答案:
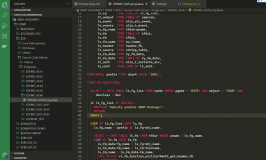
data:char. char = |{ cl_abap_conv_in_ce=>uccp( code ) WIDTH = 1 }|.
这段 ABAP 代码主要用于将一个给定的 Unicode 代码点转换成其对应的字符,并且限制输出的宽度为一个字符。这里,cl_abap_conv_in_ce=>uccp( code ) 是调用一个类方法,用于转换 Unicode 代码点到字符,而 WIDTH = 1 确保转换结果的宽度限制为 1。变量 char 用于存储转换后的字符。
示例说明:
假设有一个 Unicode 代码点 U+0041,它代表英文字母 A。通过这段代码,我们可以将这个代码点转换为对应的字符 A 并存储在变量 char 中。
代码解读如下:
data: char.这一行声明了一个变量char,用于存储转换后的字符。char = |{ cl_abap_conv_in_ce=>uccp( code ) WIDTH = 1 }|.这行代码实际执行转换操作。这里,code应该是一个变量或常量,包含了要转换的 Unicode 代码点。字符串模板|{ ... }|用于包含表达式结果,而cl_abap_conv_in_ce=>uccp( code )是调用静态方法uccp,将code对应的 Unicode 代码点转换成字符。WIDTH = 1确保输出结果的宽度为 1,这在处理某些需要固定宽度输出的场景中非常有用。
通过这种方式,ABAP 开发者可以在处理字符串或字符时,确保数据的准确性和适应性,特别是在需要处理国际化内容时。此代码段的应用场景包括但不限于字符验证、数据转换以及在特定情况下的格式化输出。
在实际应用中,开发者可能需要根据具体需求调整这段代码,比如处理多个字符的转换,或者在特定条件下进行字符的选择性转换。ABAP 作为一种专业的编程语言,为数据处理提供了丰富的内置函数和方法,cl_abap_conv_in_ce=>uccp() 方法只是其中的一个实例,展示了如何便捷地在 Unicode 编码和字符之间进行转换。