
目标
- 告警恢复通知 - 经过评估无法实现
- 原因: 告警和恢复是单独完全不相关的事件, 告警是
Warning级别, 恢复是Normal级别, 要开启恢复, 就会导致所有NormalEvents 都会被发送, 这个数量是很恐怖的; 而且, 除非特别有经验和耐心, 否则无法看出哪条Normal对应的是 告警的恢复.
- 未恢复进行持续告警 - 默认就带的能力, 无需额外配置.
- 告警内容显示资源名称,比如节点和 pod 名称
- 可以设置屏蔽特定的节点和工作负载并可以动态调整
- 比如,集群
001中的节点worker-1做计划性维护,期间停止监控,维护完成后重新开始监控。
配置
告警内容显示资源名称
典型的几类 events:
apiVersion: v1 count: 101557 eventTime: null firstTimestamp: "2022-04-08T03:50:47Z" involvedObject: apiVersion: v1 fieldPath: spec.containers{prometheus} kind: Pod name: prometheus-rancher-monitoring-prometheus-0 namespace: cattle-monitoring-system kind: Event lastTimestamp: "2022-04-14T11:39:19Z" message: 'Readiness probe failed: Get "http://10.42.0.87:9090/-/ready": context deadline exceeded (Client.Timeout exceeded while awaiting headers)' metadata: creationTimestamp: "2022-04-08T03:51:17Z" name: prometheus-rancher-monitoring-prometheus-0.16e3cf53f0793344 namespace: cattle-monitoring-system reason: Unhealthy reportingComponent: "" reportingInstance: "" source: component: kubelet host: master-1 type: Warning YAML |
apiVersion: v1 count: 116 eventTime: null firstTimestamp: "2022-04-13T02:43:26Z" involvedObject: apiVersion: v1 fieldPath: spec.containers{grafana} kind: Pod name: rancher-monitoring-grafana-57777cc795-2b2x5 namespace: cattle-monitoring-system kind: Event lastTimestamp: "2022-04-14T11:18:56Z" message: 'Readiness probe failed: Get "http://10.42.0.90:3000/api/health": context deadline exceeded (Client.Timeout exceeded while awaiting headers)' metadata: creationTimestamp: "2022-04-14T11:18:57Z" name: rancher-monitoring-grafana-57777cc795-2b2x5.16e5548dd2523a13 namespace: cattle-monitoring-system reason: Unhealthy reportingComponent: "" reportingInstance: "" source: component: kubelet host: master-1 type: Warning YAML |
apiVersion: v1 count: 20958 eventTime: null firstTimestamp: "2022-04-11T10:34:51Z" involvedObject: apiVersion: v1 fieldPath: spec.containers{lb-port-1883} kind: Pod name: svclb-emqx-dt22t namespace: emqx kind: Event lastTimestamp: "2022-04-14T11:39:48Z" message: Back-off restarting failed container metadata: creationTimestamp: "2022-04-11T10:34:51Z" name: svclb-emqx-dt22t.16e4d11e2b9efd27 namespace: emqx reason: BackOff reportingComponent: "" reportingInstance: "" source: component: kubelet host: worker-1 type: Warning YAML |
apiVersion: v1 count: 21069 eventTime: null firstTimestamp: "2022-04-11T10:34:48Z" involvedObject: apiVersion: v1 fieldPath: spec.containers{lb-port-80} kind: Pod name: svclb-traefik-r5p8t namespace: kube-system kind: Event lastTimestamp: "2022-04-14T11:44:59Z" message: Back-off restarting failed container metadata: creationTimestamp: "2022-04-11T10:34:48Z" name: svclb-traefik-r5p8t.16e4d11daf0b79ce namespace: kube-system reason: BackOff reportingComponent: "" reportingInstance: "" source: component: kubelet host: worker-1 type: Warning YAML |
{ "metadata": { "name": "event-exporter-79544df9f7-xj4t5.16e5c540dc32614f", "namespace": "monitoring", "uid": "baf2f642-2383-4e22-87e0-456b6c3eaf4e", "resourceVersion": "14043444", "creationTimestamp": "2022-04-14T13:08:40Z" }, "reason": "Pulled", "message": "Container image \"ghcr.io/opsgenie/kubernetes-event-exporter:v0.11\" already present on machine", "source": { "component": "kubelet", "host": "worker-2" }, "firstTimestamp": "2022-04-14T13:08:40Z", "lastTimestamp": "2022-04-14T13:08:40Z", "count": 1, "type": "Normal", "eventTime": null, "reportingComponent": "", "reportingInstance": "", "involvedObject": { "kind": "Pod", "namespace": "monitoring", "name": "event-exporter-79544df9f7-xj4t5", "uid": "b77d3e13-fa9e-484b-8a5a-d1afc9edec75", "apiVersion": "v1", "resourceVersion": "14043435", "fieldPath": "spec.containers{event-exporter}", "labels": { "app": "event-exporter", "pod-template-hash": "79544df9f7", "version": "v1" } } } JSON |
我们可以把更多的字段加入到告警信息中, 其中就包括:
- 节点:
{{ Source.Host }} - Pod:
{{ .InvolvedObject.Name }}
综上, 修改后的event-exporter-cfg yaml 如下:
apiVersion: v1 kind: ConfigMap metadata: name: event-exporter-cfg namespace: monitoring resourceVersion: '5779968' data: config.yaml: | logLevel: error logFormat: json route: routes: - match: - receiver: "dump" - drop: - type: "Normal" match: - receiver: "feishu" receivers: - name: "dump" stdout: {} - name: "feishu" webhook: endpoint: "https://open.feishu.cn/open-apis/bot/v2/hook/..." headers: Content-Type: application/json layout: msg_type: interactive card: config: wide_screen_mode: true enable_forward: true header: title: tag: plain_text content: xxx 测试 K3S 集群告警 template: red elements: - tag: div text: tag: lark_md content: "**EventID:** {{ .UID }}\n**EventNamespace:** {{ .InvolvedObject.Namespace }}\n**EventName:** {{ .InvolvedObject.Name }}\n**EventType:** {{ .Type }}\n**EventKind:** {{ .InvolvedObject.Kind }}\n**EventReason:** {{ .Reason }}\n**EventTime:** {{ .LastTimestamp }}\n**EventMessage:** {{ .Message }}\n**EventComponent:** {{ .Source.Component }}\n**EventHost:** {{ .Source.Host }}\n**EventLabels:** {{ toJson .InvolvedObject.Labels}}\n**EventAnnotations:** {{ toJson .InvolvedObject.Annotations}}" YAML |
屏蔽特定的节点和工作负载
比如,集群
001中的节点worker-1做计划性维护,期间停止监控,维护完成后重新开始监控。
继续修改event-exporter-cfg yaml 如下:
apiVersion: v1 kind: ConfigMap metadata: name: event-exporter-cfg namespace: monitoring data: config.yaml: | logLevel: error logFormat: json route: routes: - match: - receiver: "dump" - drop: - type: "Normal" - source: host: "worker-1" - namespace: "cattle-monitoring-system" - name: "*emqx*" - kind: "Pod|Deployment|ReplicaSet" - labels: version: "dev" match: - receiver: "feishu" receivers: - name: "dump" stdout: {} - name: "feishu" webhook: endpoint: "https://open.feishu.cn/open-apis/bot/v2/hook/..." headers: Content-Type: application/json layout: msg_type: interactive card: config: wide_screen_mode: true enable_forward: true header: title: tag: plain_text content: xxx 测试 K3S 集群告警 template: red elements: - tag: div text: tag: lark_md content: "**EventID:** {{ .UID }}\n**EventNamespace:** {{ .InvolvedObject.Namespace }}\n**EventName:** {{ .InvolvedObject.Name }}\n**EventType:** {{ .Type }}\n**EventKind:** {{ .InvolvedObject.Kind }}\n**EventReason:** {{ .Reason }}\n**EventTime:** {{ .LastTimestamp }}\n**EventMessage:** {{ .Message }}\n**EventComponent:** {{ .Source.Component }}\n**EventHost:** {{ .Source.Host }}\n**EventLabels:** {{ toJson .InvolvedObject.Labels}}\n**EventAnnotations:** {{ toJson .InvolvedObject.Annotations}}" YAML |
默认的 drop 规则为: - type: "Normal", 即不对 Normal 级别进行告警;
现在加入以下规则:
- source: host: "worker-1" - namespace: "cattle-monitoring-system" - name: "*emqx*" - kind: "Pod|Deployment|ReplicaSet" - labels: version: "dev" YAML |
... host: "worker-1": 不对节点worker-1做告警;... namespace: "cattle-monitoring-system": 不对 NameSpace:cattle-monitoring-system做告警;... name: "*emqx*": 不对 name(name 往往是 pod name) 包含emqx的做告警kind: "Pod|Deployment|ReplicaSet": 不对PodDeploymentReplicaSet做告警(也就是不关注应用, 组件相关的告警)...version: "dev": 不对label含有version: "dev"的做告警(可以通过它屏蔽特定的应用的告警)
最终效果
如下图:
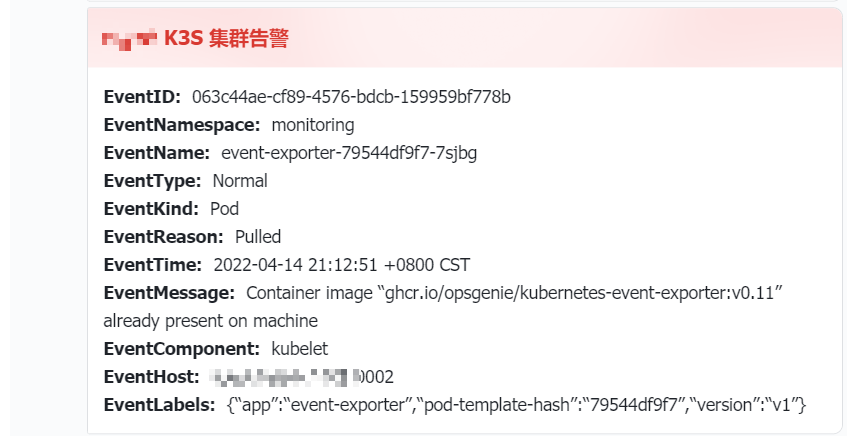 Event 告警包含更多信息
Event 告警包含更多信息
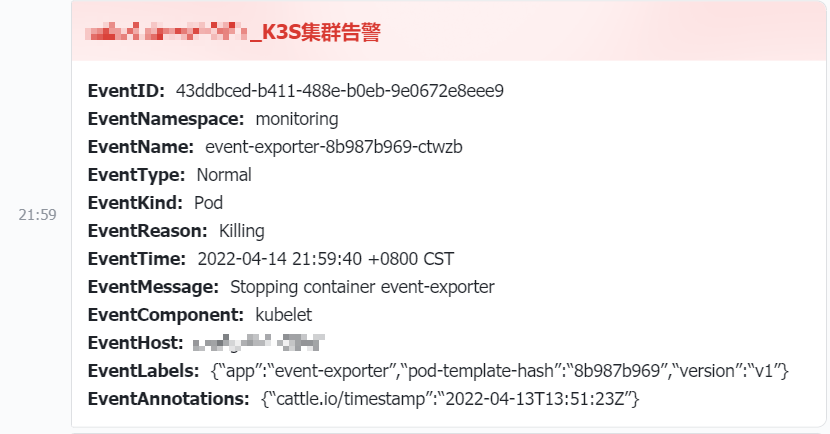 Event 告警包含更多信息 -2
Event 告警包含更多信息 -2
🎉🎉🎉
