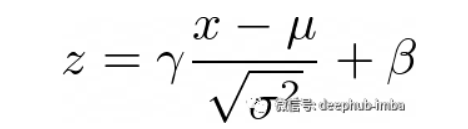归一化层是深度神经网络体系结构中的关键,在训练过程中确保各层的输入分布一致,这对于高效和稳定的学习至关重要。归一化技术的选择(Batch, Layer, GroupNormalization)会显著影响训练动态和最终的模型性能。每种技术的相对优势并不总是明确的,随着网络体系结构、批处理大小和特定任务的不同而变化。
本文将使用合成数据集对三种归一化技术进行比较,并在每种配置下分别训练模型。记录训练损失,并比较模型的性能。

神经网络中的归一化层是用于标准化网络中某一层的输入的技术。这有助于加速训练过程并获得更好的表现。有几种类型的规范化层,其中 Batch Normalization, Layer Normalization, Group Normalization是最常见的。
常见的归一化技术
BatchNorm
BN应用于一批数据中的单个特征,通过计算批处理上特征的均值和方差来独立地归一化每个特征。它允许更高的学习率,并降低对网络初始化的敏感性。
这种规范化发生在每个特征通道上,并应用于整个批处理维度,它在大型批处理中最有效,因为统计数据是在批处理中计算的。
LayerNorm
与BN不同,LN计算用于归一化单个数据样本中所有特征的均值和方差。它应用于每一层的输出,独立地规范化每个样本的输入,因此不依赖于批大小。
LN有利于循环神经网络(rnn)以及批处理规模较小或动态的情况。
GroupNorm
GN将信道分成若干组,并计算每组内归一化的均值和方差。这对于通道数量可能很大的卷积神经网络很有用,将它们分成组有助于稳定训练。
GN不依赖于批大小,因此适用于小批大小的任务或批大小可以变化的任务。
每种规范化方法都有其优点,并且根据网络体系结构、批处理大小和训练过程的特定需求适合不同的场景:
BN对于具有稳定和大批大小的网络非常有效,LN对于序列模型和小批大小是首选,而GN提供了对批大小变化不太敏感的中间选项。
代码示例
我们演示了使用PyTorch在神经网络中使用三种规范化技术的代码,并且绘制运行的结果图。
首先是生成数据
importtorch
importtorch.nnasnn
importtorch.optimasoptim
importnumpyasnp
importmatplotlib.pyplotasplt
fromtorch.utils.dataimportDataLoader, TensorDataset
# Generate a synthetic dataset
np.random.seed(42)
X=np.random.rand(1000, 10)
y= (X.sum(axis=1) >5).astype(int) # simple threshold sum function
X_train, y_train=torch.tensor(X, dtype=torch.float32), torch.tensor(y, dtype=torch.int64)
# Create a DataLoader
dataset=TensorDataset(X_train, y_train)
loader=DataLoader(dataset, batch_size=64, shuffle=True)
然后是创建模型,这里将三种方法写在一个模型中,初始化时只要传递不同的参数就可以使用不同的归一化方法
# Define a model with Batch Normalization, Layer Normalization, and Group Normalization
classNormalizationModel(nn.Module):
def__init__(self, norm_type="batch"):
super(NormalizationModel, self).__init__()
self.fc1=nn.Linear(10, 50)
ifnorm_type=="batch":
self.norm=nn.BatchNorm1d(50)
elifnorm_type=="layer":
self.norm=nn.LayerNorm(50)
elifnorm_type=="group":
self.norm=nn.GroupNorm(5, 50) # 5 groups
self.fc2=nn.Linear(50, 2)
defforward(self, x):
x=self.fc1(x)
x=self.norm(x)
x=nn.ReLU()(x)
x=self.fc2(x)
returnx
然后是训练的代码,我们也简单的封装下,方便后面调用
# Training function
deftrain_model(norm_type):
model=NormalizationModel(norm_type=norm_type)
criterion=nn.CrossEntropyLoss()
optimizer=optim.Adam(model.parameters(), lr=0.001)
num_epochs=50
losses= []
forepochinrange(num_epochs):
forinputs, targetsinloader:
optimizer.zero_grad()
outputs=model(inputs)
loss=criterion(outputs, targets)
loss.backward()
optimizer.step()
losses.append(loss.item())
returnlosses
最后就是训练,经过上面的封装,我们直接循环调用即可
# Train and plot results for each normalization
norm_types= ["batch", "layer", "group"]
results= {}
fornorm_typeinnorm_types:
losses=train_model(norm_type)
results[norm_type] =losses
plt.plot(losses, label=f"{norm_type} norm")
plt.xlabel("Iteration")
plt.ylabel("Loss")
plt.title("Normalization Techniques Comparison")
plt.legend()
plt.show()
生成的图表将显示每种归一化技术如何影响有关减少损失的训练过程。我们可以解释哪种归一化技术对这个特定的合成数据集和训练设置更有效。我们的评判标准是通过适当的归一化实现更平滑和更快的收敛。

BN(蓝色)、LN(橙色)和GN(绿色)。
所有三种归一化方法都以相对较高的损失开始,并迅速减小。
可以看到BN的初始收敛速度非常的快,但是到了最后,损失出现了大幅度的波动,这可能是因为学习率、数据集或小批量选择的随机性质决定的,或者是模型遇到具有不同曲率的参数空间区域。我们的batch_size=64,如果加大这个参数,应该会减少波动。
LN和GN的下降平稳,并且收敛速度和表现都很类似,通过观察能够看到LN的方差更大一些,表明在这种情况下可能不太稳定
最后所有归一化技术都显著减少了损失,但是因为我们使用的是生成的数据,所以不确定否都完全收敛了。不过虽然该图表明,最终的损失值很接近,但是GN的表现可能更好一些。
总结
在这些规范化技术的实际应用中,必须考虑任务的具体要求和约束。BatchNorm在大规模批处理可行且需要稳定性时更可取。LayerNorm在rnn和具有动态或小批量大小的任务的背景下可以发挥作用。GroupNorm提供了一个中间选项,在不同的批处理大小上提供一致的性能,在cnn中特别有用。
归一化层是现代神经网络设计的基石,通过了解BatchNorm、LayerNorm和GroupNorm的操作特征和实际含义,根据任务需求选择特定的技术,可以在深度学习中实现最佳性能。
https://avoid.overfit.cn/post/e8ec905659e5446e84fb9617feb86e95