
概述
在前文,我列出以下几种解决方案:
- Rancher + K3s
- HashiCorp 解决方案 — Nomad + Docker
- Portainer + Docker
- Kubeedge
其中,Rancher + K3s 是基于且兼容 K8s 的解决方案;Kubeedge 是构建于 K8s 之上的,但是核心的 Kubeedge 架构是完全另外一套体系;而 Hashicorp 解决方案和 Portainer 解决方案可以说是和 K8s 没有关系,主要是基于 Docker 等容器的。而且也可以基于其他的驱动(如 podman 等等)
笔者基于边缘架构主要为:单片 arm 开发板 的情况,对以上的各个方案进行了深入的体验。
在深入体验另外 2 个容器平台:hashicorp nomad 和 portainer 时,明显感触到:相比 k8s k3s,这 2 个更适合物联网场景。(本章先抛开 KubeEdge 不谈,KubeEdge 我个人认为是适合更复杂的、和业务耦合更深或者需要调度边缘 AI 的高级边缘计算体系。)
K8s 不适合物联网,原因有:
- 资源占用高,
- 对网络要求高
- 网络模型复杂。
K3s 只是(部分)解决了资源占用的问题,但是后两个问题仍然存在。
📝Notes
K3s 是完全兼容 K8s 的发行版,从 1.23 之后,随着 K8s 功能的增加,K3s 也变得越来越重。
根据 K3s 安装要求:
- 对于 arm64 设备,操作系统必须使用 4k 页面大小;
- CPU/ 内存 最低是 1 核 512MB 内存,推荐是 2 核 1G; 但是实际应用场景中,要求会更高,一般内存都是 2G 起步。
- 更要命的是对存储的要求,K3s 默认启动需要的 K8s 镜像,差不多就需要占用 4-6 G 的空间,如果运行 etcd, 那么 SD 卡这种边缘场景常见的存储是无法满足的。
关于网络模型,近期 K3s 也添加了和 tailscale 整合 的功能以进一步简化网络模型。但是 K8s 自带的 主机网络 /Service IP/Cluster IP 是绕不过去的。
这两个,相比 k3s 都更轻量。而且对网络要求不高,甚至所有设备可以只用一套 server 端管理。
网络模型也很简单,主机网络就行。
此外,这两个针对物联网场景还有特殊优化,如 网络单向联通;边缘端断线情况下优化;支持管理非 docker 资源等等。
Rancher + K3s 模型在边缘存在的问题
在实际应用中,Rancher + K3s 的边缘部署架构如下:
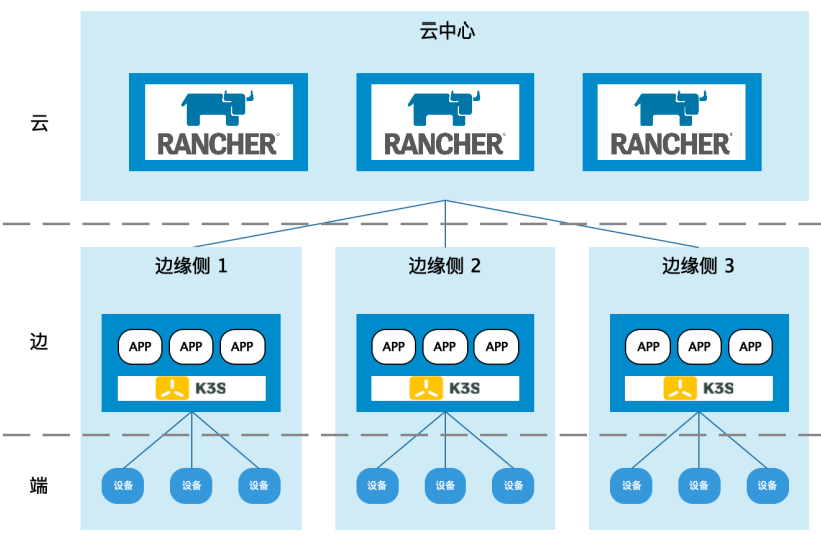 Rancher + K3s 边缘架构
Rancher + K3s 边缘架构
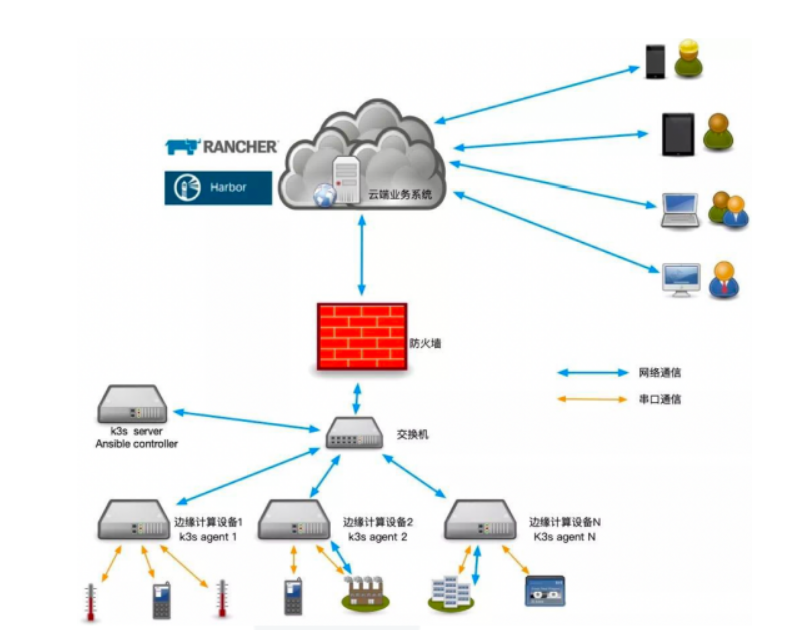 Rancher + K3s 落地案例
Rancher + K3s 落地案例
落地案例更明显:
- 1 套:“云”中部署一套 Rancher 集群,Rancher 负责管理下属所有的“边”中的 K3s 集群,Rancher 集群中同时可以部署云端的业务应用,负责和边缘侧业务系统同步, 以及下发数据或指令。
- N 套:“边” 设备中安装 K3s,K3s 中部署“边”的业务应用,供“端”连接使用。🐾这里一个 " 边 " 就是需要一套 K3s 集群的,也就是说既有 K3s Worker, 也有 K3s Master.
- “端”作为业务应用的最边缘端,通过网络连接“边”,完成业务组网,形成以“边”为中心的业务应用。
这样的架构在实际应用中,存在什么问题呢?
" 边 " 端存储容量
很多边端设备只有 8G 存储,除去系统和一些必要的软件包,空间就剩 4 - 6 G 了,而且 K8s 是对存储空间有强制 GC 的。那么极端情况下,可能 K3s master 都 pull 不下来完整的镜像包,导致系统报错,K3s 启动失败。
" 边 " 端存储性能不足
" 边 " 端存储主要是 SD 卡或 emmc 存储,如果下边挂载较多 K3s worker. K3s Master 还面临存储性能 IO 不足的情况。
" 边 " 端 K3s Master 和 Worker 对网络要求高
由于 K3s 是完全兼容 K8s 的,而 K8s 的 watch-list 机制是为稳定的数据中心场景设计的。在边端,也对网络要求很高。但是这在边端是不可能的情况,在实践中,边端出现:
- Master 和 Worker 长时间不通
- Master 和 Worker 时不时不通
- Worker 长时间离线
- DNS 网络异常
- Master 能连 Worker, Worker 连不到 Master
- Master 不能连 Worker, Worker 能连 Master
- Master 和 Worker 间带宽很小
- Master 和 Worker IP 地址变动
- …
各种各样网络不稳定的情况太常见了,以上任何一种情况,都可能导致 K3s worker 上应用异常、K3s master 异常甚至整个 K3s 边端集群异常。
这一点是基于 K8s 的边缘架构存在的最大问题
" 云 " 端和 " 边 " 端对网络要求也高 异常后无法自愈
" 云 " 端和 " 边 " 端是通过 Rancher 的 Agent 来连接的,走的是 websocket 协议。
但是实际应用中,还是发现 " 云 " 端和 " 边 " 端对网络要求也高," 云 " 端要管理 " 边 " 端,是有大量的数据要实时同步的,网络出现异常后,也会导致 " 边 " 端离线,无法自愈重连。
" 边 " 端自愈能力差
因为 " 边 " 端复杂的网络情况与 K8s 架构的不相容,导致实际应用中," 边 " 端自愈能力很差。
在 " 边 " 端异常的情况下,十有八九都是需要人工登录边端处置恢复的。
" 边 " 端对 CPU 和 内存资源要求也高
" 边 " 端是一套完整的 K8s 集群,那么这些服务都是需要启动的:
- etcd 或 K3s kine + sqlite
- k8s api server
- k8s scheduler
- k8s 各种 controller
- CRI: 容器运行时 containerd
- CNI: 网络插件
- CSI: 至少也是 local-path pod
- CoreDNS
- Metrics Server
- Ingress: Traefik
- kubelet
- kubeproxy
除了这些 pod, 还需要主机级别的服务:
- IPTables 或 nftables
- Netfilter
- Overlay fs
- …
这么一大堆 Pod 和服务都要启动,对边缘端的 CPU 和 内存资源也是巨大的消耗。
" 边 " 端网络模型复杂
还是 K8s 带来的问题," 边 " 端是一套完整的 K8s/k3s 集群,那么 " 边 " 端网络模型自然包括:
- Host Network
- Service Network
- Cluster Network
- DNS
要实现 K8s CNI 模型,又会引入 overlay 网络。
甚至为了实现 " 云 " “边” “端” 的联通,可能还需要引入:
- 隧道网络
- 边缘网关网络
- …
进一步提升了网络的复杂性!
导致出现问题非常难以处理,简单问题复杂化。
小结
Rancher + K3s, 在边缘计算场景下的网络拓扑架构是:
- 1 套:“云”中部署一套 Rancher 集群,Rancher 负责管理下属所有的“边”中的 K3s 集群,Rancher 集群中同时可以部署云端的业务应用,负责和边缘侧业务系统同步, 以及下发数据或指令。
- N 套:“边” 设备中安装 K3s,K3s 中部署“边”的业务应用,供“端”连接使用。🐾这里一个 " 边 " 就是需要一套 K3s 集群的,也就是说既有 K3s Worker, 也有 K3s Master.
- “端”作为业务应用的最边缘端,通过网络连接“边”,完成业务组网,形成以“边”为中心的业务应用。
K3s 是基于 K8s 的兼容实现,同时因为网络拓扑架构,导致这种架构存在以下问题:
- " 边 " 端存储容量不足
- " 边 " 端存储性能不足
- " 边 " 端无法满足 K3s Master 和 Worker 对网络的高要求
- " 云 " 端和 " 边 " 端对网络要求也过高 异常后无法自愈
- " 边 " 端自愈能力差
- " 边 " 端对 CPU 和 内存资源要求也高
- " 边 " 端网络模型复杂
而且每个问题几乎无解。
边缘计算场景对容器编排的需求
结合上述场景,我理解的边缘计算场景对容器编排的需求:
- " 边 " 端最好一个 agent, 不要引入过多其他镜像资源,也不要引入过多其他组件
- 资源占用轻量,agent CPU 内存 存储都消耗极少
- 最好统一 " 云 " 端管理," 边 " 端不需要再有一个消耗资源的管理端
- 弱网环境适应性强
- 自愈能力强
- 不要额外再引入其他网络模型,最好能直接基于主机网络运行,也不强依赖 DNS
那么基于 Docker 的边缘容器集群管理方案:
- HashiCorp Nomad
- Portainer
就表现地更有优势。
Portainer 边缘计算
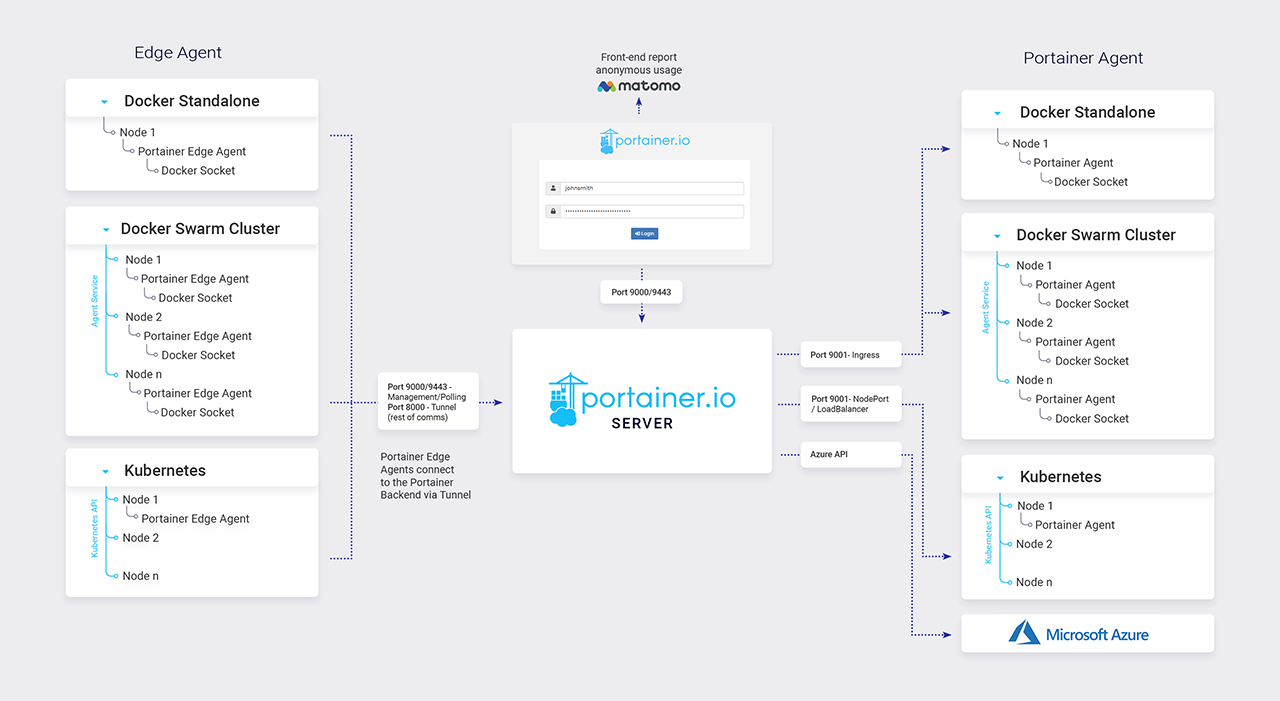 Portainer 架构
Portainer 架构
对于 Edge, Portainer 有专门优化,可以参考左侧的 Edge 架构。
- " 云 " 端负责管理,portainer server 位于云端
- " 边 " 端都是 Edge Agent
- “云” " 边 " 不需要双向通信,而是 " 边 " 端通过直连或隧道定期去 Server 端 pull 信息
以上是针对网络模型的优化,使其更适合边缘计算的场景。
另外,Poratiner 的 Agent 非常轻量级,只使用大约 10MB 的内存,而且边缘端就只需要部署这一个 Agent, 这就是为什么它也可以在硬件资源有限的边缘设备上运行。唯一的依赖就是边缘端需要安装有 Docker.
开源版边缘功能
- Edge Agent 默认网络策略:pull
- Edge Compute 相关模块和菜单:
- Edge Groups: 将一组边缘设备 / 环境通过静态 / 动态的方式归为一个 Edge Group, 方便批量管理
- Edge Stacks: 类似 Docker Compose 的概念,可以将一套边缘服务批量推向一个或所有的 Edge Group
- Edge Jobs: 类似 crontab 的功能,在边缘端批量运行 job.
- 边缘应急特性支持:
- Interl OpenAMT
- FDO
- 管理边缘端 OS 层文件系统(通过 docker linux socket 实现)
通过这些功能,Portainer 可以:
- 边缘端通过 pull 心跳在复杂网络条件下保持与 Portainer Server 的联通和受管
- 通过 Edge Compute 的 Edge Groups/Edge Stacks/Edge Jobs 模块,实现对边缘端的批量服务部署和 job 部署
但是开源版相比商业版,阉割的功能较多,比如开源版无法实现一键批量 onboarding 等重要边缘功能。
商业版额外功能
- 一键 onboaring: 边缘设备一键批量安装
- 安全通信:在复杂网络条件下,离线条件下,实现基于隧道的连接。
- Edge Devices: 边缘设备管理
- Waiting Room: 等候室,有选择地连接请求接入 server 端的边缘设备
小结
个人认为,相比 Rancher + k3s 的方案,portainer 的边缘计算解决方案有以下突出优势:
- 资源占用少
- 网络模型针对边缘网络优化
更详细来说,这些功能特性相比 Rancher + K3s 的更适合边缘场景:
- " 云 " 端 Server, " 边 " 端只有 Agent
- Edge Agent 轻量,运行内存 10MB 左右
- Edge Agent pull 模型,针对边缘网络适应性强
- 没有引入其他网络模型,也不强依赖 DNS
但是,开源版 portainer 也存在明显的功能缺失,最主要的功能缺失是:
- 一键 onboaring: 边缘设备一键批量安装
的功能。
HashiCorp Nomad 边缘计算
 Nomad 边缘参考架构
Nomad 边缘参考架构
HashiCorp Nomad 自 1.3 版本以来,针对边缘端增加了很多实用功能:
- 1.3 引入:Nomad 原生服务发现(简单场景下不再需要 Consul 组件)
- 1.4 引入:
- 健康检查
- Nomad Variables(简单场景下不再需要 Vault 组件)
- 1.5 引入:
- 节点动态元数据,更方便 Node 动态管理
- 1.6 引入:
- Node Pool 节点池概念,更方便节点批量管理
使得其在边缘端,不再需要依赖:
- Cosul
- Vault
这 2 个组件,仅通过 Nomad Agent 就可以实现边缘端的:
- 容器编排管理
- 基本服务发现和管理
- 变量参数 / 环境变量 / 配置管理
等功能。
与 Portainer 类似,其在边缘端也只有一个 Edge Agent. 内存占用也仅为 20-40 MB 左右。
Nomad 支持地理上遥远的客户端,这意味着 Nomad 服务器集群不需要在客户端附近运行。(K8s 就做不到这样。)
此外,断开连接的客户端的 allocations (分配) 可以正常重新连接,处理边缘设备遇到网络延迟或临时连接丢失的情况。
这里特别提到 Nomad 的 2 个参数:
max_client_disconnect
如果不设置此属性,Nomad 将运行其默认行为:当 Nomad 客户机的心跳失败时,Nomad 将把该客户机标记为停机 (down),并把 allocations 分配标记为丢失 (lost)。Nomad 将自动在另一个客户端上安排新的分配。但是,如果关闭的客户端重新连接到服务器,它将关闭其现有的分配。这是次优的,因为 Nomad 将停止在重新连接的客户端上运行分配,只是为了放置相同的分配。(K8s 的行为也是,且只能是这样。)
对于许多边缘工作负载,特别是具有高延迟或不稳定网络连接的工作负载,这是破坏性的,因为断开连接的客户端并不一定意味着客户端关闭。Allocations 可以继续在临时断开连接的客户端上运行。对于这些情况,就需要设置 max_client_disconnect 属性,以正常处理断开连接的客户端分配。
如果设置了 max_client_disconnect ,当客户端断开连接时,Nomad 仍将在另一个客户端上安排分配。但是,当客户端重新连接时:
- Nomad 将重新连接的客户端标记为就绪 (ready)。
- 如果有多个作业版本,Nomad 将选择最新的作业版本并停止所有其他分配。
- 如果 Nomad 将丢失的分配重新调度到新客户端,并且新客户端具有更高的节点等级,则 Nomad 将继续新客户端中的分配并停止所有其他客户端。
- 如果新客户端具有更差的节点排名或存在平局,则 Nomad 将恢复重新连接的客户端上的分配并停止所有其他客户端。
这是具有高延迟或不稳定网络连接的边缘工作负载的首选行为,尤其是在断开分配是有状态的情况下。
举例来说:
在某一个边缘设备中运行有 1 个 web 服务,此时,边缘设备与 (边缘容器管理的) Server 端断开连接
- 在 K8s 中,就是 Node Unknown 或 NotReady 的状态,会认为 web 服务已宕机,会在另外一台边缘设备中启动 web 服务;在恢复连接后,发现最新的实例是在另一台边缘设备中,那么前一台设备的服务会被关闭。对于使用该 web 的用户来说,可能就是在边缘设备重新连接到 (边缘容器管理的) Server 端后发现 web 服务异常(被管理端关闭)
- 在启用该参数的 Nomad 中,Node 会是 lost 状态,分配的服务会是 Unknown 状态。会在另外一台边缘设备中启动 web 服务;在恢复连接后,发现 web 服务正常运行,关闭后启动的 web 服务。对于使用该 web 的用户来说,体验是一直没有中断的。
Template change_mode
另外还有一个参数,是 Template 块下的 change_mode
将 Template 节 change_mode 设置为 noop。默认情况下, change_mode 设置为 restart ,如果您的客户端无法连接到 Nomad 服务器,这将导致任务失败。由于 Nomad 在边缘数据中心上调度此作业,因此如果边缘客户端与 Nomad 服务器断开连接(从而断开服务发现),则服务将使用先前的模板配置。
小结
个人认为,相比 Rancher + k3s 的方案,HashiCorp Nomad 的边缘计算解决方案有以下突出优势:
- 资源占用少 - 边缘只有 Nomad Agent
- 管理端和 Agent 端可以物理距离很远 - 天南地北的所有边缘设备可以通过一个云端中心来管理
- 相关参数针对边缘网络优化 - 如
max_client_disconnect
更详细来说,这些功能特性相比 Rancher + K3s 的更适合边缘场景:
- " 云 " 端 Server, " 边 " 端只有 Agent
- Nomad Agent 轻量,运行内存 20-40MB 左右
- Nomad Agent 与 Server 心跳检测是基于 pull 模型,针对边缘网络适应性强
- 专为边缘设计的
max_client_disconnect参数 - 没有引入其他网络模型,也不强依赖 DNS
另外,相比开源版 portainer, Nomad 还有一重优势,即:
- 一键 onboaring: 边缘设备一键批量安装甚至是预安装
得益于 Nomad 的良好架构,其天生是为大规模容器编排而设计的,可以做到使用 Terraform 或 Ansible 一键批量部署,甚至是预安装(烧录). 典型如 Nomad Agent 配置,统一如下:
data_dir = "/opt/nomad/data" bind_addr = "0.0.0.0" client { enabled = true servers = ["<nomad_server_ip_list>"] } HCL |
总结
在 IoT 边缘容器集群管理领域,基于 K8s 的解决方案(包括 Rancher + K3s) 明显不太适应,笔者体验 2 年左右坑太多了,主要原因是:
- 资源消耗高
- 网络条件要求高
- 网络模型复杂
- 自愈能力差
- 引入了过多额外组件
但是,HashiCorp Nomad,Portainer 相比 k8s k3s, 在物联网 / 边缘计算领域是更有优势的。值得一试。因为它们:
- 轻量:只有一个 Agent 且内存占用极低
- 针对边缘网络做了特殊优化
- 没有引入复杂网络模型(如 Service Network, Pod Network, Overlay Network…, 主要依赖 Host Network, 容器端口映射,顶多多一个 bridge 网络), 不依赖 DNS
- 自愈能力强
- 没有引入了过多额外组件,就多了一个 Agent
我个人更推荐使用 Nomad (小规模 / 家庭场景可以使用 Portainer).
以上.
如果您有更好的经验, 欢迎交流探讨~

