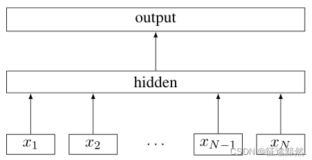
Next Sentence Prediction(NSP) 是一种用于自然语言处理 (NLP) 的预测技术。它通常用于语言模型中,目的是预测一段文本的下一个句子。NSP 可以用于许多不同的应用程序,例如机器翻译、对话系统和自动摘要。
NSP 的基本原理是使用已经训练好的语言模型来预测给定文本的下一个句子。语言模型通常使用大量的文本数据进行训练,以便学习语言的结构和模式。当给定一段文本时,NSP 模型将使用这些模式和结构来预测下一个句子。
NSP 可以应用于许多不同的场景。例如,在机器翻译中,NSP 可以用于预测目标语言中的下一个句子。在对话系统中,NSP 可以用于预测用户的下一个句子,以保持对话的流畅性。在自动摘要中,NSP 可以用于预测一篇文章的下一个句子,以生成摘要。
下面是一个简单的 NSP demo:
假设我们有一个已经训练好的语言模型,我们可以使用它来预测一段文本的下一个句子。例如,给定以下文本:
"The cat is sleeping on the bed."
我们可以使用 NSP 模型来预测下一个句子。模型可能会预测:
"The cat wakes up and walks away."
当然,这只是一个简单的例子,实际上 NSP 模型可以预测许多不同的句子,并且预测的结果会根据训练数据的质量和模型的质量而有所不同。
关于 Next Sentence Prediction (NSP) 的学习资料如下:
- "Next Sentence Prediction as a Sequence-to-Sequence Task":这是一篇比较早的论文,介绍了如何将 NSP 视为一个序列到序列的任务。该论文提出了一种新的方法,通过将 NSP 作为序列到序列任务来提高模型的性能。
- "Effective Approaches to Attention-based Neural Machine Translation":这是一篇关于基于注意力机制的神经机器翻译的论文,其中也涉及了 NSP 技术。该论文提出了一种新的方法,通过引入一种注意力机制来提高 NSP 模型的性能。
- "TensorFlow 官方文档:Transformer 模型":这是一个关于 Transformer 模型的 TensorFlow 官方文档,其中也介绍了 NSP 技术。该文档提供了一个使用 TensorFlow 实现 NSP 模型的示例,以及有关 Transformer 模型的详细信息。
- "Deep Learning for Text (Part 1): Sequence-to-Sequence Learning":这是一个由 deeplearning.ai 制作的关于深度学习文本处理的演讲视频,其中也涉及了 NSP 技术。该视频提供了一个关于 NSP 技术的概述,以及一些有关深度学习文本处理的实用信息。

![[GloVe]论文实现:GloVe: Global Vectors for Word Representation*](https://ucc.alicdn.com/pic/developer-ecology/w2a72w4omzoyy_c4f51f904bca49c386ed332289102e05.jpg?x-oss-process=image/resize,h_160,m_lfit)
![[Dict2vec]论文实现:Dict2vec : Learning Word Embeddings using Lexical Dictionaries](https://ucc.alicdn.com/pic/developer-ecology/w2a72w4omzoyy_dd2ab61f79e7475f89364949cfee15c6.png?x-oss-process=image/resize,h_160,m_lfit)