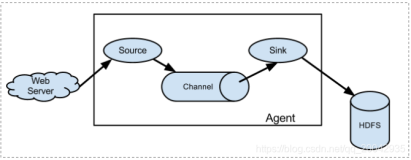
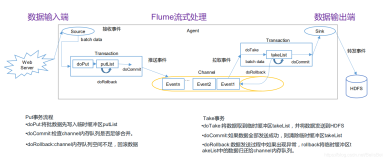
Flume常用的拓扑结构
Apache Flume 是一个开源的、分布式的数据收集和传输系统,广泛应用于大数据领域。在 Flume 中,通过配置不同的组件和拓扑结构,可以实现各种数据收集和传输的场景。本文将介绍 Flume 中常用的几种拓扑结构,并提供相应的示例代码,以帮助读者更好地理解和应用 Flume。
1. 单节点拓扑结构
单节点拓扑结构是 Flume 中最简单的一种拓扑结构,由一个 Flume Agent 组成,用于从数据源收集数据,并将数据传输到目的地。单节点拓扑结构适用于数据量较小、单一数据源的场景,具有简单、易于管理的特点。
示例代码:
# 定义 Flume 代理名称和组件
agent.sources = avro-source
agent.sinks = logger-sink
agent.channels = memory-channel
# 配置 Source:使用 AvroSource 接收数据
agent.sources.avro-source.type = avro
agent.sources.avro-source.bind = localhost
agent.sources.avro-source.port = 44444
# 配置 Sink:将数据写入日志
agent.sinks.logger-sink.type = logger
# 配置 Channel:内存通道
agent.channels.memory-channel.type = memory
agent.channels.memory-channel.capacity = 10000
# 将 Source 和 Sink 以及 Channel 进行绑定
agent.sources.avro-source.channels = memory-channel
agent.sinks.logger-sink.channel = memory-channel
2. 多节点拓扑结构
多节点拓扑结构是由多个 Flume Agent 组成的拓扑结构,用于处理数据量较大、多个数据源的场景。每个 Flume Agent 都负责从不同的数据源收集数据,并将数据传输到下一个 Flume Agent 或目的地。多节点拓扑结构具有分布式、可扩展的特点,适用于大规模数据收集和传输的场景。
示例代码:
Agent1 配置文件:
# 定义 Flume 代理名称和组件
agent.sources = avro-source
agent.sinks = avro-sink
agent.channels = memory-channel
# 配置 Source:使用 AvroSource 接收数据
agent.sources.avro-source.type = avro
agent.sources.avro-source.bind = localhost
agent.sources.avro-source.port = 44444
# 配置 Sink:将数据传输到 Agent2
agent.sinks.avro-sink.type = avro
agent.sinks.avro-sink.hostname = Agent2Hostname
agent.sinks.avro-sink.port = 44445
# 配置 Channel:内存通道
agent.channels.memory-channel.type = memory
agent.channels.memory-channel.capacity = 10000
# 将 Source 和 Sink 以及 Channel 进行绑定
agent.sources.avro-source.channels = memory-channel
agent.sinks.avro-sink.channel = memory-channel
Agent2 配置文件:
# 定义 Flume 代理名称和组件
agent.sources = avro-source
agent.sinks = logger-sink
agent.channels = memory-channel
# 配置 Source:接收来自 Agent1 的数据
agent.sources.avro-source.type = avro
agent.sources.avro-source.bind = 0.0.0.0
agent.sources.avro-source.port = 44445
# 配置 Sink:将数据写入日志
agent.sinks.logger-sink.type = logger
# 配置 Channel:内存通道
agent.channels.memory-channel.type = memory
agent.channels.memory-channel.capacity = 10000
# 将 Source 和 Sink 以及 Channel 进行绑定
agent.sources.avro-source.channels = memory-channel
agent.sinks.logger-sink.channel = memory-channel
3. 多层级拓扑结构
多层级拓扑结构是由多个 Flume Agent 组成的层级结构,用于处理复杂的数据收集和传输场景。每个 Flume Agent 负责特定的数据收集和传输任务,并将数据传输给上一层或下一层的 Flume Agent。多层级拓扑结构具有灵活、可配置的特点,适用于多种数据源和目的地的场景。
示例代码:
Agent1 配置文件:
# 定义 Flume 代理名称和组件
agent.sources = avro-source
agent.sinks = avro-sink
agent.channels = memory-channel
# 配置 Source:使用 AvroSource 接收数据
agent.sources.avro-source.type = avro
agent.sources.avro-source.bind = localhost
agent.sources.avro-source.port = 44444
# 配置 Sink:将数据传输到 Agent2
agent.sinks.avro-sink.type = avro
agent.sinks.avro-sink.hostname = Agent2Hostname
agent.sinks.avro-sink.port = 44445
# 配置 Channel:内存通道
agent.channels.memory-channel.type = memory
agent.channels.memory-channel.capacity = 10000
# 将 Source 和 Sink 以及 Channel 进行绑定
agent.sources.avro-source.channels = memory-channel
agent.sinks.avro-sink.channel = memory-channel
Agent2 配置文件:
# 定义 Flume 代理名称和组件
agent.sources = avro-source
agent.sinks = hdfs-sink
agent.channels = memory-channel
# 配置 Source:接收来自 Agent1 的数据
agent.sources.avro-source.type = avro
agent.sources.avro-source.bind = 0.0.0.0
agent.sources.avro-source.port = 44445
# 配置 Sink:将数据写入 HDFS
agent.sinks.hdfs-sink.type = hdfs
agent.sinks.hdfs-sink.hdfs.path = /flume/events
# 配置 Channel:内存通道
agent.channels.memory-channel.type = memory
agent.channels.memory-channel.capacity = 10000
# 将 Source 和 Sink 以及 Channel 进行绑定
agent.sources.avro-source.channels = memory-channel
agent.sinks.hdfs-sink.channel = memory-channel