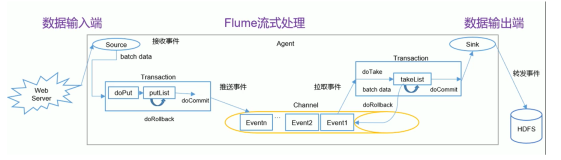
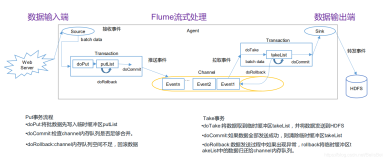
Flume的事务机制

Apache Flume 是一个分布式的、可靠的数据收集和传输系统,它允许用户从各种数据源收集数据,并将数据传输到指定的目的地。在数据传输过程中,为了保证数据的可靠性和一致性,Flume 提供了事务机制。本文将深入探讨 Flume 的事务机制,包括其工作原理、关键概念和示例代码,以帮助读者更好地理解和应用 Flume。
1. 事务机制概述
Flume 的事务机制是指在数据传输过程中,为了确保数据的可靠性和一致性,Flume 会将数据传输过程分解为一系列的事务,并在每个事务中执行数据收集、传输和确认等操作。当一个事务成功完成时,数据将被安全地传输到目的地,并且该事务将被标记为已提交;而当一个事务失败时,数据将被回滚到之前的状态,并且该事务将被标记为已回滚。通过事务机制,Flume 能够在数据传输过程中实现故障恢复、数据重传等功能,从而确保数据的可靠传输。
2. 事务机制工作原理
Flume 的事务机制主要包括以下几个关键步骤:
事务划分:Flume 将数据传输过程划分为多个事务,并为每个事务分配一个唯一的事务 ID。
事务执行:在每个事务中,Flume 执行数据收集、传输和确认等操作。数据收集阶段负责从数据源收集数据,数据传输阶段负责将数据传输到目的地,数据确认阶段负责确认数据传输的结果。
事务状态管理:Flume 使用事务状态来跟踪每个事务的执行情况。事务状态包括已提交、已回滚等状态,用于标识事务的执行结果。
事务同步:在数据传输过程中,Flume 使用事务同步机制来确保所有的事务都按照顺序执行,并且保持一致性。通过事务同步,Flume 能够确保数据的顺序性和完整性。
事务恢复:当发生故障或中断时,Flume 能够通过事务恢复机制来重新执行失败的事务,从而实现故障恢复和数据重传。
3. 事务机制关键概念
在理解 Flume 的事务机制时,有几个关键概念需要特别注意:
事务ID(Transaction ID):每个事务都有一个唯一的事务 ID,用于标识该事务。事务 ID 在整个数据传输过程中起着重要的作用,用于跟踪事务的执行情况和状态。
事务状态(Transaction Status):每个事务都有一个状态,表示该事务的执行结果。常见的事务状态包括已提交、已回滚等。通过事务状态,Flume 能够判断事务的执行情况,并采取相应的措施。
事务同步(Transaction Synchronization):在数据传输过程中,Flume 使用事务同步机制来确保所有的事务都按照顺序执行,并且保持一致性。事务同步是保证数据传输过程中数据顺序性和完整性的关键机制之一。
事务恢复(Transaction Recovery):当发生故障或中断时,Flume 能够通过事务恢复机制来重新执行失败的事务,从而实现故障恢复和数据重传。事务恢复是保证数据传输过程中容错性和可靠性的关键机制之一。
4. 示例代码
下面是一个简单的 Flume 配置文件示例,演示了如何配置 Flume Agent 来使用事务机制进行数据传输:
# 定义 Flume 代理名称和组件
agent.sources = avro-source
agent.sinks = logger-sink
agent.channels = memory-channel
# 配置 Source:使用 AvroSource 接收数据
agent.sources.avro-source.type = avro
agent.sources.avro-source.bind = localhost
agent.sources.avro-source.port = 44444
# 配置 Sink:将数据写入日志
agent.sinks.logger-sink.type = logger
# 配置 Channel:内存通道
agent.channels.memory-channel.type = memory
agent.channels.memory-channel.capacity = 10000
# 将 Source 和 Sink 以及 Channel 进行绑定
agent.sources.avro-source.channels = memory-channel
agent.sinks.logger-sink.channel = memory-channel
在示例代码中,配置了一个 AvroSource 作为数据源,用于接收来自 Avro 客户端的数据;配置了一个 LoggerSink 作为数据目的地,用于将数据写入日志;配置了一个 MemoryChannel 作为通道,用于在 Source 和 Sink 之间传输数据。在数据传输过程中,Flume 将使用事务机制来确保数据的可靠性和一致性。
5. 总结
Flume 的事务机制是保证数据传输过程中可靠性和一致性的重要机制之一。通过将数据传输过程划分为多个事务,并使用事务状态管理、事务同步和事务恢复等机制,Flume 能够实现数据传输的故障恢复、数据重传等功能,从而确保数据的安全传输。