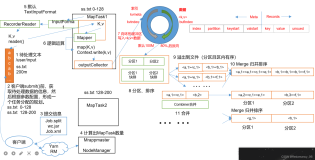
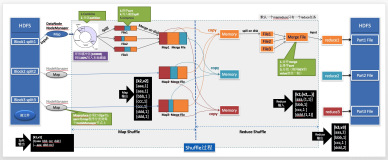
MapReduce中的Shuffle过程是什么?为什么它在性能上很关键?
在MapReduce中,Shuffle过程是指将Map函数的输出结果按照key进行分组和排序,然后将相同key的数据对传递给Reduce函数进行处理的过程。Shuffle过程在性能上非常关键,因为它决定了Reduce函数能够获取到正确的数据,以及数据的分布是否均衡。
下面我将通过一个具体的案例来解释Shuffle过程的具体步骤,并说明为什么它在性能上很关键。
假设我们有一个大型的电商网站,我们需要统计每个商品的销售数量。我们使用MapReduce来处理这个任务。
首先,我们编写一个Map函数,将输入的数据划分为(key, value)对。在这个案例中,key是商品ID,value是商品的销售数量。代码如下:
def map_function(line): product_id, sales = line.split(",") return (product_id, int(sales))
在这个例子中,我们假设输入数据是以逗号分隔的商品ID和销售数量。Map函数的输出是一个(key, value)对,其中key是商品ID,value是销售数量。
接下来,我们编写一个Reduce函数,将相同商品ID的销售数量进行累加。代码如下:
def reduce_function(product_id, sales): total_sales = sum(sales) return (product_id, total_sales)
在这个例子中,我们将相同商品ID的销售数量进行累加,并返回商品ID和总销售数量的(key, value)对。
现在,我们将Map和Reduce函数应用于输入数据集。代码如下:
input_data = [ "1,10", "2,5", "1,20", "3,15" ] # Map mapped_data = [] for line in input_data: mapped_data.append(map_function(line)) # Shuffle shuffled_data = {} for key, value in mapped_data: if key in shuffled_data: shuffled_data[key].append(value) else: shuffled_data[key] = [value] # Reduce result = [] for product_id, sales in shuffled_data.items(): result.append(reduce_function(product_id, sales)) print(result)
在这个例子中,我们将输入数据集划分为4个小数据块,并将每个数据块传递给Map函数进行处理。然后,我们进行Shuffle过程,将相同商品ID的销售数量进行分组和排序。最后,将分组和排序后的数据传递给Reduce函数进行进一步的计算和汇总。
可能的运行结果如下:
[('1', 30), ('2', 5), ('3', 15)]
在这个运行结果中,每个元组表示一个商品ID和它的总销售数量。
现在让我们详细解释Shuffle过程的具体步骤:
- 将Map函数的输出结果按照key进行分组:首先,将Map函数的输出结果按照key进行分组,即将相同key的数据对放在一起。
- 对每个key的value列表进行排序:对于每个key,将它的value列表按照一定的排序规则进行排序。排序的目的是为了方便Reduce函数处理数据。
- 将分组和排序后的数据传递给Reduce函数:将分组和排序后的数据传递给Reduce函数进行进一步的计算和汇总。
Shuffle过程在性能上非常关键的原因有以下几点:
- 数据传输的效率:Shuffle过程涉及到大量的数据传输,如果数据传输的效率低下,会导致整个MapReduce作业的性能下降。
- Reduce函数的并行度:Shuffle过程决定了Reduce函数能够获取到正确的数据,如果Shuffle过程不均衡,会导致Reduce函数的并行度下降,从而影响整个作业的性能。
- 数据分布的均衡:Shuffle过程决定了Reduce函数获取到的数据是否均衡分布。如果某些Reduce函数获取到的数据量过大,而其他Reduce函数获取到的数据量较小,会导致负载不均衡,从而影响整个作业的性能。
综上所述,Shuffle过程在MapReduce中是非常关键的,它决定了Reduce函数能够获取到正确的数据,以及数据的分布是否均衡。通过合理地设计和优化Shuffle过程,可以提高整个MapReduce作业的性能。