECT cst_id FROM @amt_retail -- 当天放款资产 UNION SELECT cst_id FROM @amt_buy -- 当天买入资产 )base LEFT JOIN @bal_init t1 -- 日初资产 ON base.cst_id = t1.cst_id LEFT JOIN @amt_retail t2 -- 当天放款资产 ON base.cst_id = t2.cst_id LEFT JOIN @amt_buy t3 -- 当天买入资产 ON base.cst_id = t3.cst_id ;
接下来看优化写法:
-- STRING数据类型利用json来实现 SELECT cst_id ,GET_JSON_OBJECT(all_val, '$.bal_init_prin') AS bal_init_prin ,GET_JSON_OBJECT(all_val, '$.amt_retail_prin') AS amt_retail_prin ,GET_JSON_OBJECT(all_val, '$.amt_buy_prin') AS amt_buy_prin FROM ( SELECT cst_id ,CONCAT('{',CONCAT_WS(',', COLLECT_SET(all_val)) , '}') AS all_val FROM ( SELECT cst_id ,CONCAT('\"bal_init_prin\":\"', bal_init_prin, '\"') AS all_val FROM @bal_init -- 日初资产 UNION ALL SELECT cst_id ,CONCAT('\"amt_retail_prin\":\"', amt_retail_prin, '\"') AS all_val FROM @amt_retail -- 当天放款资产 UNION ALL SELECT cst_id ,CONCAT('\"amt_buy_prin\":\"', amt_buy_prin, '\"') AS all_val FROM @amt_buy -- 当天买入资产 )t1 GROUP BY cst_id )tt1 ;
对比join写法和优化写法的执行计划
join写法的执行计划:

优化写法:


对比两个执行计划,join写法对于每一张表的数据使用了两次,分别为构建主体和取值,所以每一个MAP、JOIN任务的复杂度还是比较高的,但是优化写法MAP、REDUCE任务简洁明了。并且随着表的增多,JOIN写法的JOIN任务负责度会更高。对比运行时间和资源消耗,优化写法运行快了20%,资源消耗减少20%。(场景越复杂,效果越好)
由于使用到collect_set,所以需要考虑该节点是否存在超内存的问题并进行内存调整,该场景一般情况下不会出现。
总结
同大表join(聚合类型),区别在于此方法适用于STRING类型。注意collect_set函数的内存占用。
mapjoin为什么快?是否生效了?
场景介绍
日常开发中,经常会遇到大表join小表的情况,mapjoin是老生常谈的处理方式,但是也要注意写法、小表内存参数调整以保障mapjoin生效。
写法&执行计划探查
目前ODPS对mapjoin做了优化可以自动开启,不用手动写/* +mapjoin(a,b)*/来开启了。inner join,大表left join小表都可以直接使mapjoin生效。mapjoin生效写法:
-- base为大表,fee_year_rate为小表 -- 方式一,inner join SELECT base.* ,fee_year_rate.* FROM @base base INNER JOIN @fee_year_rate fee_year_rate ON (base.terms = fee_year_rate.terms) ; -- 方式一,LEFT join SELECT base.* ,fee_year_rate.* FROM @base base LEFT JOIN @fee_year_rate fee_year_rate ON (base.terms = fee_year_rate.terms) ;
mapjoin未生效写法:
-- 方式三,right join SELECT base.* ,fee_year_rate.* FROM @base base RIGHT JOIN @fee_year_rate fee_year_rate ON (base.terms = fee_year_rate.terms) ; -- 方式四, full outer join SELECT base.* ,fee_year_rate.* FROM @base base FULL OUTER JOIN @fee_year_rate fee_year_rate ON (base.terms = fee_year_rate.terms) ;
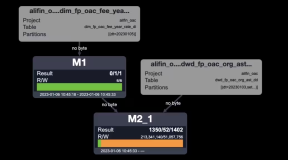
对比一下执行计划
mapjoin生效执行计划:


mapjoin未生效执行计划:


MapJoin简单说就是在Map阶段将小表读入内存,顺序扫描大表完成Join。对比两种执行计划,mapjoin生效之后,只有两个MAP任务,没有了JOIN任务,相当于省了一次JOIN。mapjoin是否生效,可以看是HashJoin还是MergeJoin来判断。
总结
mapjoin开启之后,运行效率提高明显,但会因为写法、小表过大不生效,要从执行计划中去判断并做参数调整保障mapjoin生效。小表大小调整参数:set odps.sql.mapjoin.memory.max=2048(单位M)
distmapjoin:加强版mapjoin
场景介绍
对于大小表join的场景,小表经常会超出mapjoin的最大内存,那么mapjoin就不会生效了。ODPS提供了将中型表放入内存的方案,即distmapjoin,用法和mapjoin相似,即在select语句中使用Hint提示/*+distmapjoin(<table_name>(shard_count=<n>,replica_count=<m>))*/才会执行distmapjoin。shard_count(分片数,默认[200M,500M])和replica_count(副本数,默认1)共同决定任务运行的并发度,即并发度=shard_count * replica_count。
写法&执行计划探查
常规写法:
SELECT base.* ,cst_info.* FROM @base base LEFT JOIN @cst_info cst_info ON (base.cst_id = cst_info.cst_id AND base.origin_inst_code = cst_info.inst_id) ;
优化写法:
SELECT /*+distmapjoin(cst_info(shard_count=20))*/ base.* ,cst_info.* FROM @base base LEFT JOIN @cst_info cst_info ON (base.cst_id = cst_info.cst_id AND base.origin_inst_code = cst_info.inst_id) ;
对比执行计划
常规写法:


优化写法:


对比两种执行计划和mapjoin执行计划可以发现,优化写法都省去了JOIN任务,这个在很大程度上加快了运行速度和降低资源消耗,distmapjoin写法比mapjoin写法多了一个REDUCE任务,即对小表的分片。
distmapjoin是否生效,可以看是DistributedMapJoin1还是MergeJoin来判断。
总结
同mapjoin总结
where限制条件写在外层会很慢吗?
场景介绍
日常开发中,大家都习惯性将过滤条件紧跟在读表之后,这样可以减少数据量以减少任务运行时间。
写法&执行计划探查
过滤条件在读表之后的规范写法和多表join之后再过滤的非规范写法。
-- 规范写法 SELECT base.* ,fee_year_rate.* FROM ( SELECT * FROM @base where terms = '12' )base INNER JOIN @fee_year_rate fee_year_rate ON (base.terms = fee_year_rate.terms) ; -- 非规范写法 SELECT base.* ,fee_year_rate.* FROM @base base INNER JOIN @fee_year_rate fee_year_rate ON (base.terms = fee_year_rate.terms) WHERE base.terms = '12' ;
印象中,规范写法的运行效率肯定会高一些,看一下执行计划会发现两种写法的执行计划是一样的,都在join之前做了过滤

总结
ODPS对谓词前置做了很好的优化,但是日常开发也尽量将过滤条件跟在读表之后,这样更加规范,代码也会具有更好的可读性。
总结
做好SQL开发、优化,得先学会阅读执行计划,多动手尝试可以快速帮助你掌握该技能。(本篇讲到的执行计划,随着ODPS的优化,会发生改变)
作者 | 周潮潮(徽成)
来源 | 阿里云开发者公众号