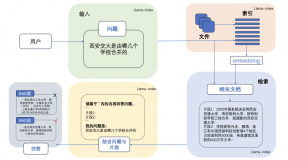
一 背景
RAG技术全称为检索增强生成技术(Retrieval Augmented Generation),是一种向LLM提供从特定数据源检索的信息的技术。简而言之,RAG结合了搜索和LLM的提示功能,在此基础上,模型根据搜索算法提供的信息,作为上下文来回答问题。这些查询和检索到的上下文会一并被注入到发送给LLM的提示中。RAG技术的出现,主要解决了以下问题:
- 大模型的幻觉问题:大模型幻觉指模型输出的“事实性”内容中包含虚假、误导性信息。通过RAG可以解决可解释性、信息溯源、信息验证证等问题,一旦检索的内容和生成的内容建立的关系,可以知道LLM模型根据哪些信息得出的回答。
- 与真实世界实时交互问题:RAG可以帮助模型对自身知识进行动态更新,同时,帮助模型在执行指令时,实时补全空白知识。
- 数据问题:私有数据安全问题,RAG技术可以将私有数据作为一个外部数据库,让LLM在回答私有数据问题时候,直接从该数据库中提取信息。
- 知识的动态性问题:目前LLM存在偏见、幻觉、时效性等问题(由于只是按照概率空间进行输出),RAG的外部检索很好的解决了这一问题,从而保持了模型的时效性和准确性。
二 向量介绍
其中在做大模型RAG相关的应用中,我们经常需要用到向量的概念,包括向量数据库和向量检索。对于没接触过的人可能比较懵。本文介绍下文本向量化的概念,以及向量检索的原理,只是简单介绍,不做深入。
1. 向量介绍
文本向量化是将文本数据转换为数值向量的过程。它的目的是将文本信息表示为机器可以处理和分析的形式。在自然语言处理中,文本通常是由字符串组成的,例如句子、段落或文档。然而,计算机程序很难直接理解和处理文本数据。文本向量化的作用就是将这些文本转换为数值向量,使得计算机可以对其进行数学运算和分析。通过文本向量化,我们可以将文本数据用于各种任务,如文本分类、情感分析、信息检索、机器翻译等。它使得计算机能够处理和理解自然语言,并从中提取有意义的信息。
2. 文本向量生成
通义千问提供了文本向量的模型,是基于LLM底座的多语言文本统一向量模型,面向全球多个主流语种,提供高水准的向量服务,可以将文本数据快速转换为高质量的向量数据。详情可以参考官网介绍:https://help.aliyun.com/zh/dashscope/developer-reference/text-embedding-quick-start
其中我们用的比较多的是text-embedding-v1模型,我们可以通过官网代码进行快速验证调用。
import dashscope from http import HTTPStatus def embed_with_str(): resp = dashscope.TextEmbedding.call( model=dashscope.TextEmbedding.Models.text_embedding_v1, input='测试') if resp.status_code == HTTPStatus.OK: print(resp) else: print(resp) if __name__ == '__main__': embed_with_str()
可以测试一下这个接口,看下这个接口输出的向量长什么样。

可以看到 “测试” 这四个字对应的输出是一个 1536 维的向量,这就是 “测试” 的向量表示,和官网说明的向量维度大小一致。

3.向量相似度计算和向量检索
3.1 向量相似度
向量相似度是一种用于衡量两个向量之间相似程度的度量方法。它通常用于比较不同对象或数据的相似性,例如文本、图像、音频等。常见的向量相似度度量方法包括:
① 欧几里得距离:计算两个向量之间的欧几里得距离,距离越小表示相似度越高。
② 余弦相似度:通过计算两个向量的余弦值来衡量它们的相似性。余弦值接近 1 表示相似度高,接近 0 表示相似度低。
③ 曼哈顿距离:计算两个向量在各个维度上的绝对差值的总和,曼哈顿距离越小表示相似度越高。
Jaccard 相似系数:适用于集合或布尔向量的相似度度量,计算两个集合的交集与并集的比值。
④ 皮尔逊相关系数:衡量两个向量的线性相关程度,相关系数的值在-1 到 1 之间,-1 表示完全负相关,1 表示完全正相关。
选择合适的向量相似度度量方法取决于数据的特点和具体的应用场景。不同的度量方法可能对不同类型的向量数据表现出不同的效果。在实际应用中,通常需要根据数据的分布、特征和需求来选择最适合的相似度度量方法。
3.2 向量检索
向量检索是一种在数据库中查找最相似向量的技术。对于诸如图片、视频、音频等非结构化数据,传统数据库方式无法进行处理。目前,通用的技术是把非结构化数据通过一系列 embedding 模型将它变成向量化表示,然后将它们存储到数据库或者特定格式里。在搜索过程中,通过相同的一个模型把查询项转化成对应的向量,并进行一个近似度的匹配就可以实现对非结构化数据的查询。
3.3 两者差别
在对向量使用过程中,经常需要使用到向量检索和向量相似度计算。
向量检索主要关注在大规模数据集中快速找到与给定向量最相似的向量。它通常涉及建立索引结构、使用高效的搜索算法来查找最接近的向量。向量检索的目的是快速定位相似的向量,而不一定计算出具体的相似度值。
相似度计算则更侧重于定量地衡量两个向量之间的相似程度。它可以使用各种相似度度量方法,如欧几里得距离、余弦相似度等,来计算两个向量的相似性得分。相似度计算给出了一个具体的数值,表示两个向量的相似程度。
简单来说,向量检索是找到最相似的向量,而相似度计算是定量评估相似程度。在实际应用中,常常先进行向量检索,找到候选的相似向量,然后再对这些候选向量进行相似度计算,以确定它们的具体相似程度。
例如,在一个图像检索系统中,向量检索可以帮助快速找到与查询图像最相似的一批候选图像,然后可以对这些候选图像进行进一步的相似度计算,以确定它们与查询图像的相似度得分,并按照得分排序展示给用户。
三 RAG常见架构
常见的RAG应用主要包括以下步骤。
1.索引(Indexing)

加载(Load):首先,我们需要加载我们的数据,这里主要使用 DocumentLoaders 完成。
拆分(Split):文本拆分器将大型文档拆分成较小的块。这对于索引数据和将其传递给模型都很有用,因为大的块更难搜索,而且不适合模型的有限上下文窗口。
存储(Store):我们需要有地方存储和索引我们的拆分后的文档,以便以后可以对其进行搜索。这通常使用 VectorStore 和 Embeddings 模型来完成。
2.检索和生成(Retrieval and generation)
检索(Retrieve):借助词向量的相似度找到与用户提出的问题最匹配的内容。
生成(Generate):直接向语言模型提供增强知识来指导其产出更符合语境的回答。

四 demo学习
1. demo代码
# Load, chunk and index the contents of the blog. loader = WebBaseLoader( web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",), bs_kwargs=dict( parse_only=bs4.SoupStrainer( class_=("post-content", "post-title", "post-header") ) ), ) docs = loader.load() text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200) splits = text_splitter.split_documents(docs) vectorstore = Chroma.from_documents(documents=splits, embedding=OpenAIEmbeddings()) # Retrieve and generate using the relevant snippets of the blog. retriever = vectorstore.as_retriever() prompt = hub.pull("rlm/rag-prompt") llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0) def format_docs(docs): return "\n\n".join(doc.page_content for doc in docs) rag_chain = ( {"context": retriever | format_docs, "question": RunnablePassthrough()} | prompt | llm | StrOutputParser() ) print("开始打印prompt") prompt = rag_chain.get_prompts()[0].pretty_print() print("结束打印prompt") response = rag_chain.invoke("What is Task Decomposition?") print("返回结果:" + response)
通过官网提供的示例代码可以学习RAG的基本流程,这段代码的目的是从指定的网页中提取相关信息,将其分割成块,使用向量表示,并通过检索链与提示和语言模型进行交互,最后打印响应。
运行后结果如下:

接下来我们一步步学习这段代码。
2. indexing:loading
# Only keep post title, headers, and content from the full HTML. bs4_strainer = bs4.SoupStrainer(class_=("post-title", "post-header", "post-content")) loader = WebBaseLoader( web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",), bs_kwargs={"parse_only": bs4_strainer}, ) docs = loader.load()
这段代码是在使用 BeautifulSoup4 库来过滤和加载特定类别的 HTML 元素。
- bs4.SoupStrainer :这是一个 BeautifulSoup4 的过滤器对象,它根据指定的类名来筛选 HTML 元素。在这里,通过设置 class_=("post-title", "post-header", "post-content"),只选择具有这些类名的元素。
- WebBaseLoader :这是一个用于从网络加载数据的加载器。通过设置 web_paths 参数为指定的 URL,加载器将从该 URL 获取数据。
- bs_kwargs:这是一个字典,用于传递参数给 BeautifulSoup4 的解析器。在这里,通过设置 parse_only 参数为 bs4_strainer,意味着只解析满足过滤器条件的元素。
最后,通过调用 loader.load(),可以加载并获取符合条件的文档(docs)。
通过打印我们可以看到具体的返回内容
print(len(docs[0].page_content)) print("打印文档的数据:"+docs[0].page_content[:500])

3. Indexing: Split
通过上面抓取的文档可以看到很长,已经远远超过了大模型可以接受的大小。为了解决这样的问题,需要对数据进行拆分。拆分相关代码如下:
text_splitter = RecursiveCharacterTextSplitter( chunk_size=1000, chunk_overlap=200, add_start_index=True ) splits = text_splitter.split_documents(docs)
这段代码是在设置并使用 RecursiveCharacterTextSplitter 来分割文档。
- RecursiveCharacterTextSplitter 是一个文本分隔器,它根据指定的参数将文档分割成块。
chunk_size=1000 表示每个块的大小为 1000 个字符。
chunk_overlap=200 表示块之间有 200 个字符的重叠。
add_start_index=True 表示是否为每个块添加起始索引。
- split_documents(docs) 方法用于对 docs 进行分割。它会将文档按照设置的参数分割成多个块,并返回这些块。
这样,splits 就会包含按照指定参数分割后的文档块。这些块可以用于进一步的处理或分析。例如,可以将它们逐个处理,或者将它们作为输入提供给其他模型或算法。
len(splits)

通过调试发现,在处理后,一共分成了66个分组。
4. Indexing: Store
现在我们需要为 66 个文本块建立索引,以便在运行时可以对它们进行搜索。最常见的方法是为每个分割文档的内容生成向量,并将这些嵌入插入到向量数据库(或向量存储)中,本次案例中,使用的是Chroma向量数据库,当我们想要在进行搜索时,传入一个文本搜索查询,对其进行向量化,并执行“向量相似度”搜索,以识别与我们的查询嵌入最相似的模块。代码如下:
vectorstore = Chroma.from_documents(documents=all_splits, embedding=OpenAIEmbeddings())
至此我们完成了整个RAG的Indexing阶段。
5. Retrieval
retriever = vectorstore.as_retriever(search_type="similarity", search_kwargs={"k": 6})
这行代码是在创建一个检索器(retriever),它使用了一个向量存储(vectorstore),并指定了搜索类型为"similarity"(相似度搜索),同时还设置了一些搜索关键字参数。其中search_kwargs 字典中设置了 k 参数为 6,这表示在进行相似度搜索时,返回最相似的 6 个结果。这样,通过创建这个检索器,你可以在后续的操作中使用它来进行相似度搜索,并获取与给定查询最相似的 6 个结果。这个检索器将根据你提供的向量数据和搜索参数来执行搜索操作。
6. Generate
其中关于提示词,代码里使用了hub接口里的"rlm/rag-prompt"prompt, hub是langSmith提供的一个提示词库,里面有很多已经写好的提示词可以参考使用。
可以通过官网查看对应的提示词,地址:https://smith.langchain.com/hub/rlm/rag-prompt

或者也可以通过代码pretty_print实时打印具体的提示词。
同时提示词也可以自己定制, 如下图所示:
template = """Use the following pieces of context to answer the question at the end in chinese. If you don't know the answer, just say that you don't know, don't try to make up an answer. Use three sentences maximum and keep the answer as concise as possible. Always say "thanks for asking!" at the end of the answer. {context} Question: {question} Helpful Answer:""" # 自定义的prompt custom_rag_prompt = PromptTemplate.from_template(template) rag_chain = ( {"context": retriever | format_docs, "question": RunnablePassthrough()} | custom_rag_prompt | llm | StrOutputParser() )
比如在自定义的prompt加上使用中文打印,可以看到结果已经全是中文输出

五 总结
综上所述,一个简单的基于大模型的RAG应用讲解完了,包含了RAG常见的模块,比如loading,spilt,store, prompt等。其实在实际业务过程中,远比我们的上面讲解的要复杂,尤其是在loading和spilt阶段,如何从企业大量复杂的数据中,清洗出合适的数据,成为衡量RAG应用的成功关键。后续我们会继续深入研究这块内容。