介绍
鲍鱼是一种贝类,在世界许多地方都被视为美味佳肴。
养殖者通常会切开贝壳并通过显微镜计算环数来估计鲍鱼的年龄。因此,判断鲍鱼的年龄很困难,主要是因为它们的大小不仅取决于它们的年龄,还取决于食物的供应情况。而且,鲍鱼有时会形成所谓的“发育不良”种群,其生长特征与其他鲍鱼种群非常不同。这种复杂的方法增加了成本并限制了其普及。我们在这份报告中的目标是找出最好的指标来预测鲍鱼的环,然后是鲍鱼的年龄。
数据集
背景介绍
这个数据集来自一项原始(非机器学习)研究。
从原始数据中删除了有缺失值的例子(大多数预测值缺失),连续值的范围被缩放用于NA(通过除以200)。在本分析中,我们将通过乘以200的方式将这些变量恢复到其原始形式。
数据集中的观测值总数:4176
数据集中的变量总数:8个
变量列表
| 变量 | 数据类型 | 测量 | 描述 |
| 性别 | 分类(因子) | M、F 和 I(婴儿) | |
| 长度 | 连续 | 毫米 | 最长壳测量 |
| 直径 | 连续 | 毫米 | 垂直长度 |
| 高度 | 连续 | 毫米 | 带壳肉 |
| 整体重量 | 连续 | 克 | 整只鲍鱼 |
| 去壳重量 | 连续 | 克 | 肉的重量 |
| 内脏重量 | 连续 | 克 | 肠道重量 |
| 外壳重量 | 连续 | 克 | 晒干后 |
| 鲍鱼的环 | 连续 | +1.5 给出以年为单位的年龄 |
下面是分析
“使用回归预测鲍鱼的年龄”
数据汇总与统计
balne


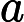
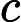

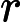

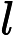
 Sx<−s.acor(aalneSx <- s.acor(aalneSex)
Sx<−s.acor(aalneSx <- s.acor(aalneSex)

kale(abaoe\[1:10,\],fomt 'madw')

分类变量

数值变量

看一下数据集的摘要,我们可以看到,数据在雄性、雌性和婴儿这三个因素水平之间的分布是相当均匀的。
因变量
因果变量Rings包含在数据集中。它被测量为切割和检查鲍鱼后观察到的环的数量。虽然它不能直接表示一个给定的鲍鱼的年龄,但它可以或多或少完美地确定它。一个鲍鱼的年龄等于环数+1.5。由于这种关系是可靠的,环数将被视为因变量。数据中测量的环数从1到29不等,大多数鲍鱼的环数在5到15之间。分布也有轻微的正偏斜,但没有问题。(见下面的图)
配对图
pairs(aalone, es(colour =Sex, aph = 0.)

从配对图中观察到的情况。
首先要注意的是数据的高度相关性。例如,直径和长度之间的相关性非常高(约98.7)。
01

02

03

04

同样,Whole\_weight似乎与其他重量预测因子高度相关,是Shucked\_weight、Viscera\_weight和Shell\_weight之和。
其次,预测因子Sex的分布与所有其他预测因子的因子水平值雌性和雄性非常相似。
对于雌性和雄性的因子水平,分布的形状也是非常相似的。
我们可以考虑重新定义这一特征,将性别定义为婴儿与非婴儿(其中非婴儿=雌性和雄性都是)。
大多数的abalones环都在5到15之间。
数据质量
增加变量。我们将更新鲍鱼数据集,创建名为 "婴儿 "的新变量,它的值将基于性别变量的原始值。当性别变量为I时,它的值为I,否则为NI。
我们还观察到,预测高度的最小值是0,实际上这是不可能的,我们将调查这些观察结果,仔细研究。
##高度为0的数据质量检查 kable(abloe\[aban$Height == 0,\])

我们看到,有两个观测值的高度可能没有被正确记录,因为其他预测因子似乎都有有效的值。另外,如果我们看一下预测因子Whole_weight,我们会发现这些值与其他观察值相比真的很小,而且低于第一个四分法。这告诉我们,这可能不是一个数据错误,因此我们不能将这些数据从我们的数据集中排除。
我们还将添加一个名为weight.diff的新变量。我们可以在摘要中看到有四种不同的重量测量方法,即Whole\_weight、Shucked\_weight、Viscera\_weight和Shell.weight。Whole\_weight是其他重量预测因子的线性函数,在剥壳过程中损失的水/血的质量未知。
str(aane, give.attr= FASE)

我们看到变量Whole\_weight应该是Shucked\_weight、Viscersa\_weight和Shell\_weight的线性函数,我们可以写成Whole\_weight = Shucked\_weight + Viscera\_weight + Shell\_weight + 剥壳过程中损失的未知水/血质量。
然而,当我们计算Whole_weight和其他重量变量之间的差异时,我们发现有153个观测值违反了这一规定,也就是说,这似乎不符合逻辑,可能是记录数据时的错误。
如果我们绘制新添加的weight.diff变量的直方图,我们可以看到,当weight.diff为负数时,有一些观察结果。
#确定没有正确记录的观察结果 #不符合逻辑的观察结果的柱状图 ggplt(aalone, as(x=weight.diff)) +,ill=rb(1,.4,0,.7), bins = 30)

我们来看看其中的一些记录。
nrow(ablon\[abaoneweihtdff < 0,\])


请注意,总共有153个观测值的综合权重超过了Whole_weight。当我们看了10个这样的观测值时,似乎其他的值都是正确的,没有任何相似之处,所以我们确信这可能是一个数据输入错误。因此,我们将保留这些观察结果,以便进一步分析。
我们将首先在训练和测试中潜入我们的数据集。数据集将以70/30的比例在训练和测试之间进行分割,并随机选择观测值。
训练和测试拆分
set.ee(4) #使用70/30方法在训练和测试中分割数据 ndxes <-spl(1:owabaone, size= 0.3 nrw(bone)) aboetrai <- ablon\[-indxs,\] abetest <- abloneindxe,\]
我们已经开始用所有的变量拟合一个加法模型,并将研究参数的重要性。在此基础上,我们将修改我们的模型。现在我们将使用变量Sex的原始值,它的因子水平为F、I和M。
加性多元线性回归模型
summary(abneadd)

在第一个加性模型中,注意因子水平雌性是性别变量的参考水平。
在用所有预测因子拟合加性模型后,我们可以看到,除了长度之外,测试统计显示所有变量都是显著的。正如我们之前从配对图中看到的那样,长度和直径的预测因子是高度相关的。我们还看到,不同重量的预测因子也是显著的,尽管它们应该是彼此的线性函数。
RMSE 分数
kable(rmse(aaloe_ad,"Aditve odel"))

我们将计算方差膨胀因子,以发现数据集存在的多重共线性问题。
多重共线性
vif

我们看了所有变量的变量膨胀系数,似乎所有的预测因子都有多重共线性问题,除了我们之前在配对图中看到的性别和身高。预测因子Whole_weight的VIF值最高,因为它是其他体重的线性函数。
Whole_weight & Rings 之间的偏相关系数:我们将首先计算Whole_weight 变量和因变量(Rings)的偏相关系数 。
#检查高共线性关系变量的异方差性 wole\_wigt\_it <- lm(holweight ~Sx LnhDametr + eit +Sucked\_ght + Visrwght Shl\_wegh data=alotrin)
变量添加图
同样地,变量添加图将这些残差相互之间的关系可视化。将因变量的残差与预测的残差进行回归,并将回归线添加到图中,也是有帮助的。
cor(resid(whole_weight),resid(addwtouwolwigh))

cre\_plot(baead\_itht\_whe\_eght,wleeghtfit)

没有Whole_weight的加法模型的方差膨胀因子
但直径和长度的VIF还是很高。
vif(abaln\_ddithu\_whoeeiht)

直径和环之间的偏相关系数
我们现在将 在模型中Diameter 没有Whole_weight变量的情况下计算变量和因变量(环) 的偏相关系数 。
mete\_i <- lm(Diameter ~ Sex + Length + Height + Shucked\_weight + Viscera\_weight + Shell\_weight) abaoned\_sal <- lm(Rings ~ Sex + Length + Height + Shucked\_weight + Viscera\_weight + Shell\_weight)
这两个残差的相关性接近于零,这意味着未被性别、长度、高度、去壳重量、内脏重量和贝壳重量解释的环的变化与未被性别、长度、高度、去壳重量、内脏重量和贝壳重量解释的直径的变化的相关性很小。因此,在模型中加入直径可能没有什么好处。
cor(resid(damer\_it),resid(abonead\_mll))

creaevarlt(ablone\_d\_smaldiaete_fi)

没有 Whole_weight & Diameter 的加法模型的方差膨胀因子
vif(ablonadd_mll)

现在的VIF要低得多。我们将同时使用abalone\_add和abalone\_add_small进行分析。
abalone\_add\_small 的 RMSE 分数
kable(rmse(abalone\_add\_small

用加性多元线性回归、随机森林、弹性网络模型预测鲍鱼年龄和可视化(二)https://developer.aliyun.com/article/1485798
