
【数据结构】手撕排序(一):https://developer.aliyun.com/article/1392774
四、希尔排序
- 基本思想
希尔排序又称缩小增量法,其基本思想是:选出一个整数gap表示增量,根据gap将待排序的记录分为gap组,所有距离为gap的记录分在同一组,然后对每一组进行直接插入排序。随着排序次数的增多,增量gap逐渐减少,当gap=1时,即所有记录分在同一组进行直接插入排序,排序完成后序列便有序了,算法结束。分组方法如下:


过程分析:
- 首先,我们需要对gap的初始值进行确定,这并没有一个确定的答案,一般是按照数据量来进行选取。一般我们选取gap = n/3 + 1或者gap = n/2作为gap的初始值。
- 根据算法的思想,我们观察到gap是在不断地进行缩小,最后缩小到1进行直接插入排序。因此我们gap的缩小增量可以继续使用gap = gap/3 + 1或gap = n/2来表示。
- 对1、2点进行合并后,我们可以这样用来表示gap的迭代更新:
int gap = n; //n为序列元素个数 while(gap > 1) { //gap = gap/2; gap = gap/3 + 1; //每组进行直接插入排序 //... }
上面的循环在以下两种情况下会结束:
- n == 1:即序列只有一个元素,此时无需进行排序,不会进入循环
- n != 1 ,gap == 1:由于gap的更新是在插入排序之前,因此当循环判断到gap == 1时,上一次进行的就是以1为gap增量的直接插入排序,此时序列已经有序,退出循环。
为什么要取gap = gap/3 + 1而不是gap = gap/3?
由于最后gap要缩小到1进行直接插入排序,而如果我们选取gap = gap/3时,假设gap初始为6,第一次更新后gap=2,第二次更新后gap=0(向下取整),循环便结束了,并不会进行gap=1时的插入排序。因此,为了避免这种情况的发生,我们让gap = gap/3 + 1保证最后一次gap一定为1。
那为什么取gap = gap/2而不是gap = gap/2 + 1?
这种情况不需要处理的原因是gap不可能等于0,因为进入循环的条件是gap>1,而gap只有等于0或1时gap/2才会为0。因此,无论gap初始为多少,最后一定都会在gap=1处停下。并且,当gap=2时,使用gap = gap/2 + 1会出现死循环/font>噢
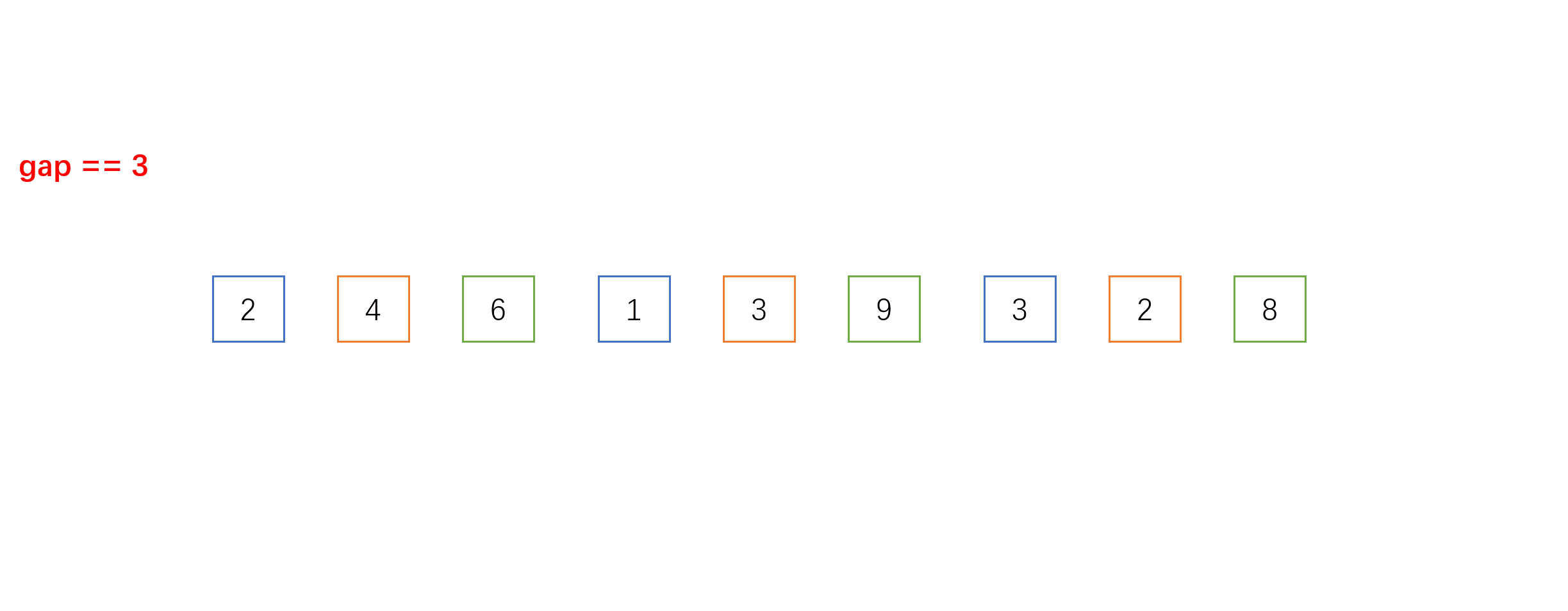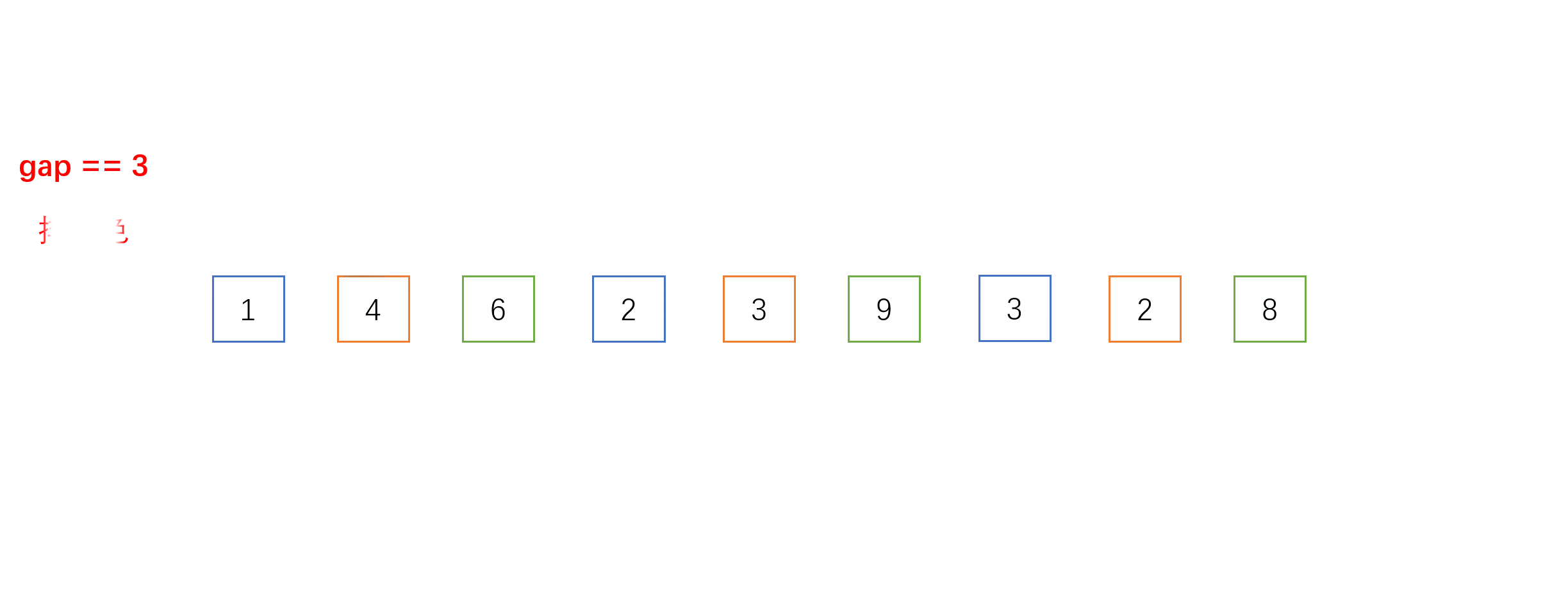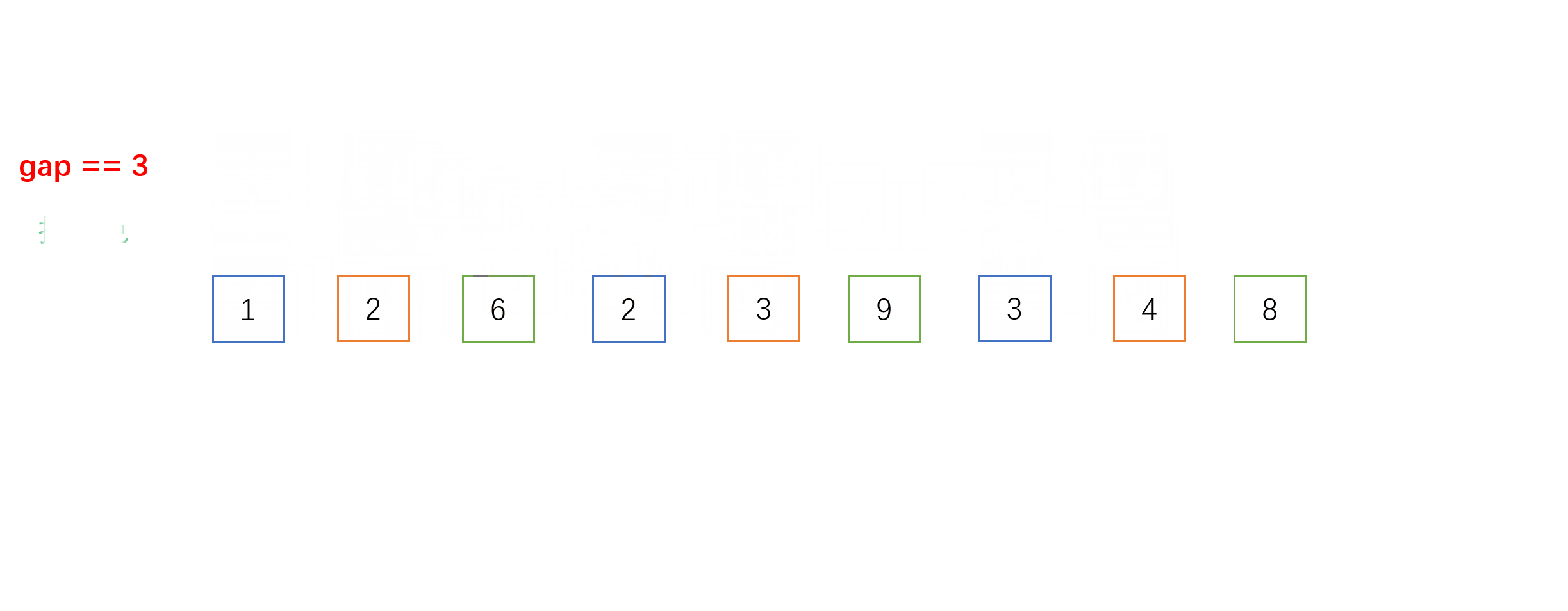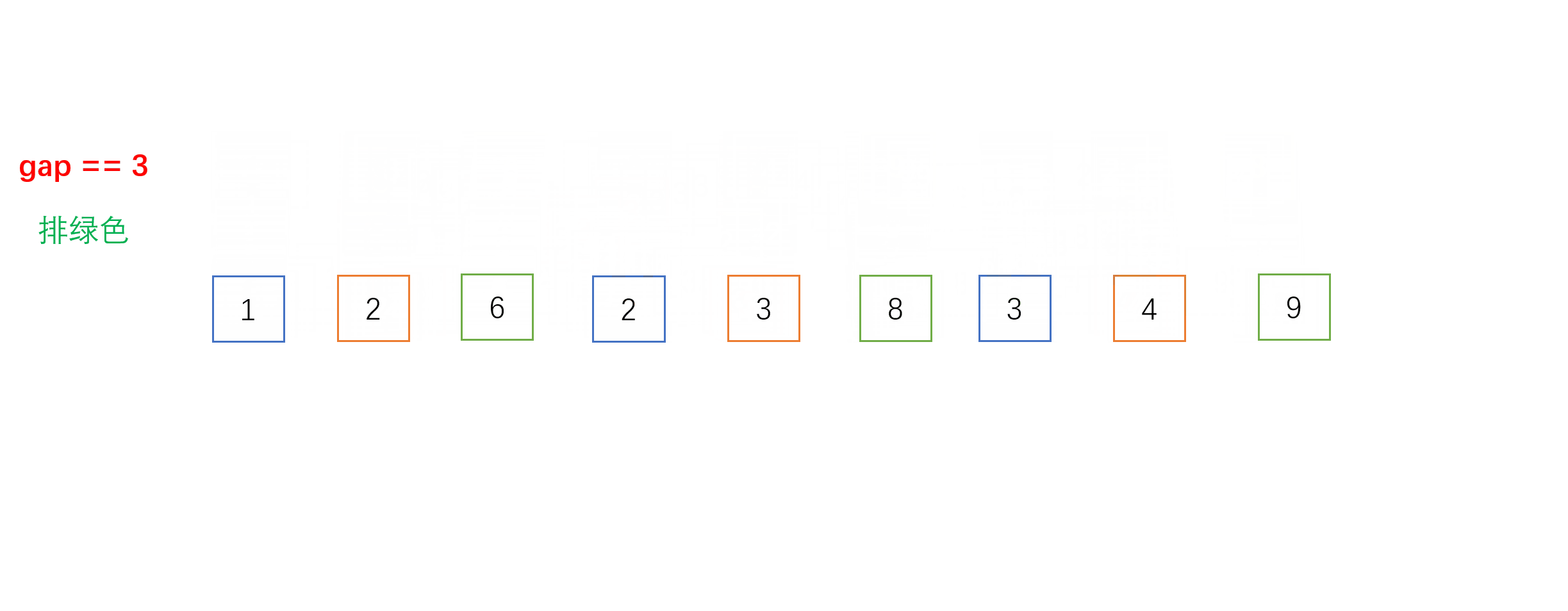
- 每组之间进行的就是我们上面介绍的直接插入排序,不一样的是相邻元素的距离是gap而不是1。以下是gap = 3时的单趟希尔排序的动图过程:
- 下面是希尔排序的全过程(以gap = gap/3 + 1为例):
- 通过观察,我们可以发现实际上希尔排序就是直接插入排序的优化版。随着每一趟的分组排序,序列越来越接近有序。前面我们说过,直接插入排序在序列越接近有序的情况下效率越高,希尔排序就是通过每趟的预排序来使得序列越来越接近有序,从而提高直接插入排序的整体效率。
- 要点提炼:当gap > 1时,对序列进行分组预排序,目的是使得序列越来越接近有序;当gap == 1时,数组接近有序,此时进行直接插入排序效率大幅提高。
//写法1:一组一组排 void ShellSort1(int* a, int n) { int gap = n; while (gap > 1) { //1:gap > 1,预排序 //2:gap == 1,直接插入排序 gap = gap / 3 + 1; //缩小增量 for (int j = 0; j < gap; j++) //一组一组进行插入排序,共gap组 { //对当前组进行直接插入排序,组内相邻元素相距gap。 //(其实就相当于把上面介绍的直接插入排序代码中的-1改成-gap即可) for (int i = j; i < n - gap; i += gap) { int end = i; int tmp = a[end + gap]; while (end >= 0) { if (tmp < a[end]) { a[end + gap] = a[end]; end -= gap; } else { break; } } a[end + gap] = tmp; } } } }
但是,上面的代码实际上还可以写得更加简洁
我们知道每个组的元素都相距gap,而组与组之间距离都为1。那么,我们实际上不用一组一组分开排,而是采用多组并排的方式,这样就可以少写一个for循环,代码如下
void ShellSort(int* a, int n) { int gap = n; while (gap > 1) { gap = gap / 3 + 1; for (int i = 0; i < n - gap; i++) { int end = i; int tmp = a[end + gap]; while (end >= 0) { if (tmp < a[end]) { a[end + gap] = a[end]; end -= gap; } else { break; } } a[end + gap] = tmp; } } }
复杂度/稳定性分析
复杂度:
尽管上面的代码有多个循环嵌套,但这并不意味着希尔排序的效率低下。我们根据代码来分析一下希尔排序的时间复杂度,过程如下图所示:

我们可以看到,在gap很大或者gap很小的情况下,每趟排序的时间复杂度为O(N),共进行log3n趟,那我们是不是可以认为希尔排序的时间复杂度为O(NlogN)?实际上并不行,因为当gap处于中间的过程时,时间复杂度的分析实际上是个很复杂的数学问题。每一趟预排序之后都对下一趟排序造成影响,这就好比叠buff的过程。

以下分别是两本书中对希尔排序时间复杂度的说法:
1、《数据结构(C语言版)》— 严蔚敏
2、《数据结构-用面相对象方法与C++描述》— 殷人昆


因为我们上面的gap是按照Knuth提出的方式取值的,并且Knuth进行了大量的试验统计,时间复杂度我们就按照:O(n^1.25)到O(1.6n^1.25)来进行取值。
然后就是空间复杂度,由于我们依旧只用到了常数级的辅助变量,因此空间复杂度为O(1)。
稳定性:
由于希尔排序是分组进行排序,当相同的数被分到不同组时,很可能就会改变相同的数的顺序,因此,希尔排序是不稳定的排序。

五、 选择排序
- 思想 : 每一次从待排序的数据元素中选出最小(升序)或最大(降序)的一个元素,存放在序列的起始位置,直到全部待排序的数据元素排完。
- 选择过程:以下是对某个序列进行选择排序的过程:

- 动图演示:我们一样通过动图感受一下选择排序的过程:
- 循环控制:类似的,我们需要两层循环来控制选择排序的过程。内层循环遍历序列找出最大/最小值,外层循环控制选择的次数。
- 外层循环结束条件:每一次遍历完都可以选出一个数换到起始位置,一共N个数,故要选N-1次(最后一个数不需要选择)
for (int i = 0; i < n-1; i++) //外层循环,共要选择n-1次 { ; }
- 内层循环结束条件:内层循环通过比较进行选数,一开始N个数需要比较N-1次,然后每趟结束后下一次选择的起始位置就往后移动一位,比较次数减1
for (int i = 0; i < n-1; i++) //外层循环,共选择n-1次 { for (int j = i + 1; j < n; j++) //内层循环,起始位置开始向后进行比较,选最小值 { ; } }
- 完整代码:
void swap(int* x, int* y) { int tmp = *x; *x = *y; *y = tmp; } void SelectSort(int* a, int n) { for (int i = 0; i < n - 1; i++) //外层循环,共选择n-1次 { int mini = i; //记录最小值的下标,初始为第一个数下标 for (int j = i + 1; j < n; j++) //内层循环,起始位置开始向后进行比较,选最小值 { if (a[mini] > a[j]) //比最小值小,交换下标 { mini = j; } } swap(&a[mini], &a[i]); //将最小值与起始位置的数据互换 } }
- 时间/空间复杂度:一共选了N-1次,每次选择需要比较N-1,N-2,N-3…次,加起来和冒泡一样时间复杂度为O(N);没有用到辅助空间,空间复杂度为O(1)
- 稳定性分析:由于是选数交换,在交换的过程中很可能会打乱相同元素的顺序,例如下面这个例子:

我们发现,在第一趟交换中,黑5被交换到了红5后面,在整个排序结束后,黑5依然在红5的后方,与最开始的顺序不一致。由此我们可以得出,选择排序是不稳定的排序。
六、各大排序算法的复杂度和稳定性
| 排序算法 | 时间复杂度(最好) | 时间复杂度(平均) | 时间复杂度(最坏) | 空间复杂度 | 稳定性 | 数据敏感度 |
| 冒泡排序 |  |
 |
 |
 |
稳定 | 强 |
| 选择排序 |  |
 |
 |
 |
不稳定 | 弱 |
| 直接插入排序 |  |
 |
 |
 |
稳定 | 强 |
| 希尔排序 |  |
  |
 |
 |
不稳定 | 强 |
| 堆排序 |  |
 |
 |
 |
不稳定 | 弱 |
| 快速排序 |  |
 |
 |
 |
不稳定 | 强 |
| 归并排序 |  |
 |
 |
 |
稳定 | 弱 |
本次的内容到这里就结束啦。希望大家阅读完可以有所收获,同时也感谢各位铁汁们的支持。文章有任何问题可以在评论区留言,小羊一定认真修改,写出更好的文章~~

