
概述
Prometheus 作为云原生和容器平台监控的事实标准,本期我们来看一下如何通过 Prometheus 配置 SLO 监控和告警.
SLO 告警
SLO 的告警, 根据 Google SRE 官方实践, 建议使用如下几个维度的告警:
- Burn Rate(消耗率)Alerts
- Error Budget (错误预算)Alerts
Error Budget
假设我们与用户的合同规定,在 7 天内的可用性为 99.9%。这相当于 10 分钟的 Error Budget。
Error Budget 的一种参考实现:
- 计算过去 7 天 (或更长如 30 天, 或更短如 3 天) 的 error budget
- 告警级别:
- CRITICAL: error budget >= 90%(或 100%)(即过去 7 天已经不可用 9.03 分钟; 即 availability 已达到 99.91%, 马上接近 99.9% 危险阈值)
- WARNING: error budget >= 75%
📝Notes:
Key Words:
- SLO
- 时间窗口
- 阈值
Burn Rate
假设我们与用户的合同规定,在 30 天内的可用性为 99.9%。这相当于 43 分钟的 Error Budget。如果我们以小增量的小故障来消耗这 43 分钟,我们的用户可能仍然很高兴和高效。但是,如果我们在关键业务时间发生 43 分钟的单次中断,该怎么办?可以肯定地说,我们的用户会对这种体验感到非常不满意!
为了解决这个问题,Google SRE 引入 Burn Rate。定义很简单:如果我们在示例中在 30 天内精确地消耗 43 分钟,则将其称为 1 的消耗速率。如果我们以两倍的速度将其消耗,例如,在 15 天内消耗殆尽,消耗速率为 2,依此类推。如您所见,这使我们能够跟踪长期合规性,并就严重的短期问题发出警报。
下图说明了多种 burn rate 的概念。X 轴表示时间,Y 轴表示剩余 error budget。
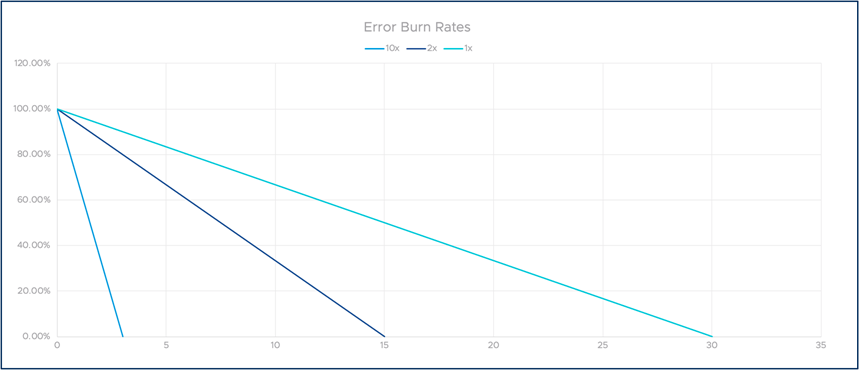 SLO Burn Rate
SLO Burn Rate
📝Notes:
本质上, Error Budget >= 100% 的告警, 其实就是 Burn Rate 为 1 的这种特殊情况.
Burn Rate 的一种参考实践:
- 计算过去 1 小时 (或者更短的窗口 5m, 或者更长的窗口 3h-6h…) 的 time window 的 burn rate
- 告警级别:
- CRITICAL: burn rate >= 14.4(即按照这个速率, 2 天内 30 天的 availability error budget 就会用尽)
- WARNING: burn rate >=7.2 (即按照这个速率, 4 天内 30 天的 availability error budget 就会用尽)
使用 Prometheus 配置 SLO 监控和告警实战
这里以 2 个典型的 SLO 为例:
- HTTP 请求的错误率大于 99.9%(即 在 30 天的不可用时间为: 43min 11s)
- 99% 的 HTTP 请求延迟时间大于 100ms
HTTP 请求错误率
基本信息:
- 指标为:
http_requests_total - label 为:
{job=busi} - 错误的定义: http code 为 5xx, 即
code=~"5xx"
完整的 Prometheus Rule 如下:
groups: - name: SLOs-http_requests_total rules: # 过去 5m 的 http 请求错误率 - expr: | sum(rate(http_requests_total{job="busi",code=~"5.."}[5m])) / sum(rate(http_requests_total{job="busi"}[5m])) labels: job: busi record: http_requests_total:burnrate5m # 过去 30m 的 - expr: | sum(rate(http_requests_total{job="busi",code=~"5.."}[30m])) / sum(rate(http_requests_total{job="busi"}[30m])) labels: job: busi record: http_requests_total:burnrate30m # 过去 1h 的 - expr: | sum(rate(http_requests_total{job="busi",code=~"5.."}[1h])) / sum(rate(http_requests_total{job="busi"}[1h])) labels: job: busi record: http_requests_total:burnrate1h # 过去 6h 的 - expr: | sum(rate(http_requests_total{job="busi",code=~"5.."}[6h])) / sum(rate(http_requests_total{job="busi"}[6h])) labels: job: busi record: http_requests_total:burnrate6h # 过去 1d 的 - expr: | sum(rate(http_requests_total{job="busi",code=~"5.."}[1d])) / sum(rate(http_requests_total{job="busi"}[1d])) labels: job: busi record: http_requests_total:burnrate1d # 过去 3d 的 - expr: | sum(rate(http_requests_total{job="busi",code=~"5.."}[3d])) / sum(rate(http_requests_total{job="busi"}[3d])) labels: job: busi record: http_requests_total:burnrate3d # 🐾短期内快速燃尽 # 过去 5m 和过去 1h 的燃尽率都大于 14.4 - alert: ErrorBudgetBurn annotations: message: 'High error budget burn for job=busi (current value: {{ $value }})' expr: | sum(http_requests_total:burnrate5m{job="busi"}) > (14.40 * (1-0.99900)) and sum(http_requests_total:burnrate1h{job="busi"}) > (14.40 * (1-0.99900)) for: 2m labels: job: busi severity: critical # 🐾中期时间内燃尽过快 # 过去 30m 和过去 6h 的燃尽率都大于 7.2 - alert: ErrorBudgetBurn annotations: message: 'High error budget burn for job=busi (current value: {{ $value }})' expr: | sum(http_requests_total:burnrate30m{job="busi"}) > (7.20 * (1-0.99900)) and sum(http_requests_total:burnrate6h{job="busi"}) > (7.20 * (1-0.99900)) for: 15m labels: job: busi severity: warning # 🐾长期内错误预算超出 # 过去 6h 和过去 3 天的错误预算已燃尽 - alert: ErrorBudgetAlert annotations: message: 'High error budget burn for job=busi (current value: {{ $value }})' expr: | sum(http_requests_total:burnrate6h{job="busi"}) > (1.00 * (1-0.99900)) and sum(http_requests_total:burnrate3d{job="busi"}) > (1.00 * (1-0.99900)) for: 3h labels: job: busi severity: warning YAML |
HTTP 请求延迟
基本信息:
- 指标为:
http_request_duration_seconds - label 为:
{job=busi} - 99% 的 HTTP 请求响应时间都应 小于等于 100ms
- 只计算成功的请求(毕竟上面已经算过错误率了)
完整的 Prometheus Rule 如下:
groups: - name: SLOs-http_request_duration_seconds rules: # 过去 5m HTTP 请求响应时间大于 100ms(0.1s)的百分比 - expr: | 1 - ( sum(rate(http_request_duration_seconds_bucket{job="busi",le="0.1",code!~"5.."}[5m])) / sum(rate(http_request_duration_seconds_count{job="busi"}[5m])) ) labels: job: busi latency: "0.1" record: latencytarget:http_request_duration_seconds:rate5m # 过去 30m 的 - expr: | 1 - ( sum(rate(http_request_duration_seconds_bucket{job="busi",le="0.1",code!~"5.."}[30m])) / sum(rate(http_request_duration_seconds_count{job="busi"}[30m])) ) labels: job: busi latency: "0.1" record: latencytarget:http_request_duration_seconds:rate30m # 过去 1h 的 - expr: | 1 - ( sum(rate(http_request_duration_seconds_bucket{job="busi",le="0.1",code!~"5.."}[1h])) / sum(rate(http_request_duration_seconds_count{job="busi"}[1h])) ) labels: job: busi latency: "0.1" record: latencytarget:http_request_duration_seconds:rate1h # 过去 2h 的 - expr: | 1 - ( sum(rate(http_request_duration_seconds_bucket{job="busi",le="0.1",code!~"5.."}[2h])) / sum(rate(http_request_duration_seconds_count{job="busi"}[2h])) ) labels: job: busi latency: "0.1" record: latencytarget:http_request_duration_seconds:rate2h # 过去 6h 的 - expr: | 1 - ( sum(rate(http_request_duration_seconds_bucket{job="busi",le="0.1",code!~"5.."}[6h])) / sum(rate(http_request_duration_seconds_count{job="busi"}[6h])) ) labels: job: busi latency: "0.1" record: latencytarget:http_request_duration_seconds:rate6h # 过去 1d 的 - expr: | 1 - ( sum(rate(http_request_duration_seconds_bucket{job="busi",le="0.1",code!~"5.."}[1d])) / sum(rate(http_request_duration_seconds_count{job="busi"}[1d])) ) labels: job: busi latency: "0.1" record: latencytarget:http_request_duration_seconds:rate1d # 过去 3d 的 - expr: | 1 - ( sum(rate(http_request_duration_seconds_bucket{job="busi",le="0.1",code!~"5.."}[3d])) / sum(rate(http_request_duration_seconds_count{job="busi"}[3d])) ) labels: job: busi latency: "0.1" record: latencytarget:http_request_duration_seconds:rate3d # 🐾HTTP 相应时间 SLO 短中期内快速燃尽 # - 过去 5m 和过去 1h 燃尽率大于 14.4 # - 或: 过去 30m 和过去 6h 燃尽率大于 7.2 - alert: LatencyBudgetBurn annotations: message: 'High requests latency budget burn for job=busi,latency=0.1 (current value: {{ $value }})' expr: | ( latencytarget:http_request_duration_seconds:rate1h{job="busi",latency="0.1"} > (14.4*(1-0.99)) and latencytarget:http_request_duration_seconds:rate5m{job="busi",latency="0.1"} > (14.4*(1-0.99)) ) or ( latencytarget:http_request_duration_seconds:rate6h{job="busi",latency="0.1"} > (7.2*(1-0.99)) and latencytarget:http_request_duration_seconds:rate30m{job="busi",latency="0.1"} > (7.2*(1-0.99)) ) labels: job: busi latency: "0.1" severity: critical - alert: LatencyBudgetBurn annotations: message: 'High requests latency budget burn for job=busi,latency=0.1 (current value: {{ $value }})' expr: | ( latencytarget:http_request_duration_seconds:rate1d{job="busi",latency="0.1"} > (3*(1-0.99)) and latencytarget:http_request_duration_seconds:rate2h{job="busi",latency="0.1"} > (3*(1-0.99)) ) or ( latencytarget:http_request_duration_seconds:rate3d{job="busi",latency="0.1"} > ((1-0.99)) and latencytarget:http_request_duration_seconds:rate6h{job="busi",latency="0.1"} > ((1-0.99)) ) labels: job: busi latency: "0.1" severity: warning YAML |
🎉🎉🎉
总结
Prometheus 作为云原生和容器平台监控的事实标准,本期我们来看一下如何通过 Prometheus 配置 SLO 监控和告警.
我们例举了 2 个典型的 SLO - HTTP 响应时间和错误率.
错误率的非常好理解, 响应时间的有点绕, 需要大家慢慢消化下.
😼😼😼


