
2 单机存储系统
ACID:
- 原子性 Atomicity
- 一致性 Consistency
- 隔离性 Isolation
- 持久性 Durability
存储引擎:
- 哈希存储引擎
- B 树存储引擎
- LSM 树(Log Structure Mereg Tree)存储引擎
2.1 硬件基础
CPU:对称多处理结构(SMP)。SMP 扩展能力有限。
为了提高可扩展性,现在的主流服务器架构一般为 NUMA(Non-Uniform Memory Access,非一致性存储访问)架构。它具有多个 NUMA 节点,每个 NUMA 节点是一个 SMP 结构,一般由多个 CPU(如 4 个)组成,并且具有独立的本地内存、io 槽口等。
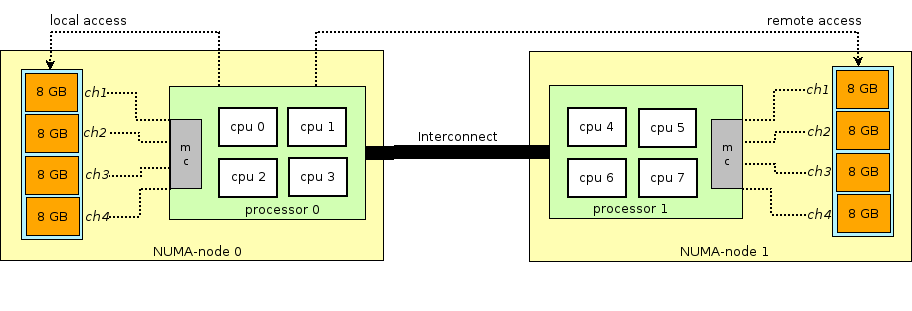
NUMA 节点可以直接快速访问本地内存,也可以通过 NUMA 互联互通模块访问其他 NUMA 节点的内存,访问本地内存的速度要远远高于访问远程的速度。
2.1.2 IO 总线
Interl x48 主板为例,典型的南北桥架构。北桥芯片通过前端总线(Front Side Bus,FSB)与 CPU 相连,内存模块以及 PIC-E 设备(如高端 SSD 设备 Fusion-IO)挂接在北桥上。北桥与南桥之间通过 DMI 连接。
2.1.3 网络拓扑
三层拓扑。
接入层(Edge),汇聚层(Aggregation)、核心层(Core)。
问题:可能有很多接入层的交换机接到汇聚层,很多汇聚层交换机接到核心层。同一个接入层下的服务器之间的带宽比如为 1Gb,那么不同接入层交换机下的服务器之间的带宽小于 1Gb。由于同一个接入层的服务器往往部署在一个机架内,因此,设计系统的时候需要考虑服务器是否在一个机架内,减少跨机架拷贝大量数据。如:Hadoop HDFS 默认 3 副本,其中两副本放在同一个机架。
Google 在 2008 年将网络改造为扁平化拓扑结构,即三层 CLOS 网络,同一个集群内最多支持 20480 台服务器,且任何两台都有 如 1Gb 带宽。CLOS 网络需要额外投入更多的交换机。好处是:设计系统时不需要考虑底层网络拓扑,从而很方便地将整个集群做成一个资源池。
🤔
如何计算光纤延时?
如:北京杭州直线距离 1300 公里,光在光线中走折线,假设折线距离为直线距离的 1.5 倍,那么光传输一次网络来回延时的理论值为
1300*1.5*2/300 000 = 13ms, 实际测试值大约为 40ms。
2.1.4 性能参数
| 类别 | 消耗的时间 |
| 访问 L1 Cache | 0.5 ns |
| 分支预测失败 | 5 ns |
| 访问 L2 Cache | 7 ns |
| Mutex 加锁、解锁 | 100 ns |
| 内存访问 | 100 ns |
| 千兆网络发送 1 MB 数据 | 10 ms |
| 从内存顺序读取 1 MB 数据 | 0.25 ms |
| 机房内网络来回 | 0.5 ms |
| 异地机房之间网络来回 | 30-100 ms |
| SATA 磁盘寻道 | 10 ms |
| 从 SATA 磁盘顺序读取 1 MB 数据 | 20 ms |
| 固态盘 SSD 访问延迟 | 0.1-0.2 ms |
存储系统的性能瓶颈主要在于磁盘 随机读写。
SSD 特点:随机读取延迟小。
| 类别 | IOPS | 每 GB 价格(元) | 随机读取 | 随机写入 |
| 内存 | 千万级 | 150 | 友好 | 友好 |
| SSD 盘 | 35000 | 20 | 友好 | 写入放大问题 |
| SAS 磁盘 | 180 | 3 | 磁盘寻道 | 磁盘寻道 |
| SATA 磁盘 | 90 | 0.5 | 磁盘寻道 | 磁盘寻道 |
存储系统性能主要:吞吐量以及访问延时,在保证访问延时的基础上,通过最低的成本实现尽可能高的吞吐量。磁盘适合大块顺序访问,ssd 适合随机访问较多或对延时较敏感的关键系统。二者常常结合,热数据存储在 ssd 上,冷数据存储在磁盘中。
2.2 单机存储引擎
- 哈希:不支持顺序扫描
- B 树:适合关系型数据库
- LSM 树:通过批量转储技术规避磁盘随机写入问题。
2.3 数据模型
2.3.1 文件模型
POSIX(Portable Operating System Interface),要求读写并发时保证操作的原子性,即读操作要么读取到所有结果,要么什么都读不到;另外,要求读操作能够读到之前所有写操作的结果。适合单机文件系统。分布式文件系统不会严格遵守该标准。
NFS 允许客户端缓存文件数据,多个客户端并发修改同一文件时可能出现不一致的情况。
对象模型与文件模型类似,弱化了目录树的概念 ,要求 对象一次性写入到系统,只能删除整个对象,不允许修改其中某个部分。
2.3.2 关系模型
每个关系是一个表格,由多个元祖(行)组成,每个元祖又包含多个属性(列)。
关系名、属性名、以及属性类型称作该关系的模式(Schema)。如:Movie 关系的模式为Movie(title, year, length), title year length 为属性,类型分别为字符串 整数 整数
123456 |
SELECT <属性表 > FROM < 关系表 > WHERE < 条件 > GROUP BY < 属性表 > HAVING < 条件 > ORDER BY < 属性表> SQL |
SQL 特性:
- 允许在
WHRER FROM HAVING字句中使用子查询,子查询又是一个完整的select-from-where语句 - 索引(用于减少 SQL 执行时扫描的数据量,提高读取性能)
- 事务(保证多个操作并发执行时的 ACID 特性)
2.3.3 键值模型
键值模型:
- Put
- Get
- Delete
表格模型:
Google Bigtable、HBase,除了支持简单的基于主键的操作,还支持 范围扫描 ,另外,也支持 基于列的操作。主要操作如下:
- Insert
- Delete
- Update
- Get
- Scan:扫描一段范围的数据,根据主键确定扫描的范围,支持扫描部分列,支持按列过滤、排序、分组等。
不支持多表关联操作,一般不支持二级索引,事务操作支持比较弱,没有统一标准。另外,表格模型支持 无模式(schema-less——特性,不需要预先定义每行包括哪些列以及每个列的类型,多行之间允许包含不同列。
2.3.4 SQL 与 NoSQL
非关系型数据库(NoSQL,Not Only SQL),良好的可扩展性,弱化一致性要求,一定程度上解决了海量数据和高并发的问题。
关系型数据库在海量数据场景存在问题:
- 事务。在分布式系统中,如果多个操作属于不同的服务器,保证它们的原子性需要用到两阶段提交协议,该协议性能很低,且不能容忍服务器故障,很难应用在海量数据场景。
- 联表。在海量数据场景,为了避免数据库多表关联操作,往往会使用数据冗余等违反数据库范式的手段。但是收益高于成本。
- 性能。
NoSQL 的问题:
- 缺少统一标准
- 使用及运维复杂。
2.4 事务并发控制
为了性能考虑,会定义多个隔离级别,事务的并发控制往往通过锁机制来实现,锁可以有不同粒度,可以锁住行,可以锁住数据块甚至整个表。
互联网业务,读比写多,为提高性能,可以采用 写时复制 (Copy-On-Write, COW) 或 多版本并发控制(Multi-Version Concurrency Control, MVCC) 来避免写事务阻塞读事务.
2.4.1 事务
- 原子性
- 一致性
- 隔离性
- 持久性
原子性
事务对数据的修改, 要么全执行, 要么全不执行. 如: A 转账一笔钱 x 给到 B, 结果必须是 A 扣了 x, B 加了 x.
一致性
数据的正确性、完整性、一致性。如:数据类型必须正确,数据值必须在规定范围内。
隔离性
保证每一个事务在它的修改全部完成之前,对其他事务是不可见的。还是上边的例子,转账过程中,查询操作不能看到 A 账户已经扣款 x,B 账户却还没扣款 x 的状态。
持久性
事务完成后,对数据库的影响是永久的。
处于性能考虑,允许使用者选择牺牲隔离属性换取并发度。
4 种隔离级别:
- Read Uncommitted (RU): 读取未提交的数据, 最低隔离级别.
- Read Committed (RC): 读取已提交的数据
- Repeatable Read (RR): 可重复读取.
- Serializable(S): 可序列化. 最高隔离级别
隔离级别的降低可能导致脏数据和事务执行异常, 如:
- Lost Update (LU): 丢失更新
- Dirty Reads (DR): 脏读. 一个事务读取了另一个事务更新却没有提交的数据.
- Non-Repeatable Reads (NRR): 对同一数据的多次读取得到不同的结果.
- Second Lost Updates problem (SLU): 第二类丢失更新. 两个并发事务同时读取和修改同一数据, 则后面的修改可能使得前面的修改失效.
- Phantom Reads (PR): 事务执行过程中, 由于前面的查询和后面的查询的期间有另外一个事务插入数据, 后面的查询结果出现了前面查询结果中未出现的数据.
| LU | DR | NRR | SLU | PR | |
| RU | N | Y | Y | Y | Y |
| RC | N | N | Y | Y | Y |
| RR | N | N | N | N | Y |
| S | N | N | N | N | N |
2.4.2 并发控制
数据库锁
读锁和写锁. 允许对同一行元素加多个读锁, 但只允许一个写锁. 这里的元素可以是一行, 一个数据块, 甚至一个表.
解决死锁的思路:
- 事务设置超时时间, 超时自动回滚.
- 死锁检测.
写时复制
读操作不加锁.
多版本并发控制
对每行数据维护多个版本.
InnoDB 对每一行维护两个隐含的列.
2.5 故障恢复
操作日志 (提交日志 Commit Log) 技术来实现故障恢复.
操作日志分为: 回滚日志 (UNDO Log), 重做日志(REDO Log) 以及 UNDO/REDO 日志.
记录事务修改前的状态, 则为回滚日志; 记录事务修改后的状态, 则为重做日志.
2.5.1 操作日志
通过操作日志顺序记录每个数据库操作并将在内存中执行这些操作, 内存中的数据定期刷新到磁盘, 实现将随机写请求转化为顺序写请求.
ℹ
示例:
事务 T 对表格中的 X 执行加 10 操作, 初始 X = 5, 更新后 X = 15, 那么
UNDO 日志记为 <T, X, 5>, REDO 日志记为 <T, X, 15>
UNDO/REDO 日志记为 <T, X, 5, 15>
2.5.2 重做日志
2.5.3 优化手段
- 成组提交(Group Commit)
- 检查点(checkpoint): 定期将内存中的数据 Dump 到磁盘,
2.6 数据压缩
有损和无损压缩.
无损: LZ 系列压缩算法. 如: GZip
压缩算法核心: 找重复数据. 列式存储大大提高了数据的压缩比.
2.6.1 压缩算法
- Huffman 编码
- LZ 系列压缩算法: 就基于字典的压缩算法
- BMDiff 与 Zippy (相比于传统 LZ, 优势在于处理速度非常快)
2.6.2 列式存储
OLAP: 一个查询要访问几百万甚至几十亿数据行, 且查询往往只关心少数几个列. 如: 查询今年销量最高的前 20 个商品. 只关注 3 列: 时间, 商品和销量.
列组(column group): 多个经常一起访问的数据列的各个值存放在一起.
由于同一列数据重复度很高, 因此, 列式数据库压缩时有很大优势.
可以针对列式存储做专门索引优化.




