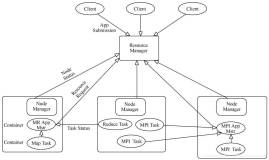
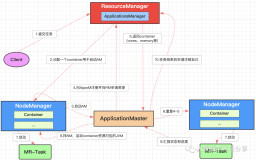
- yarn资源隔离类别
- Yarn Node Label资源隔离
- Yarn 使用 Cgroup 实现任务资源限制
YARN资源隔离类别




Yarn Node Lable资源隔离
背景
当Hadoop集群需要提供SLA资源隔离的时候,有两个选择,一个是独立建立新的集群,另一个是通过yarn node label特性来通过软件设置隔离。这里介绍后者来实现方案落地。
构建步骤
步骤1,Node-Label相关配置,加在yarn-site.xml里面,目前只有capacity scheduler支持比较好。
<property> <name>yarn.node-labels.enabled</name> <value>true</value> </property> <property> <name>yarn.node-labels.fs-store.root-dir</name> <value>file:///home/yarn/node-label</value> </property> <property> <name>yarn.resourcemanager.scheduler.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value> </property>
然后启动rm。
步骤2,添加label标签。
yarn rmadmin -addToClusterNodeLabels "label1,label2"
步骤3,給nodemager节点打上标签
yarn rmadmin -replaceLabelsOnNode "hostname1,label1 hostname2,label2"
步骤4,給nodemager节点打上标签
yarn rmadmin -replaceLabelsOnNode "hostname1,label1 hostname2,label2"
注意这里的格式为,label+空格区分+,label2。然后可以通过命令行或RM UI观察标签是否打成功。
步骤5,划分队列标签。在root队列下划分出a,b队列,a队列的任务对应label1标签,b对应label2标签。配置如下:
<property> <name>yarn.scheduler.capacity.root.accessible-node-labels.label1.capacity</name> <value>100</value> </property> <property> <name>yarn.scheduler.capacity.root.accessible-node-labels.label2.capacity</name> <value>100</value> </property> <property> <name>yarn.scheduler.capacity.root.a.accessible-node-labels</name> <value>label1</value> </property> <property> <name>yarn.scheduler.capacity.root.b.accessible-node-labels</name> <value>label2</value> </property> <property> <name>yarn.scheduler.capacity.root.a.capacity</name> <value>30</value> </property> <property> <name>yarn.scheduler.capacity.root.b.capacity</name> <value>10</value> </property> <property> <name>yarn.scheduler.capacity.root.a.accessible-node-labels.label1.capacity</name> <value>100</value> </property> <property> <name>yarn.scheduler.capacity.root.b.accessible-node-labels.label2.capacity</name> <value>100</value> </property> <property> <name>yarn.scheduler.capacity.root.a.default-node-label-expression</name> <value>label1</value> </property> <property> <name>yarn.scheduler.capacity.root.b.default-node-label-expression</name> <value>label2</value> </property> <property> <name>yarn.scheduler.capacity.root.default.default-node-label-expression</name> <value></value> </property>
步骤6,刷新队列
yarn rmadmin -refreshQueues
通过UI观察是否配置生效,标签是否已加入队列a,b.
步骤6,指定队列,提交hive任务,判断任务是否只允许再标签对应的节点上。经过多次分标签a,b测试,的确跑在标签所属下的节点上。
步骤7, 压测 通过压测程序进行label标签下的分配测试,运行SliveTest,执行命令如下:
cd /home/vipshop/platform/hadoop-2.7.6/share/hadoop/mapreduce/ yarn jar hadoop-mapreduce-client-jobclient-2.7.6.jar SliveTest -maps 40 -duation 172800 -reduce 20 -blockSize 1073741824 -files 10000000 -dirs 50000
没有发现性能问题,RM连续分配40个Container在指定标签下。

使用场景
1.1:集群中新节点和旧节点作业分配(依据作业场景或者作业业务线) 新加的节点可能是配置较高的,可运行一些可能导致iops、负载、cpu等性能指标上升的作业(如果去老的节点中运行存在导致整体io风暴(spark shuffle(可通过rss解决)),影响集群负载上升,影响监控指标判断) 1.2:存储计算分离,传统部署模式,dn与nm部署在一起,在集群扩容到一定的节点数量时,应该考虑存储与计算分离,可以将nm建在新的节点上,原始的node上共存的nm可以运行一些较小的作业 1.3:新加的node是GPU计算资源,需要通过NodeLabel隔离
Yarn使用cgroup实现任务资源限制
Linux CGroup 全称是 Linux Control Group,是 Linux 内核提供的一个用来限制进程资源使用的功能,支持如 CPU, 内存,磁盘 IO 等资源的使用限制。用户可以使用 CGroup 对单个进程或者一组进程进行精细化的资源限制,具体使用方式可以查看参考文档。
目前, Yarn NodeManager 能够使用 CGroup 来限制所有 containers 的资源使用,主要是 CPU 资源。如果不用 CGroup, 在 NM 端很难实现对 container 的 CPU 使用进行限制。默认状态下, container 的 CPU 使用是没有限制的,container 申请了 1 vcore ,实际上能够使用所有的 CPU 资源。所以如果 NM 上分配了一个 vcore 申请较少实际上 CPU 使用极高的任务,常常会导致节点上运行的所有的任务都延时。
NM 运行时,可以通过 ContainersMonitor 线程监控 container 内存和 CPU 使用。对于 container 内存使用, 一旦发现其超出申请内存大小,就会立即发起 kill container 命令,回收 container 的资源。ContainersMonitor 虽然也支持 CPU 使用监控,但是 CPU 资源不像内存资源,其使用量的峰值是基本上可以确定的,在所有机器或者系统上都基本一致。CPU 受限于 CPU 硬件性能, 同一个任务在不同的机器上的 CPU 使用率可能差异巨大,所以不能发现 container CPU 使用超过申请大小就 kill container 。同时,由于 container 都是由子进程的方式启动的, NM 也是很难通过直接控制 container 运行和暂停来调整其 CPU 使用率。因此,在没有 CGroup 功能的情况下, NM 是很难直接限制 container 的 CPU 使用的。
所以接下来我们主要介绍 Yarn 如何启用 CGroup 来限制 containers CPU 资源占用。
安装Cgroup
默认系统已经安装了cgroup了,如果没有安装可以通过命令安装
# CentOS 6 yum install -y libcgroup # CentOS 7 yum install -y libcgroup-tools
然后通过命令启动
# CentOS 6 /etc/init.d/cgconfig start # CentOS 7 systemctl start cgconfig.service
查看/cgroup目录,可以看到里面已经创建了一些目录,这些目录就是可以隔离的资源
drwxr-xr-x 2 root root 0 11月 12 20:56 blkio drwxr-xr-x 3 root root 0 11月 12 20:56 cpu drwxr-xr-x 2 root root 0 11月 12 20:56 cpuacct drwxr-xr-x 2 root root 0 11月 12 20:56 cpuset drwxr-xr-x 2 root root 0 11月 12 20:56 devices drwxr-xr-x 2 root root 0 11月 12 20:56 freezer drwxr-xr-x 2 root root 0 11月 12 20:56 memory drwxr-xr-x 2 root root 0 11月 12 20:56 net_cls
如果目录没有创建可以执行
cd / mkdir cgroup mount -t tmpfs cgroup_root ./cgroup mkdir cgroup/cpuset mount -t cgroup -ocpuset cpuset ./cgroup/cpuset/ mkdir cgroup/cpu mount -t cgroup -ocpu cpu ./cgroup/cpu/ mkdir cgroup/memory mount -t cgroup -omemory memory ./cgroup/memory/
通过cgroup隔离cpu资源的步骤为:
1:在cpu目录创建分组 2:cgroup以组为单位隔离资源,同一个组可以使用的资源相同 3:一个组在cgroup里面体现为一个文件夹,创建分组直接使用`mkdir`命令即可. 4:组下面还可以创建下级组.最终可以形成一个树形结构来完成复杂的资源隔离方案. 5:每当创建了一个组,系统会自动在目录立即创建一些文件,资源控制主要就是通过配置这些文件来完成
--w--w--w- 1 root root 0 11月 12 21:09 cgroup.event_control -rw-r--r-- 1 root root 0 11月 12 21:09 cgroup.procs -rw-r--r-- 1 root root 0 11月 12 21:09 cpu.cfs_period_us -rw-r--r-- 1 root root 0 11月 12 21:09 cpu.cfs_quota_us -rw-r--r-- 1 root root 0 11月 12 21:09 cpu.rt_period_us -rw-r--r-- 1 root root 0 11月 12 21:09 cpu.rt_runtime_us -rw-r--r-- 1 root root 0 11月 12 21:09 cpu.shares -r--r--r-- 1 root root 0 11月 12 21:09 cpu.stat -rw-r--r-- 1 root root 0 11月 12 21:09 notify_on_release -rw-r--r-- 1 root root 0 11月 12 21:09 tasks
cgroup隔离策略
hard limit
在 yarn.nodemanager.linux-container-executor.cgroups.strict-resource-usage 设置为 true 时生效。通过改变cpu.cfs_quota_us和cpu.cfs_period_us文件控制cpu资源使用的上限。
严格按照任务初始分配的cpu进行限制,即使还有空闲的CPU资源也不会占用。
可使用核数 = cpu.cfs_quota_us/cpu.cfs_period_us yarn 是通过降低 cpu.cfs_period_us的值来实现控制;在yarn中cpu.cfs_quota_us被直接设置为1000000(这个参数可以设置的最大值) 然后根据任务申请的core来计算出cpu.cfs_period_us按比例隔离资源 按每个分组里面cpu.shares的比率来分配cpu
计算公式
- containerVCores 单个 container 申请的core
- yarnProcessors nodemanager 所在节点的物理
core * yarn.nodemanager.resource.percentage-physical-cpu-limit - nodeVcores nodemanager 设置的 VCore 数量
containerCPU = (containerVCores * yarnProcessors) / (float) nodeVCores
例如一台4核的虚拟机,VCore 设置为8,启动一个vcore 为 1 的 Container,在 yarn.nodemanager.resource.percentage-physical-cpu-limit 为 100的情况下,使用率不会超过50%
如果将yarn.nodemanager.resource.percentage-physical-cpu-limit设置为90,则每个Container的cpu使用率不会超过45%
soft limit
在 yarn.nodemanager.linux-container-executor.cgroups.strict-resource-usage 设置为 false 时生效,通过 cpu.shares 文件控制资源使用,该参数只能控制资源使用的下限。
按比例对资源进行限制,在这种模式下,允许 Container 使用额外的空闲CPU资源。
根据不同场景选择限制模式

启用
NM 启用 CGroup 功能主要需要在 yarn-site.xml 里设置以下配置:
- 启用 LCE :
在 Nodemanager 中, CGroup 功能集成在 LinuxContainerExecutor 中,所以要使用 CGroup 功能,必须设置 container-executor 为 LinuxContainerExecutor. 同时需要配置 NM 的 Unix Group,这个是可执行的二进制文件 container-executor 用来做安全验证的,需要与 container-executor.cfg 里面配置的一致。详细配置可参见 Yarn ContainerExecutor 配置与使用。
<property> <name>yarn.nodemanager.container-executor.class</name> <value>org.apache.hadoop.yarn.server.nodemanager.LinuxContainerExecutor<value> </property> <property> <name>yarn.nodemanager.linux-container-executor.group</name> <value>hadoop<value> </property>
2. 启用 CGroup :
LinuxContainerExecutor 并不会强制开启 CGroup 功能, 如果想要开启 CGroup 功能,必须设置 resource-handler-class 为 CGroupsLCEResourceHandler.
<property> <name>yarn.nodemanager.linux-container-executor.resources-handler.class</name> <value>org.apache.hadoop.yarn.server.nodemanager.util.CgroupsLCEResourcesHandler<value> </property>
3. 配置 Yarn CGroup 目录:
NM 通过 yarn.nodemanager.linux-container-executor.cgroups.hierarchy 配置所有 Yarn Containers 进程放置的 CGroup 目录。
如果系统的 CGroup 未挂载和配置,可以在系统上手动挂载和配置和启用 CGroup 功能,也可以通过设置 yarn.nodemanager.linux-container-executor.cgroups.mount 为 true,同时设置 CGroup 挂载路径 yarn.nodemanager.linux-container-executor.cgroups.mount-path 来实现 NM 自动挂载 CGroup (不建议这样用,问题挺多)。
如果系统的 CGroup 已经挂载且配置完成,而且 Yarn 用户有 CGroup cpu 子目录的写入权限,NM 会在 cpu 目录下创建 hadoop-yarn 目录 ,如果该目录已经存在,保证 yarn 用户有写入权限即可。
<property> <name>yarn.nodemanager.linux-container-executor.cgroups.hierarchy</name> <value>/hadoop-yarn<value> </property> <property> <name>yarn.nodemanager.linux-container-executor.cgroups.mount</name> <value>false<value> </property> <property> <name>yarn.nodemanager.linux-container-executor.cgroups.mount-path</name> <value>/sys/fs/cgroup<value> </property>
4. CPU 资源限制:
NM 主要使用两个参数来限制 containers CPU 资源使用。
首先,使用 yarn.nodemanager.resource.percentage-physical-cpu-limit 来设置所有 containers 的总的 CPU 使用率占用总的 CPU 资源的百分比。比如设置为 60,则所有的 containers 的 CPU 使用总和在任何情况下都不会超过机器总体 CPU 资源的 60 %。
然后,使用 yarn.nodemanager.linux-container-executor.cgroups.strict-resource-usage 设置是否对 container 的 CPU 使用进行严格限制。如果设置为 true ,即便 NM 的 CPU 资源比较空闲, containers CPU 使用率也不能超过限制,这种配置下,可以严格限制 CPU 使用,保证每个 container 只能使用自己分配到的 CPU 资源。但是如果设置为 false ,container 可以在 NM 有空闲 CPU 资源时,超额使用 CPU,这种模式下,可以保证 NM 总体 CPU 使用率比较高,提升集群的计算性能和吞吐量,所以建议使用非严格的限制方式(实际通过 CGroup 的 cpu share 功能实现)。不论这个值怎么设置,所有 containers 总的 CPU 使用率都不会超过 cpu-limit 设置的值。
NM 会按照机器总的 CPU num* limit-percent 来计算 NM 总体可用的实际 CPU 资源,然后根据 NM 配置的 Vcore 数量来计算每个 Vcore 对应的实际 CPU 资源,再乘以 container 申请的 Vcore 数量计算 container 的实际可用的 CPU 资源。这里需要注意的是,在计算总体可用的 CPU 核数时,NM 默认使用的实际的物理核数,而一个物理核通常会对应多个逻辑核(单核多线程),而且我们默认的 CPU 核数通常都是逻辑核,所以我们需要设置 yarn.nodemanager.resource.count-logical-processors-as-cores 为 true 来指定使用逻辑核来计算 CPU 资源。
<property> <name>yarn.nodemanager.resource.percentage-physical-cpu-limit</name> <value>80<value> </property> <property> <name>yarn.nodemanager.linux-container-executor.cgroups.strict-resource-usage</name> <value>false<value> </property> <property> <name>yarn.nodemanager.resource.count-logical-processors-as-cores</name> <value>true<value> </property>
相关参数配置和说明