<template> <div> <el-button type="success" icon="el-icon-copy-document" @click="pasteText = '', visible = true">快捷粘贴(Ctrl+V)</el-button> <el-dialog title="粘贴信息" :visible.sync="visible" append-to-body :close-on-click-modal="false" :close-on-press-escape="false" > <el-input type="textarea" ref="textarea" :rows="10" placeholder="输入文字信息或直接粘贴图片" v-model="pasteText" maxlength="1000" show-word-limit @paste="paste"></el-input> <i class="upload-bg-img el-icon-picture"></i> <div slot="footer" class="dialog-footer"> <el-button @click="close">取消</el-button> <el-button type="primary" @click="ok">确定</el-button> </div> </el-dialog> </div> </template> <script> import $ from 'jquery';//cnpm i jquery -s export default { data() { return { pasteText: '', visible: false, }; }, destroyed(d) { document.removeEventListener('paste', this.paste) }, created() { document.addEventListener('paste', this.paste) }, methods: { // 粘贴 paste(event) { if (this.visible) return; // 文本---------------------------------------- const text = (event.clipboardData || window.clipboardData).getData('text'); if (text && text.trim()) { // console.log('粘贴的文本', text); this.pasteText = text; this.handleText(this.pasteText); return; } // 图片---------------------------------------- let image = null; const items = (event.clipboardData || window.clipboardData).items; if (!items || items.length === 0) return this.$message.error('当前浏览器不支持本地打开图片,请复制粘贴文本内容!'); for (let i = 0; i < items.length; i++) { if (items[i].type.indexOf('image') !== -1) { image = items[i].getAsFile(); break; } } if (image) { // console.log('粘贴的图片', image); this.handleImage(image); return; } if (!text || !image) return this.$message.error('请粘贴文本或图片'); }, handleText(d) { let aa = d .replace(/\n(\n)*( )*(\n)*\n/g, "\n")//去掉多余空行 .split('\n');//每一行作为一条数据 let r = []; for (let i = 0, len = aa.length; i < len; i++) { let a = aa[i].trim().replace(/\s+/g, " ");//将连续多余空格缩减为一个空格 a && r.push(a.split(" ")); } this.$emit('result', r); }, handleImage(d) { const reader = new FileReader(); reader.readAsDataURL(d); reader.onload = e => { // e.target.result 即为base64结果 let data = { image: e.target.result } data = JSON.stringify(data); // 粘贴上传图片接口调用(帮助文档:https://www.apispace.com/eolink/api/ocrbase/apiDocument#scroll=0) $.ajax({ url: "https://eolink.o.apispace.com/ocrbase/ocr/v1/base", method: "POST", headers: { "X-APISpace-Token": "自己去www.apispace.com申请", "Authorization-Type": "apikey", "Content-Type": "application/json" }, data, crossDomain: true }) .done(d => { this.pasteText = d.words_result.map(v => v.word).join('\n') this.visible = true; }) .fail(d => { this.$message.error(JSON.parse(d.responseText).msg); }); }; }, // 取消 close(d) { this.visible = false; }, // 确定 ok(d) { if (this.pasteText && this.pasteText.trim()) { this.handleText(this.pasteText); this.close(); } else this.$message.error(this.$refs.textarea.$el.querySelector("textarea").placeholder); }, } }; </script> <style lang="scss" scoped> .dialog-footer { display: flex; &>* { width: 100%; } } >>>.el-textarea { z-index: 1; .el-textarea__inner { min-height: 200px !important; max-height: 500px; background-color: transparent; } } .upload-bg-img { display: block; position: absolute; margin: auto; top: 0; left: 0; right: 0; bottom: 0; width: 100px; height: 100px; font-size: 100px; transform: translateY(-10px); color: #eee; pointer-events: none; z-index: 0; } </style>
调用paste组件
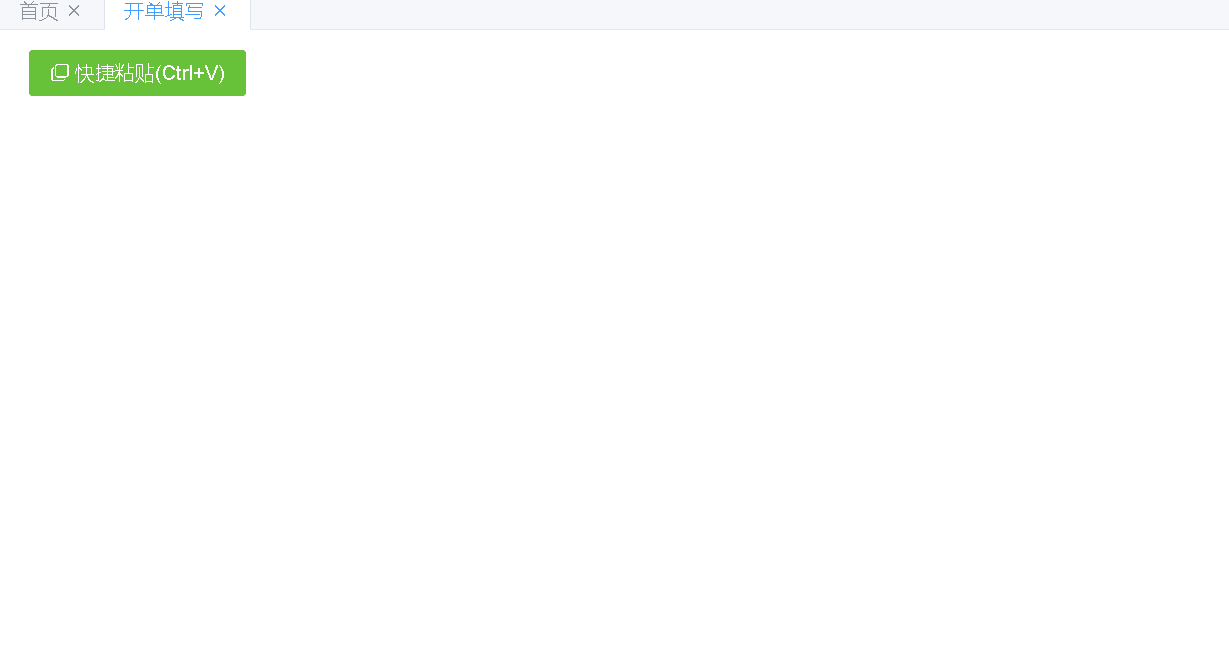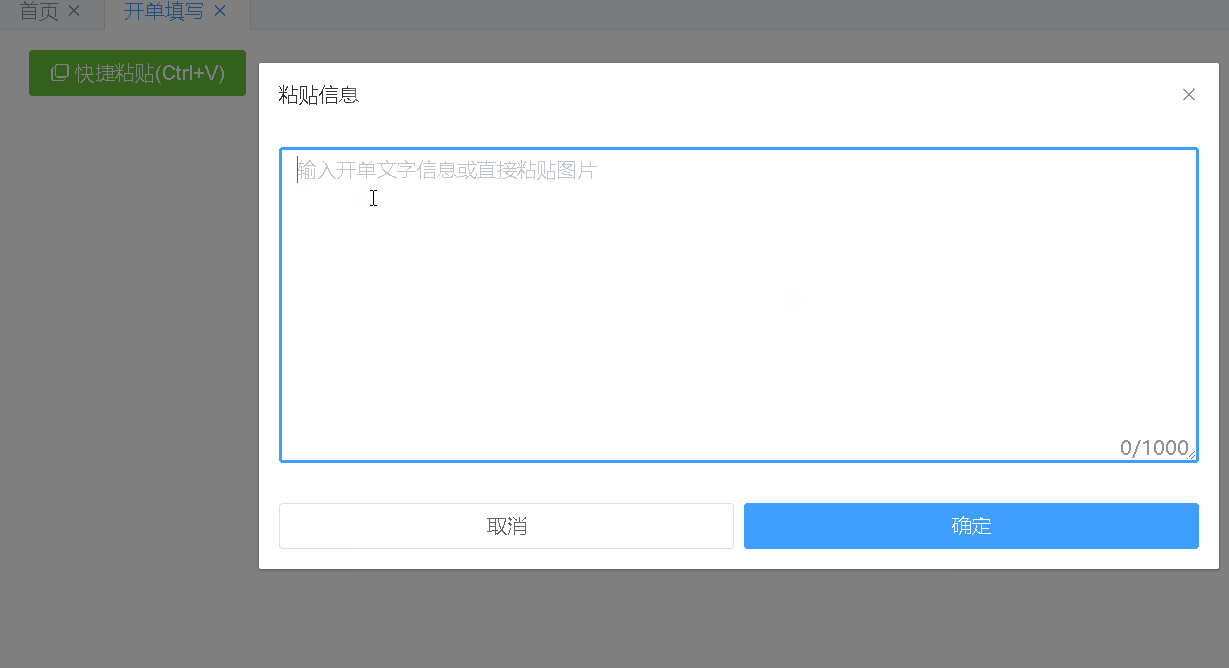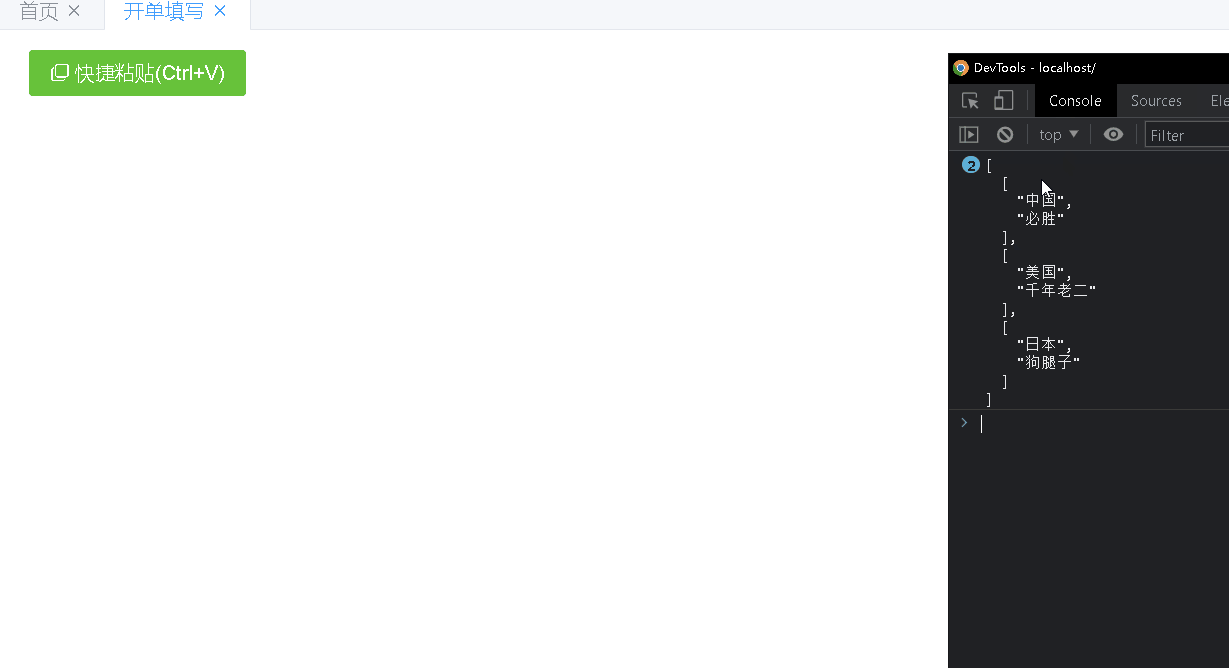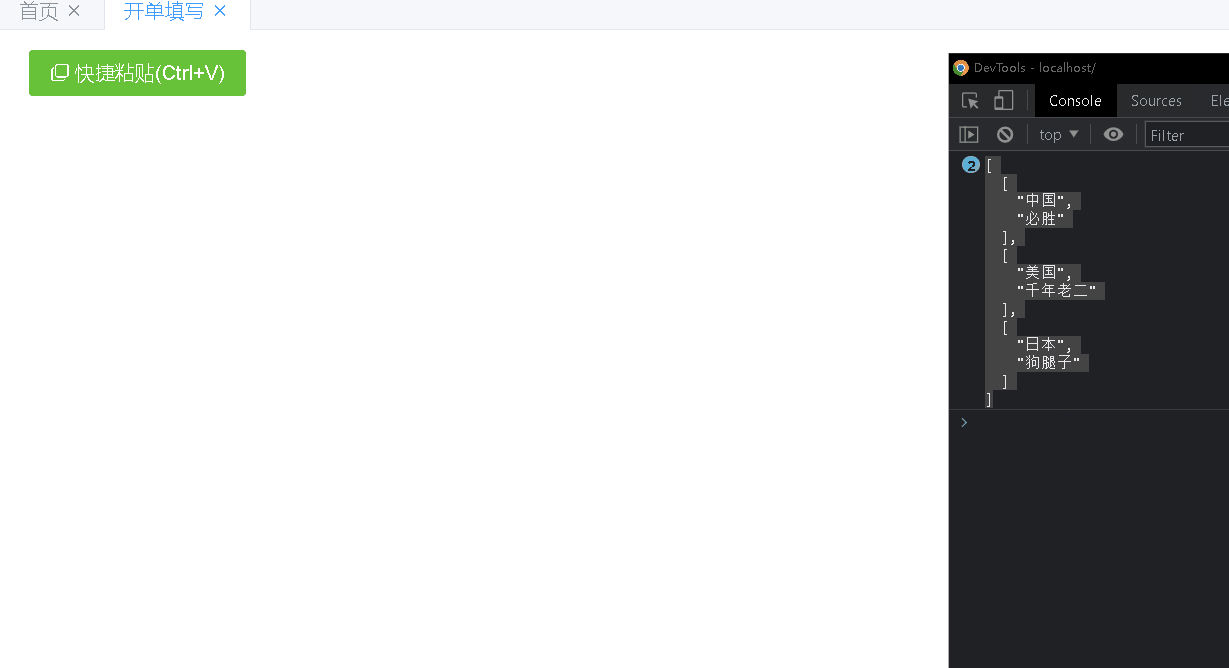
<paste @result="pasteResult"></paste> ... import paste from "@/vue/components/paste"; ... components: { paste, }, ... pasteResult(d) { console.log(JSON.stringify(d, null, 2));//输入内容见下面gif截图 },