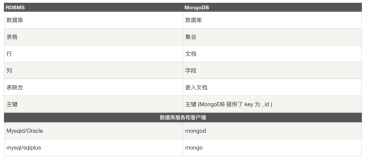
在MongoDB中,文档的嵌套层级没有明确的限制,但是过度嵌套文档可能会导致查询性能下降,增加数据更新的复杂性,并且不利于数据的维护和理解。因此,在设计Schema时,通常建议避免过度嵌套文档,最好不要超过一到两级的嵌套。
针对复杂的数据结构,可以考虑以下几种处理方法:
- 扁平化数据结构:将复杂的数据结构拆分成多个扁平化的文档。通过将相关数据分开存储在不同的文档中,并使用引用来关联它们,可以简化数据结构,提高查询性能和数据更新的效率。
示例代码片段:
// 用户文档
{
"_id": ObjectId("5fc48fb327a4ee3f9a5e5e42"),
"username": "john_doe",
"email": "john@example.com"
}
// 订单文档
{
"_id": ObjectId("5fc48fb327a4ee3f9a5e5e43"),
"user_id": ObjectId("5fc48fb327a4ee3f9a5e5e42"),
"products": [
{
"name": "Product 1",
"price": 10
},
{
"name": "Product 2",
"price": 20
}
]
}
- 使用数组:MongoDB支持数组类型,可以将一组相关数据存储在一个数组字段中。通过合理使用数组,可以减少文档的嵌套层级,从而简化数据结构。
示例代码片段:
// 用户文档
{
"_id": ObjectId("5fc48fb327a4ee3f9a5e5e42"),
"username": "john_doe",
"emails": [
"john@example.com",
"john.doe@example.com"
]
}
- 使用嵌套文档:在某些情况下,嵌套文档仍然是一种合适的数据结构。例如,当一组数据具有明确的层次结构并且经常一起使用时,嵌套文档可以更好地组织数据并简化查询操作。
示例代码片段:
// 博客文章文档
{
"_id": ObjectId("5fc48fb327a4ee3f9a5e5e44"),
"title": "MongoDB Schema Design",
"content": "Best practices for designing schemas in MongoDB",
"comments": [
{
"user": "Alice",
"comment": "Great article!"
},
{
"user": "Bob",
"comment": "Very informative."
}
]
}
- 使用多个集合:如果数据结构非常复杂,无法通过扁平化、数组或嵌套文档来处理,可以考虑将数据分散存储在多个集合中。通过合理划分数据,并使用引用来关联不同的集合,可以更好地组织和管理复杂的数据结构。
示例代码片段:
// 用户文档
{
"_id": ObjectId("5fc48fb327a4ee3f9a5e5e42"),
"username": "john_doe"
}
// 订单文档
{
"_id": ObjectId("5fc48fb327a4ee3f9a5e5e43"),
"user_id": ObjectId("5fc48fb327a4ee3f9a5e5e42"),
"products": [
ObjectId("5fc48fb327a4ee3f9a5e5e45"),
ObjectId("5fc48fb327a4ee3f9a5e5e46")
]
}
// 产品文档
{
"_id": ObjectId("5fc48fb327a4ee3f9a5e5e45"),
"name": "Product 1",
"price": 10
}
{
"_id": ObjectId("5fc48fb327a4ee3f9a5e5e46"),
"name": "Product 2",
"price": 20
}
- 使用Map数据类型:MongoDB 3.6及以上版本引入了Map数据类型,可以用来存储键值对类型的数据。对于一些动态、不确定字段数量的数据结构,Map类型可以提供更灵活的存储方式。
示例代码片段:
// 用户文档
{
"_id": ObjectId("5fc48fb327a4ee3f9a5e5e42"),
"username": "john_doe",
"properties": {
"age": 30,
"gender": "male"
}
}
- 使用文档验证规则:MongoDB 3.6及以上版本支持文档验证规则,可以定义文档的结构和约束条件。通过定义合适的验证规则,可以确保数据的一致性和完整性,从而简化对复杂数据结构的管理和维护。
示例代码片段:
// 创建用户集合并定义文档验证规则
db.createCollection("users", {
validator: {
$jsonSchema: {
bsonType: "object",
required: ["username", "email"],
properties: {
username: {
bsonType: "string",
description: "must be a string and is required"
},
email: {
bsonType: "string",
pattern: "^\\S+@\\S+$",
description: "must be a string and match the regular expression pattern"
}
}
}
}
})
在处理复杂的数据结构时,需要根据实际情况选择合适的方法。在设计Schema时,应该权衡查询性能、数据更新的复杂性、数据的维护和理解等因素,以找到最合适的数据模型。同时,需要注意避免过度设计和过度优化,保持数据模型的简单。