简介:HAProxy提供高可用性、 负载均衡以及基于TCP和HTTP应用的代理,支持 虚拟主机,它是免费、快速并且可靠的一种解决方案。HAProxy特别适用于那些负载特大的web站点,这些站点通常又需要会话保持或七层处理。HAProxy运行在当前的硬件上,完全可以支持数以万计的 并发连接。并且它的运行模式使得它可以很简单安全的整合进您当前的架构中,同时可以保护你的web服务器不被暴露到网络上。
项目需求:由于网站规模的扩大,访问量的也越来越多,原来的一台机器提供网站服务,出现故障后就中断了网站服务,造成经济损失,现在老板发话要解决单点故障,于是我就找了些资料,对比了下Haproxy、LVS、Nginx,是各有各的优点,我们的网站每天的PV也不是很大,就先在虚拟机上做了下测试,仅做Haproxy部分七层负载均衡,生产环境需要Haproxy+keepalived来实现负载均衡器高可用性。
先了解下HAProxy常用的算法:
roundrobin #表示简单的轮询,每个负载均衡器基本都具备的
static-rr #表示根据权重
leastconn #表示最少连接者先处理
source #表示根据请求源IP, haprox按照客户端的IP地址所有请求都保持在一个服务器上
ri #表示根据请求的URI
rl_param #表示根据请求的URl参数'balance url_param' requires an URL parameter name
hdr(name) #表示根据HTTP请求头来锁定每一次HTTP请求
rdp-cookie(name) #表示根据据cookie(name)来锁定并哈希每一次TCP请求
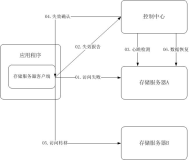
拓扑图:

下载: http://haproxy.1wt.eu/
配置如下:
安装haproxy
[root@localhost ~]# tar zxvf haproxy-1.4.24.tar.gz [root@localhost ~]# cd haproxy-1.4.24 [root@localhosthaproxy-1.4.24]# make TARGET=linux26 PREFIX=/usr/local/haproxy [root@localhosthaproxy-1.4.24]# make install PREFIX=/usr/local/haproxy
#进入安装目录创建配置文件
[root@localhosthaproxy-1.4.24]# cd /usr/local/haproxy/ [root@localhost haproxy]# mkdir conf [root@localhost haproxy]# cd conf/ [root@localhost conf]# vi haproxy.cfg global log 127.0.0.1 local0 #通过syslog服务的local0输出日志信息 maxconn 4096 #单个进程的最大连接数 uid 99 #所属运行的用户uid,默认nobod gid 99 #所属运行的用户组,默认nobody daemon #后台运行 nbproc 2 #工作进程数量 pidfile /var/run/haproxy.pid defaults log global log 127.0.0.1 local3 err #使用本机上的syslog服务的local3 设备记录错误信息[err warning info debug] mode http #工作模式在7层,tcp是4层 option httplog #使用http日志类别,默认是不记录http请求的 option httpclose #每次请求完毕后主动关闭http通道式 option forwardfor #如果后端服务器需要获得客户端的真实IP需要配置次参数,将可以从Http Header中获得客户端IP option redispatch #当serverId对应的服务器挂掉后,强制定向到其他健康的服务器 retries 3 #设置尝试次数,3次连接失败则认为服务器不可用 maxconn 2048 #最大连接数 contimeout 5000 #连接超时 clitimeout 50000 #客户端超时 srvtimeout 50000 #服务器超时 timeout check 2000 #心跳检测超时 listen status 0.0.0.0:8080 #定义状态名字和监听端口 stats uri /haproxy-status #查看haproxy服务器状态地址 stats auth admin:admin #查看状态页面的用户名和密码 stats hide-version #隐藏haproxy版本信息 stats refresh 30s #每5秒刷新一次状态页面 listen web_server 0.0.0.0:80 #定义后端名字和监听端口 mode http #采用7层模式 balance roundrobin #负载均衡算法,这里是轮叫 cookie SERVERID #允许插入serverid到cookie中,serverid后面可以定义 option httpchk GET /index.html #健康检测 server web1 192.168.1.11:80 weight 3 check inter 500 fall 3 server web2 192.168.1.12:80 weight 2 check inter 500 fall 3
说明:用server来设置后端服务器
第二段:haproxy自己的一个名称,将在日志中显示
第三段:后端IP和端口
第四段:权重值,权重值越大,分配的任务几率越高
第五段:健康检测,inter 500健康检测间隔是500毫秒
最后一段:检测多少次,认为服务器是不可用的
启动haproxy
[root@localhost ~]# /usr/local/haproxy/sbin/haproxy -f /usr/local/haproxy/conf/haproxy.cfg
重启haproxy
[root@localhost ~]# /usr/local/haproxy/sbi n/haproxy -f /usr/local/haproxy/conf/haproxy.cfg -st `cat/var/run/haproxy.pid`
写一个简单的haproxy服
[root@localhost ~]# vi /etc/init.d/haproxy #!/bin/bash DIR=/usr/local/haproxy PIDFILE=/var/run/haproxy.pid ARG=$* start() { echo "Starting Haproxy ..." $DIR/sbin/haproxy -f $DIR/conf/haproxy.cfg } stop() { echo "Stopping Haproxy ..." kill -9 $(cat $PIDFILE) } case $ARG in start) start ;; stop) stop ;; restart) stop start ;; *) echo "Usage: start|stop|restart"
#设置开机启动
[root@localhost ~]# chmod +x/etc/init.d/haproxy [root@localhost ~]# echo "/etc/init.d/haproxy start" >> /etc/rc.local
#查看服务器状态
http://192.168.1.10:8080/

配置haproxy日志输出
[root@localhost ~]# vi /etc/rsyslog.conf #在下面添加 local3.* /var/log/haproxy.log local0.* /var/log/haproxy.log [root@localhost ~]# service rsyslog restart
后端web服务器配置相同
[root@localhost ~]# yum install httpd –y [root@localhost ~]# service httpd start [root@localhost ~]# echo "web1/web2" > /var/www/html/index.html
测试:访问http://192.168.1.10,按F5一直刷新会显示轮训显示web1和web2,模拟web1故障down机,haproxy页面显示的状态会变成DOWN,只有web2提供服务,当web1恢复后会自动加入集群中。