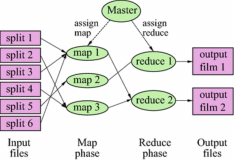
什么是MapReduce?请简要解释其工作原理。
MapReduce是一种用于大规模数据处理的编程模型和计算框架。它的设计目标是将大规模数据集分布式处理,以便高效地进行并行计算。MapReduce模型由两个主要操作组成:Map和Reduce。
Map操作将输入数据集划分为若干个小数据块,并将每个数据块映射为(key, value)对。然后,Map操作将这些(key, value)对传递给Reduce操作进行处理。Reduce操作将相同key的数据对聚合在一起,并进行进一步的计算和汇总,生成最终的输出结果。
下面是一个简单的例子来说明MapReduce的工作原理。假设我们有一个文本文件,其中包含一些单词。我们需要统计每个单词在文件中出现的次数。
首先,我们编写一个Map函数,将输入的文本文件划分为单词,并为每个单词生成(key, value)对。代码如下:
def map_function(line): words = line.split() word_count = {} for word in words: if word in word_count: word_count[word] += 1 else: word_count[word] = 1 return word_count
在这个例子中,我们将每行文本划分为单词,并使用字典来记录每个单词的出现次数。
接下来,我们编写一个Reduce函数,将相同单词的出现次数进行累加。代码如下:
def reduce_function(word, counts): total_count = sum(counts) return (word, total_count)
在这个例子中,我们将相同单词的出现次数进行累加,并返回单词和总次数的(key, value)对。
最后,我们将Map和Reduce函数应用于输入数据集。代码如下:
input_data = [ "hello world", "hello flink", "flink is awesome", "hello world" ] # Map mapped_data = [] for line in input_data: mapped_data.append(map_function(line)) # Reduce word_counts = {} for word_count in mapped_data: for word, count in word_count.items(): if word in word_counts: word_counts[word].append(count) else: word_counts[word] = [count] result = [] for word, counts in word_counts.items(): result.append(reduce_function(word, counts)) print(result)
在这个例子中,我们将输入数据集划分为4个小数据块,并将每个数据块传递给Map函数进行处理。然后,将Map函数的输出传递给Reduce函数进行进一步的计算和汇总。最终,我们得到每个单词在输入数据集中的出现次数。
可能的运行结果如下:
[('hello', 3), ('world', 2), ('flink', 2), ('is', 1), ('awesome', 1)]
在这个运行结果中,每个元组表示一个单词和它在输入数据集中的出现次数。
通过这个例子,我们可以看到MapReduce的工作原理:将大规模数据集划分为小数据块,通过Map操作将每个数据块映射为(key, value)对,然后通过Reduce操作将相同key的数据对进行聚合和计算,最终生成输出结果。