

引言
6月1日的广州港珠澳云峰会,我们发布了工业组态智能版(工业生产管控可视化引擎),通过将工业传统组态软件(工业组态应用开发&工业生产可视化软件)结合强大的大型语言模型能力(LLM),通过AI人工智慧助手Copilot的方式重塑应用开发新交互,释放用户创造力,突破知识边界,降低产品门槛,提高生产力等,另一方面,未来所有的产品都会基于LLM有一轮智能化的升级,对比业界组态软件WINCC、InTouch等竞品,结合大模型让产品更有竞争力。



我们用了2个月的时间完成了工业组态智能版的产品设计与技术研发,结合大模型,对原有工业组态智能版(工业生产管控可视化引擎) 做智能化升级,结合大模型让产品有了工业知识问答、工业应用生成、智能辅助绘图、智能属性修改、组态代码生成、素材生成等功能。

智能效果展示如下:
01:工业知识问答:
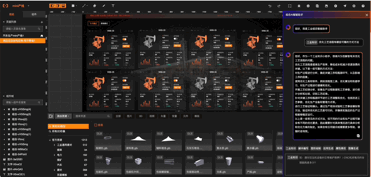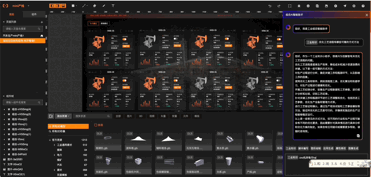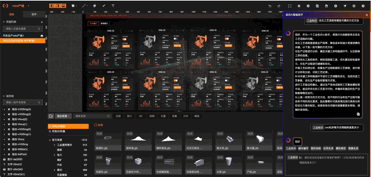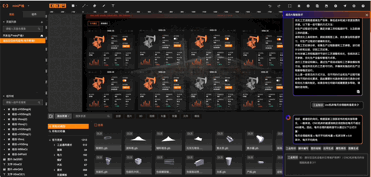
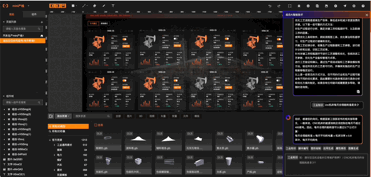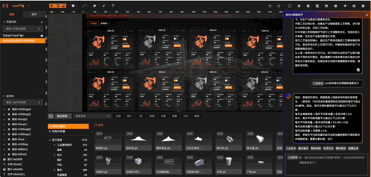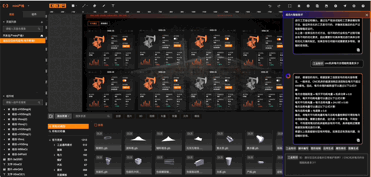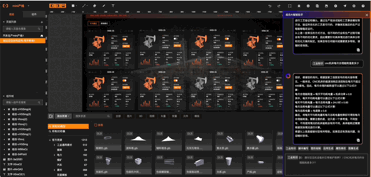
02:工业组态应用生成
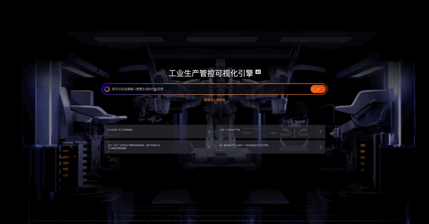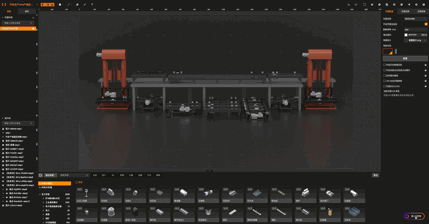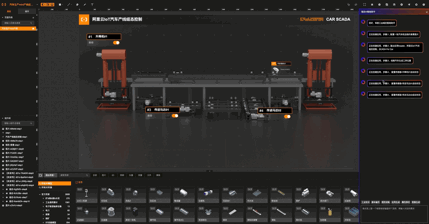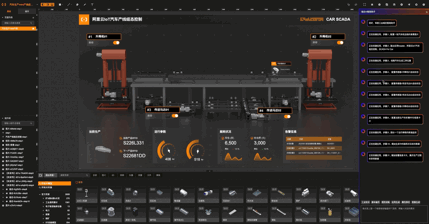
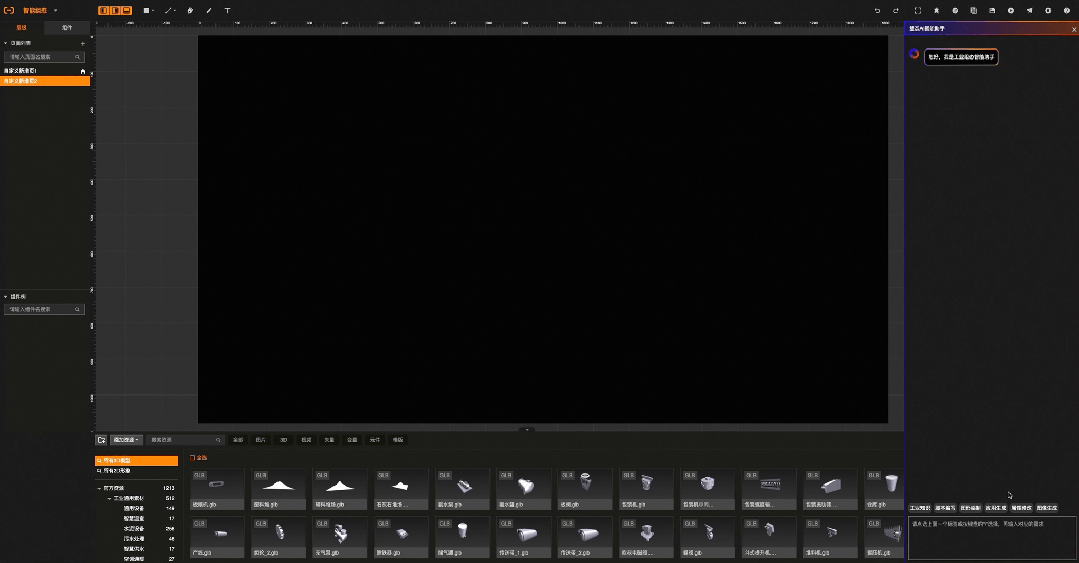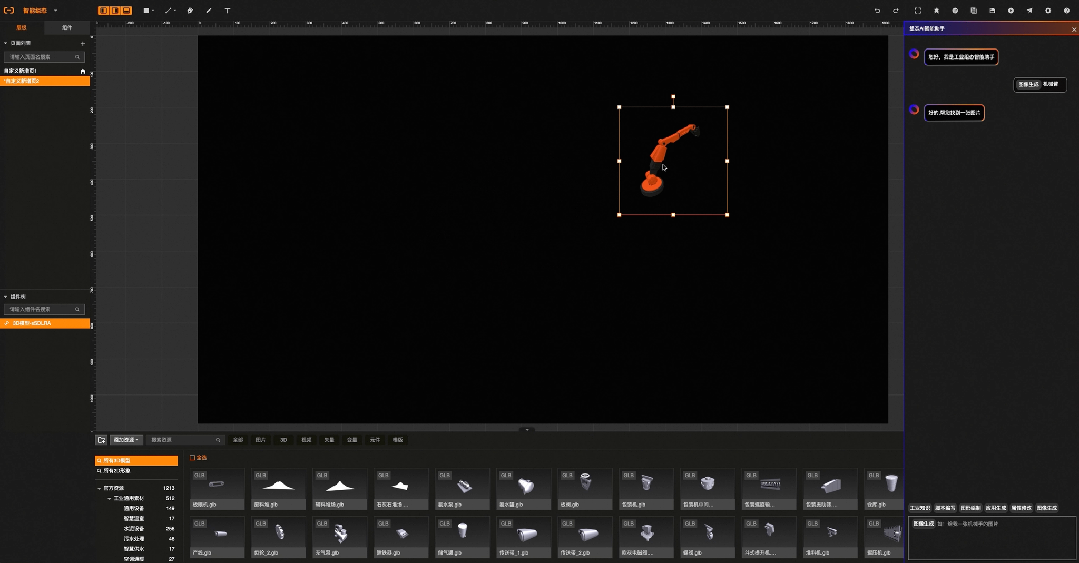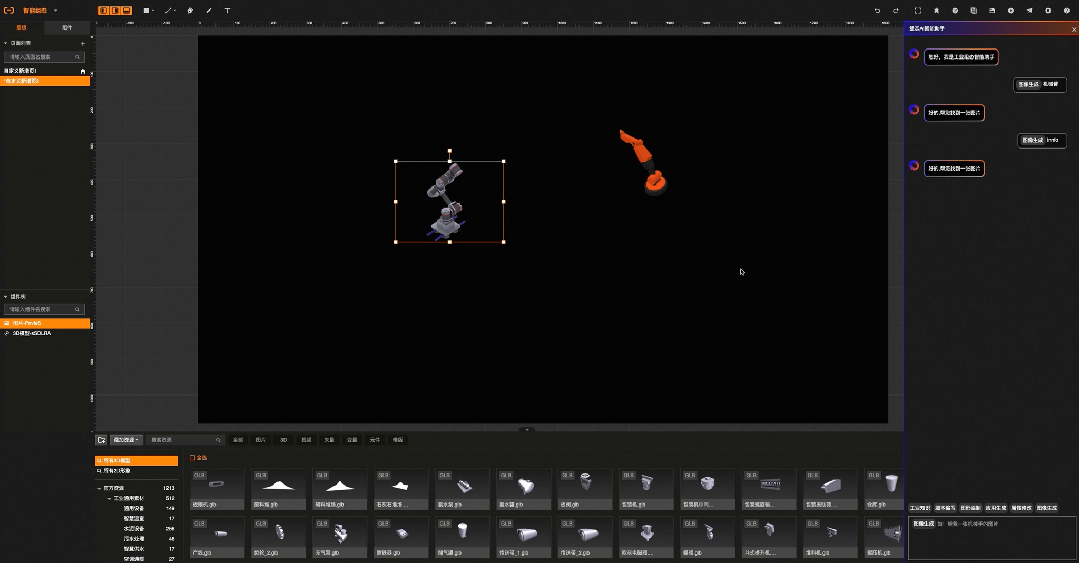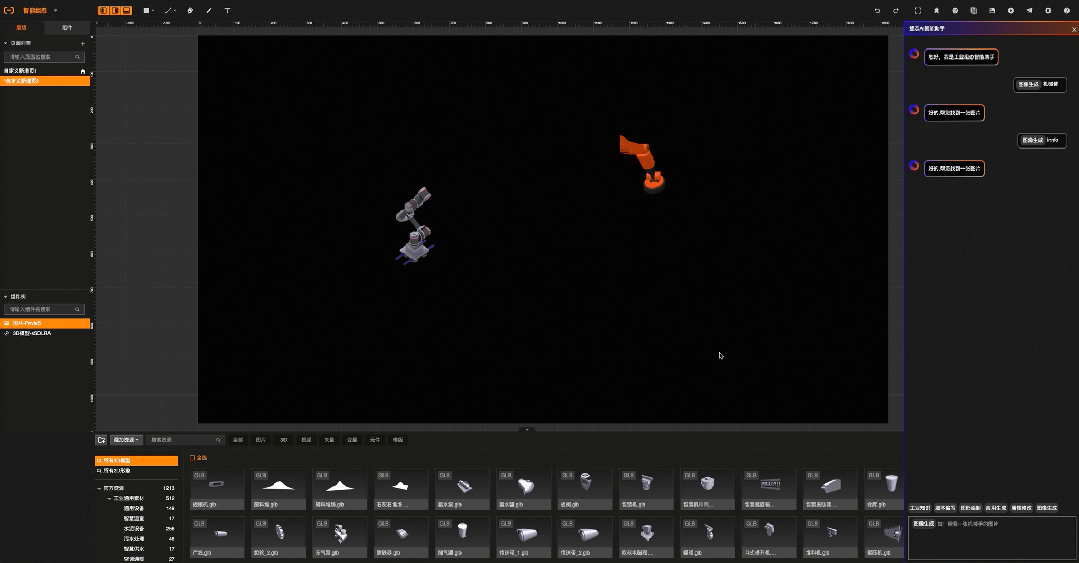
03:智能绘图:基础图形绘制
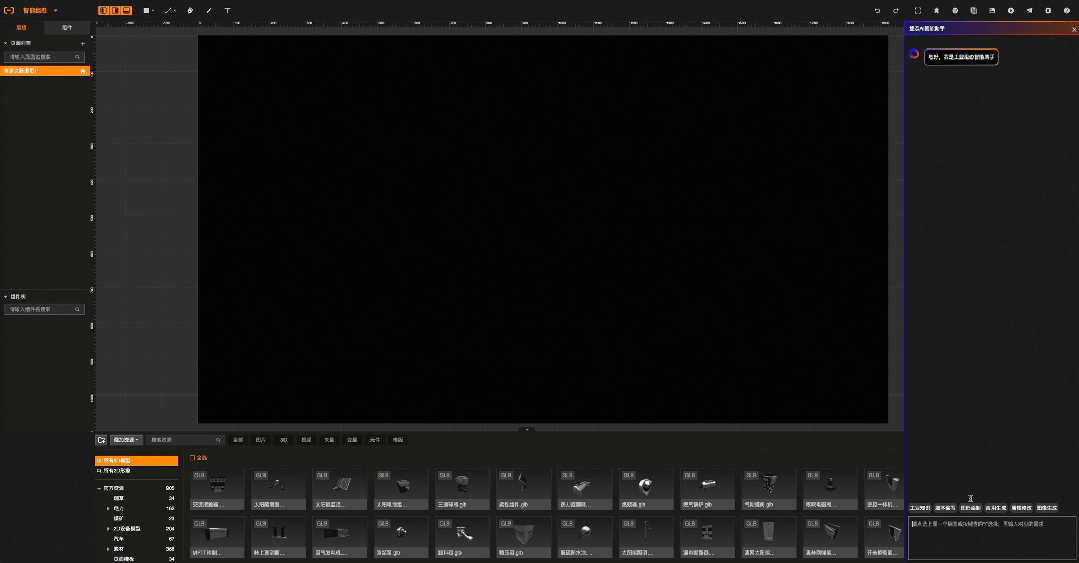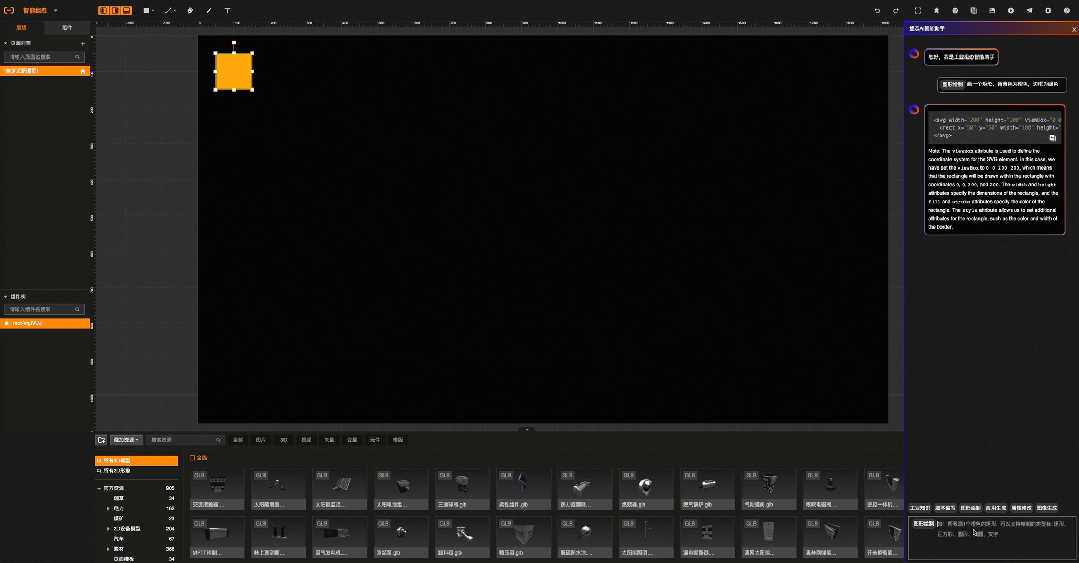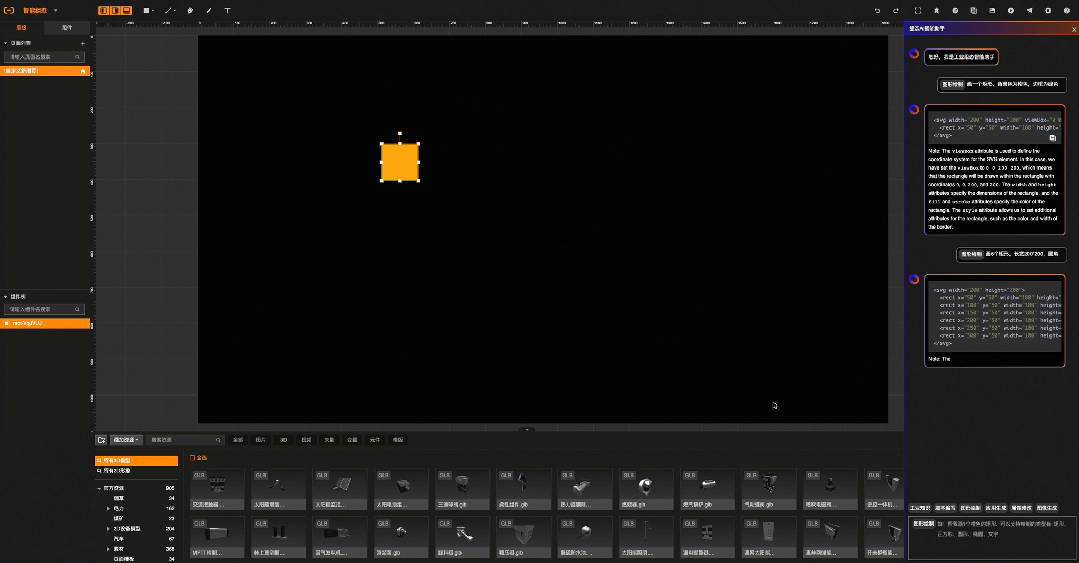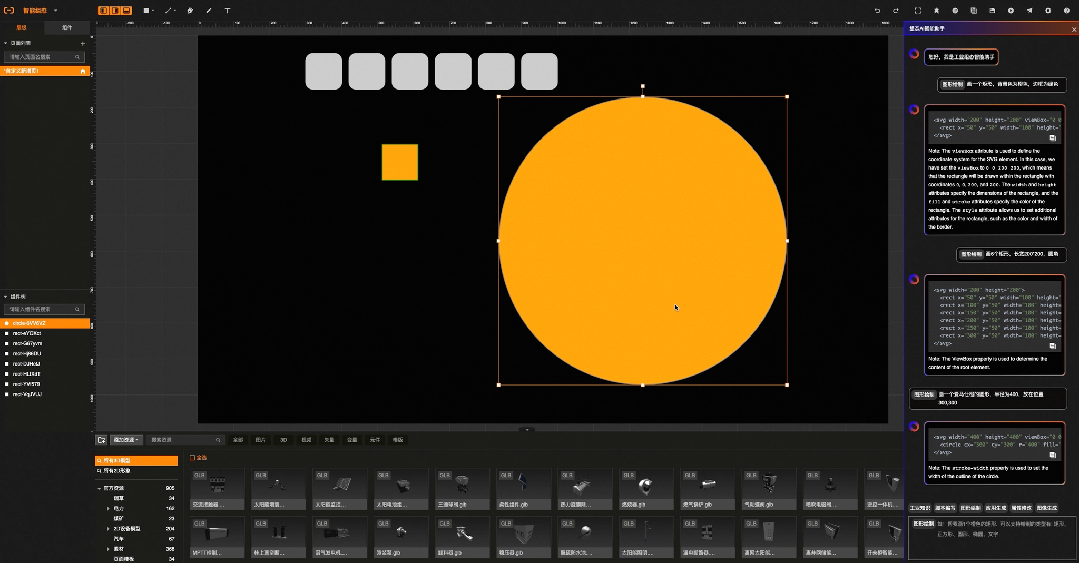
智能绘图:属性修改
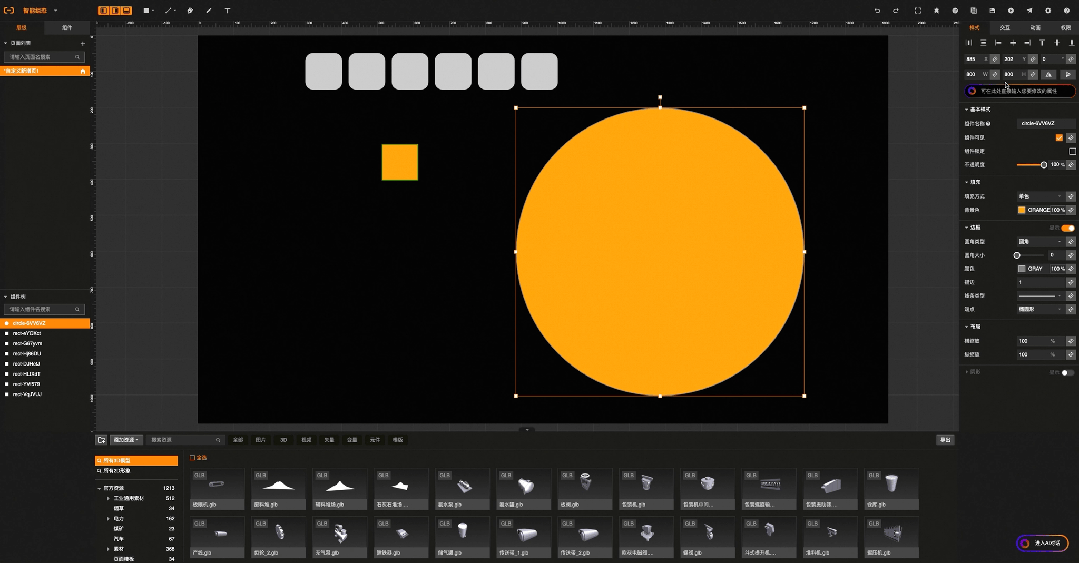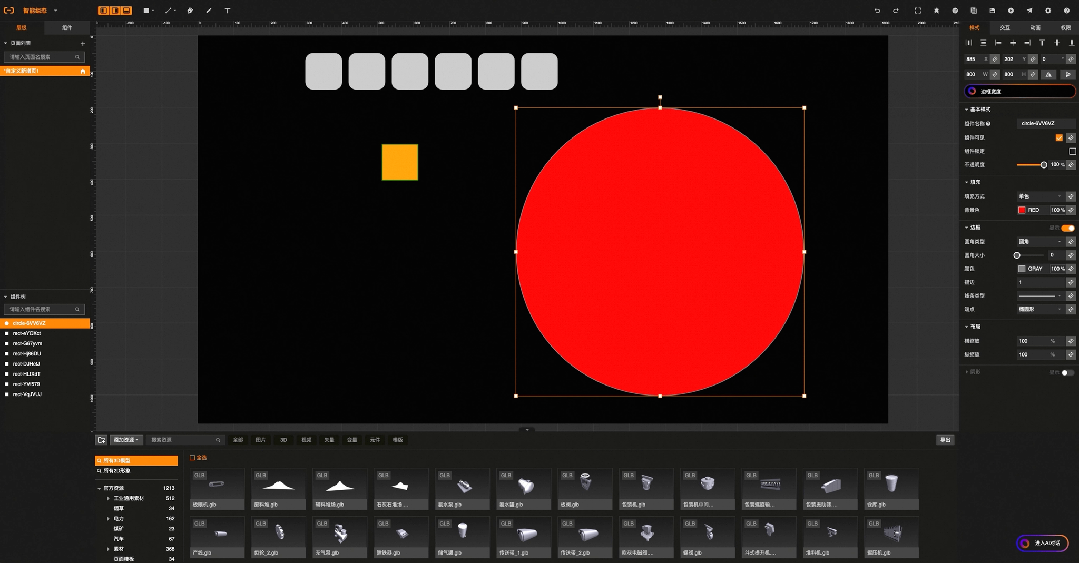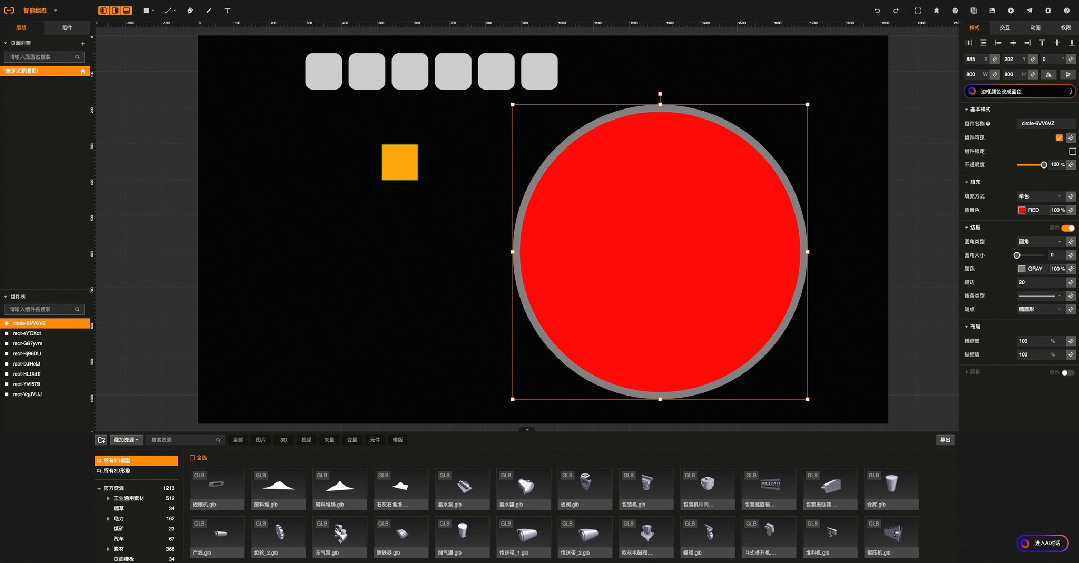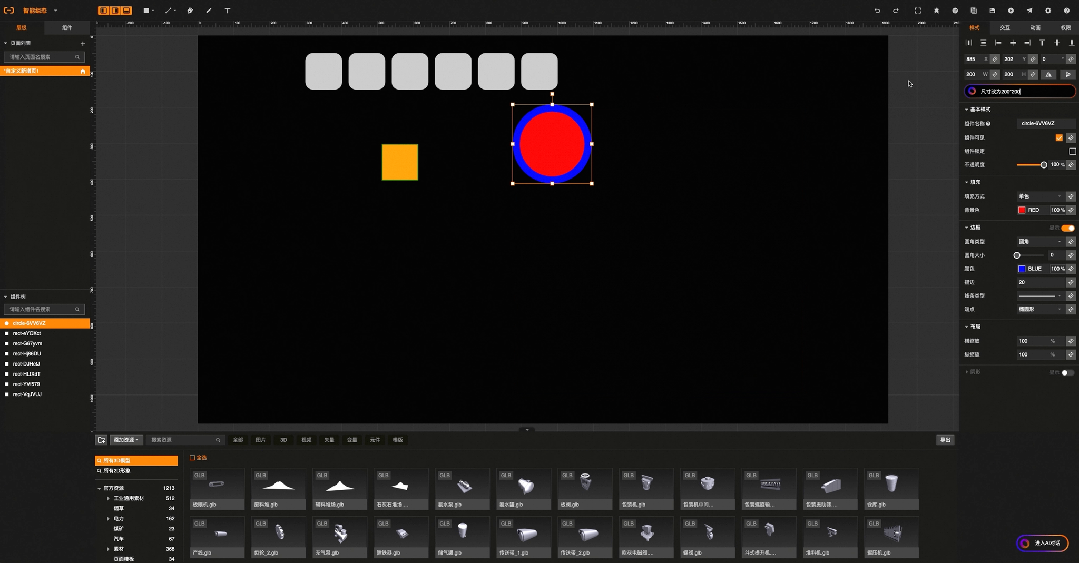
04:智能脚本生成
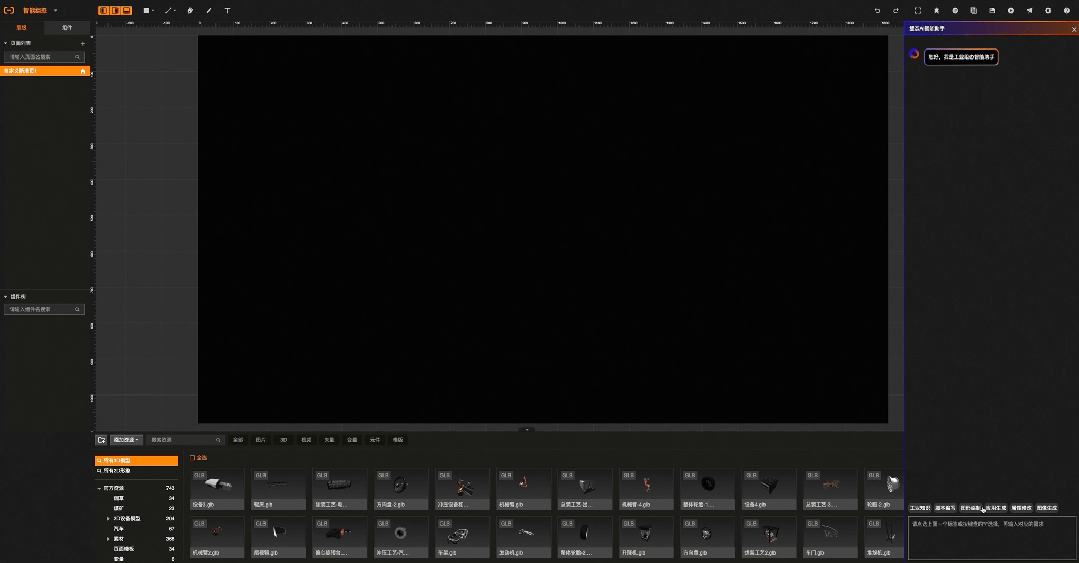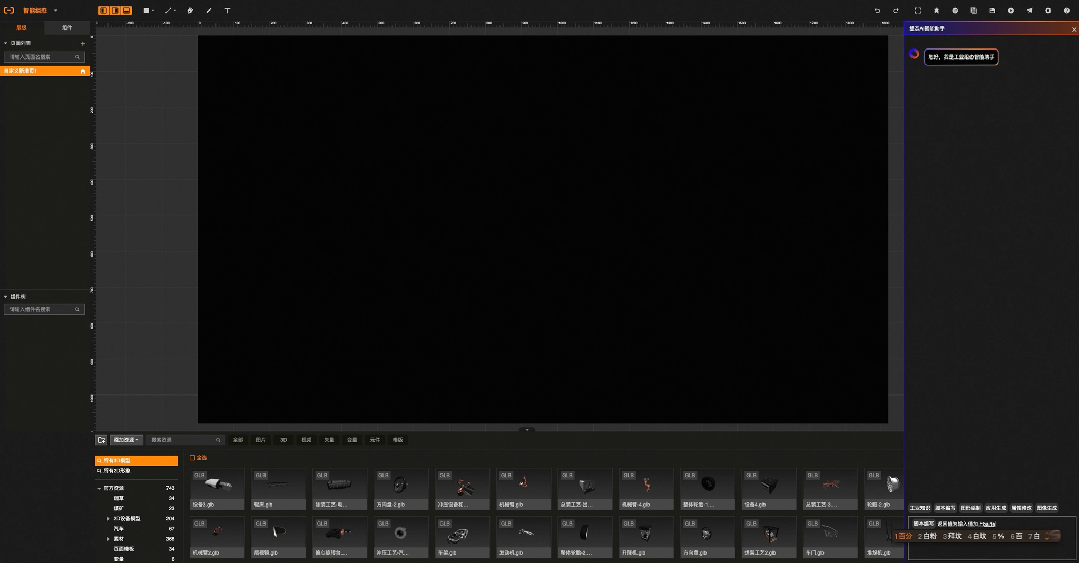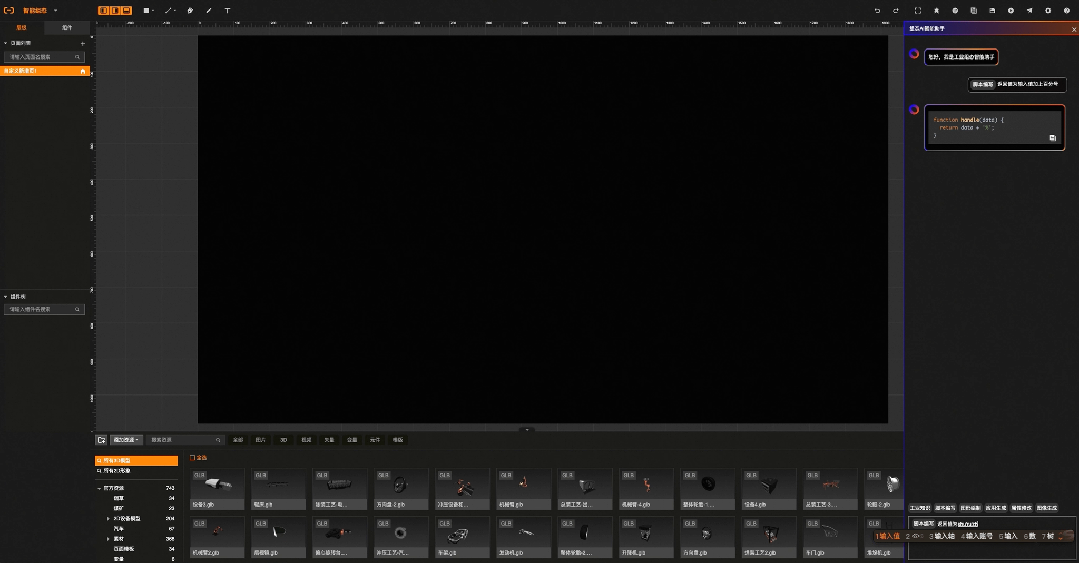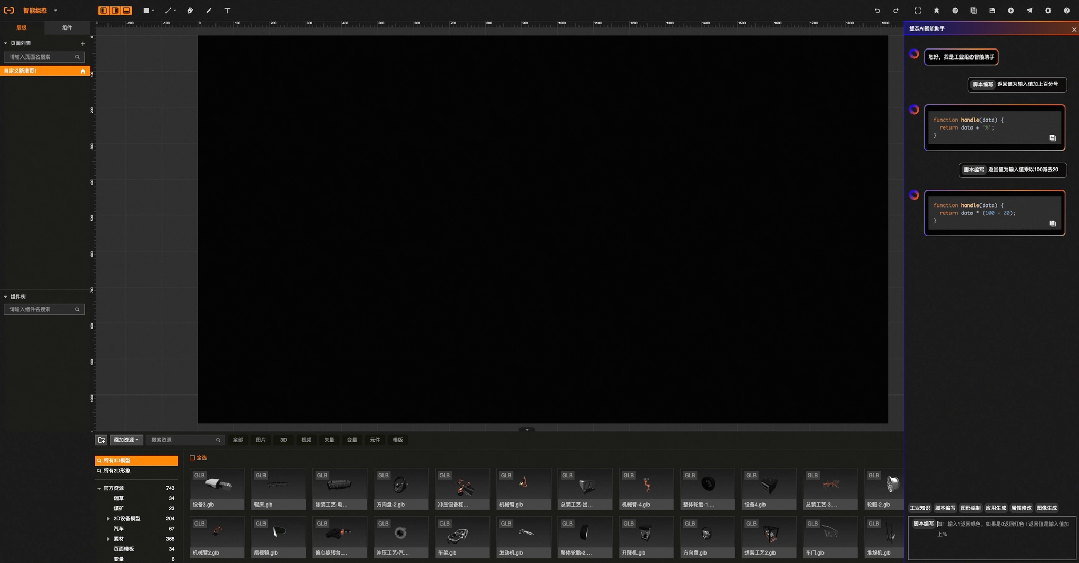
05:智能素材生成
这篇文章想分享下:
- 工业软件产品与大模型结合创新的思考
- 工业组态智能版的技术架构与实现
- 基于LLM开发的一些建议
对于不同背景的同学可以选择阅读。本文涉及到的内容也比较多,并非都能介绍清楚,大家有关系的问题可以留言,我后续再进行补充。
问了方便大家阅读,也简单减少下工业组态软件(工业生产管控可视化引擎) 的背景
工业组态用于解决工业生产过程的数据呈现、过程管理、设备控制与运维的应用。系统分为编辑器和应用运行时。
通过编辑器实现一个工业组态应用有3步:
- 定义数据点:数据点位的数据源来源于OT数据和IT数据。OT数据通过数据采集平台,读取PLC驱动数据得到,IT数据通过组态系统定义的数据驱动(数据库、api接口、mqtt\kafuka\nats消息)获取
- 可视化应用开发:通过低代码引擎搭建现场画面,并绑定数据点
- 发布和托管应用:传统的工业组态是基于CS架构,我们的软件基于BS浏览器架构,通过WEB应用渲染第二部生产的DLS,包括画面和数据部分,从而形成完成的工业应用。
产品界面

工业组态应用案例:工艺流程、生产过程管理、设备运维、andon应用、仓储库存、机运管理、能耗管理、数字孪生、生产大屏等组态应用。

工业组态软件智能版如何与大模型结合
大模型是统一模态(跨模态、视觉、语言等模态)和任务(如图片生成、视觉定位、图片描述、图片分类、文本生成等),通过大模型我们可以用自然语言快速获取信息,加工文本,另外也降低了AI技术使用门槛。
在工业组态场景中,借助大模型的能力,实现工业组态智能化升级,主要考虑这4个方面:
- 使用LLM,突破工业信息边界,给用户有更专业的工业信息与知识的补充。
- 使用LLM重构传统工业组态应用基于搭建的开发过程
- 使用LLM降低专业工业软件对使用者的基本要求,降低使用者门槛
- 使用LLM的语言模型能力,降低natural language processing研发门槛和成本,改善产品交互体验
使用LLM,突破工业信息边界,给用户有更专业的工业信息与知识的补充
大模型最先想到的场景是Chat。在工业场景可以用于获取通用的工业生产、运维、安全、制造等信息,也可以通过私有数据做到更专业、更私域的知识获取。
通用的工业知识:工业知识,大模型在训练初期收录了大量干净、人工标注的数据,这类数据也包含了非常多工业领域的通用知识,如关于工业生产、运维、能耗相关的通用问题,这类知识对工业从业人员仍然非常有用处,我接触的很多工厂与制造从业人员对通用知识也并非都知道的,工业行业跨度很大,从业人员只了解自己工厂生产的产品、设备、过程相关知识。同行业其他工厂的知识,跨行业的通用知识对他们帮助也很大。
专业经验知识:针对特定领域的知识,更专业的知识可能存在于某些工业手册,会议纪要,操作指南,设备运维手册,甚至只存在工厂个别专家的脑袋中。如果这类知识可以通过大模型进行记录,并且通过自然语言进行获取,对工业帮助特别特别大。接触到一个制造企业工厂,是我们的客户,工厂数字化系统是使用我们的工业产品落地的,在与设备运维负责人沟通交流中,拿到了该工厂近五年所有设备故障复盘总结日志,包括问题、原因、解决方案的文本与图片记录。通过专属大模型,建立企业专属工业知识库,通过自然语言进行交互,对比传统方式有很多好处:
- 专家永远24小时在线,解决任何问题。一线工人在设备遇到故障时候,可以快速找到解决故障的问题和方法。
- 没有语言障碍:大模型是支持多语言的,所以无论什么语言的工业知识,都可以作为沉淀,也都可以交流。输入的说明书是英文的,这在工业设备手册场景是很常见的,但运维人员可以通过中文对话,获得需要的中文信息。
- 自定义提问的姿势。用使用者的视角,按照个性化的姿势进行提问,根据回答内容不断追问,直到完全理解为止
- 大模型没有容量限制,而专家的脑袋是有限制的。
- 信息获取效率高。大量的手册、知识、经验中找到自己需求的信息是很费时的操作,但使用LLM,速度总是很快很快。
使用LLM重构传统工业组态应用基于搭建的开发过程
工业组态类应用开发有2个阶段,阶段1:在1985年之前,所有的组态应用都是定制化开发的,应用开发成本高,效率低。阶段2:工业场景中 生产过程、状态监控、设备控制、安全告警、这类应用相似度很高,因此1985年之后出现了工业类似低代码的软件系统,叫组态,英文名configuration,意思是通过配置的方式,将状态点和控制点通过工业PLC和各种取得采集,与画面UI绑定。

基于LLM,工业组态应用开发可以做到免开发与配置,通过用户诉求直接生成应用,而组态编辑器只作为做应用微调、修正、个性化修改的工具。这个观点其实对任何低代码产品都适用。低代码产品往往都会面临一个问题“用户是谁”,服务客户、还是客户的员工、还是软件服务商?不同用户有着完全不同的诉求和商业策略。客户需要的是能用的应用,而不是生产力工具。所以低代码产品最终演变成一个工具产品,客户会算账到底能不能省钱,但这笔账是没法算清的,原因是系统的灵活性到底该值多少钱是算不清的。
所以如果能基于LLM做到完全免代码开发,用户提出需求,生产应用,在提出修改建议,再修正应用,基于LLM把应用开发系统变成一个应用生成系统,编辑器成为了一个修改和优化的角色,这才是接下来的低代码、无代码平台的发展趋势。
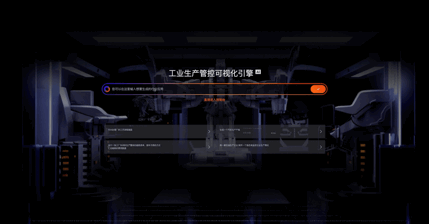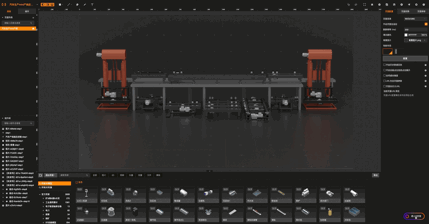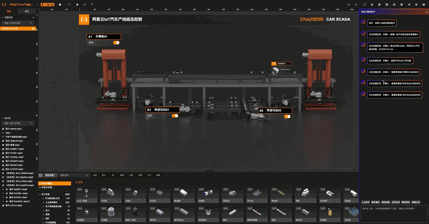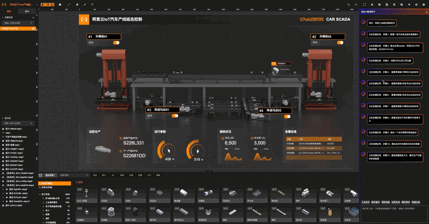
我们在产品中目前仅仅实现了一小步部分,用场景模板做关联匹配与逐步渲染,并提供自然语言指令做图形绘制、属性修改等功能,但还未实现全量的元件、组件、素材属性修改与绘制。已完成和未完成的功能见下图。

使用LLM降低工业用户作为专业工业软件使用者的门槛
工业软件的使用者为工厂的工人、工业自动化专业的工程师、工业工程管理与运维人员。在工业组态场景中,代码编写的门槛就很高,大部分设备工程师并不会写代码,哪怕是最简单的代码,都有语言、环境、语法等一堆问题需要解决。
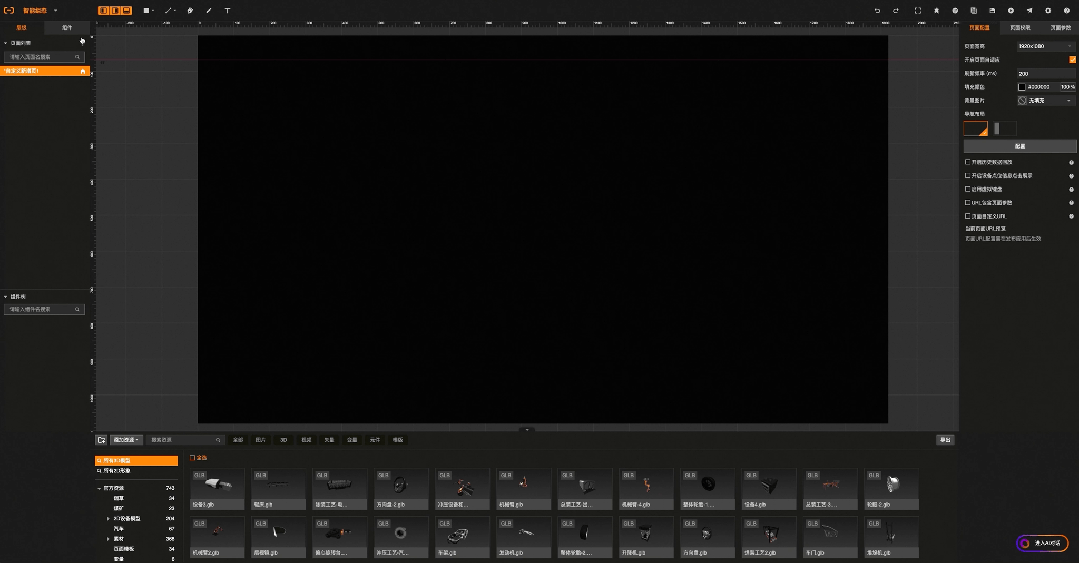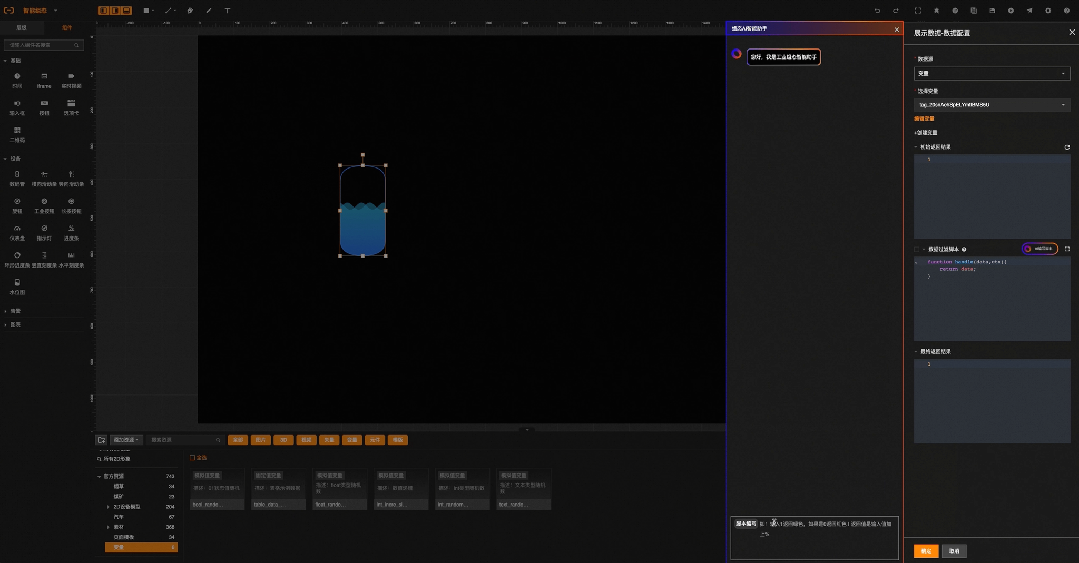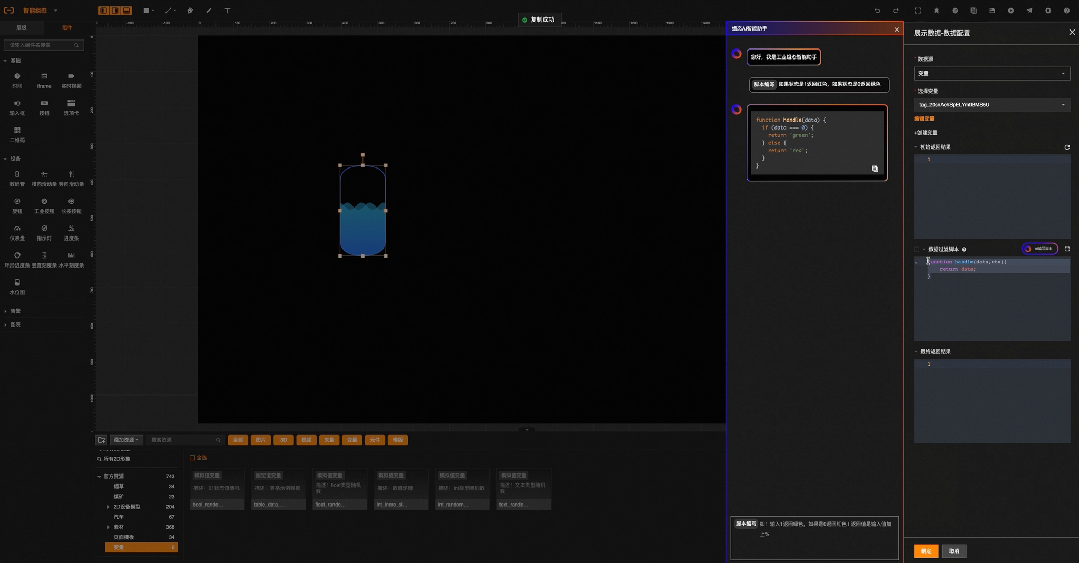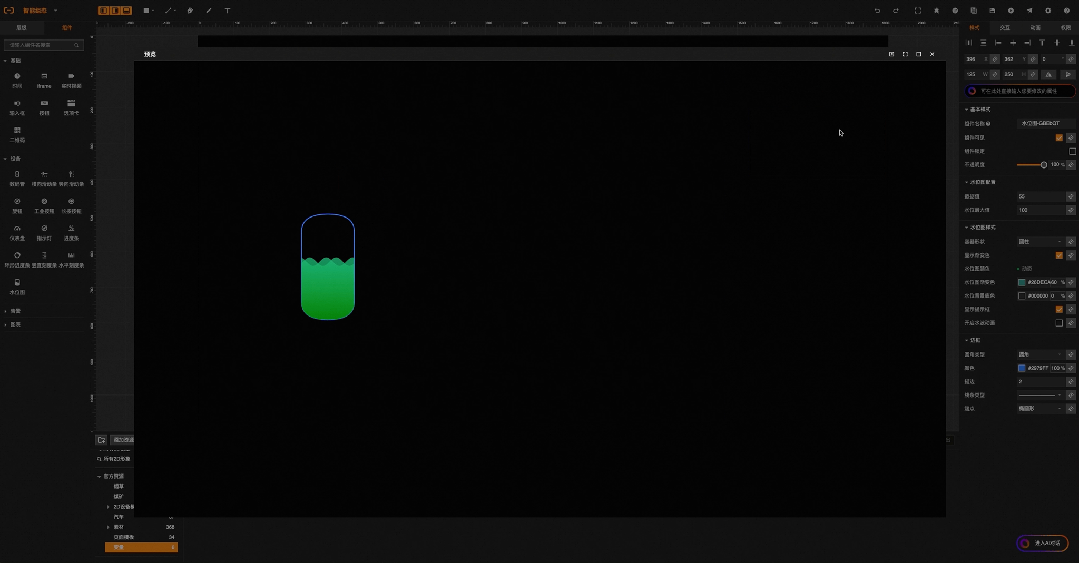
举个例子: 工业生成现场采集到的数据往往是最原始的状态,如工位安全生产状态位数据是0,1,2,代表着工位生产状态是 正常、告警、故障三种。在组态应用中需要用这三种颜色来表示生产状况的视觉卡片,如下图所示。

这时候就需要用户具备编写脚本的能力,通过代码把数值转换成对应的颜色。这个过程难倒了大部分的工业从业者,因此企业不得不寻求软件服务商参与,那么数字化的成本和效率都有几十倍的损耗。假如可以用自然语言就能完成代码编写,那极大程度降低了专业软件的使用门槛。



我们验证了在工业组态场景经常需要编写脚本的类型(状态位和UI元素转换,数值计算,单位处理等),通过大模型都能很好的解决。
基于LLM的语言模型能力,降低natural language processing研发门槛和成本,改善产品交互体验。
第四点是所有产品与技术都可以通用的,使用自然语言指令,实现产品原来就有的功能,改善产品交互体验。
比如工业组态智能版中,原本需要通过鼠标一个个绘制的图形,现在只需要输入语言指令:“帮我画10个灰色圆角的方形,长宽200*200”就可以实现, 原本需要再右侧一大堆属性配置选项中找到背景色,在通过颜色选择器完成的背景色配置,现在只需要输入语言指令:“帮我把背景色修改成红色”。
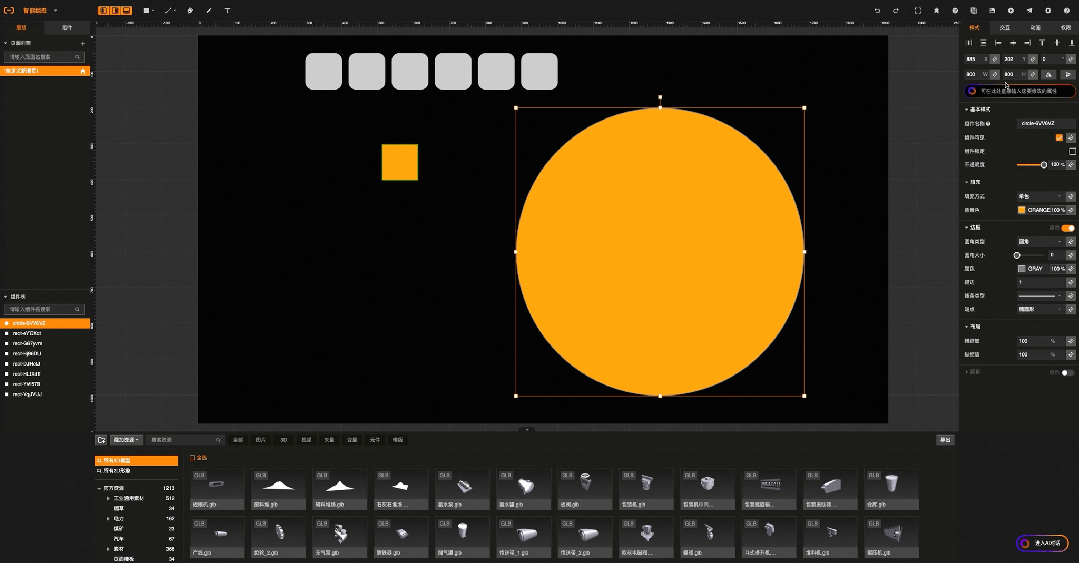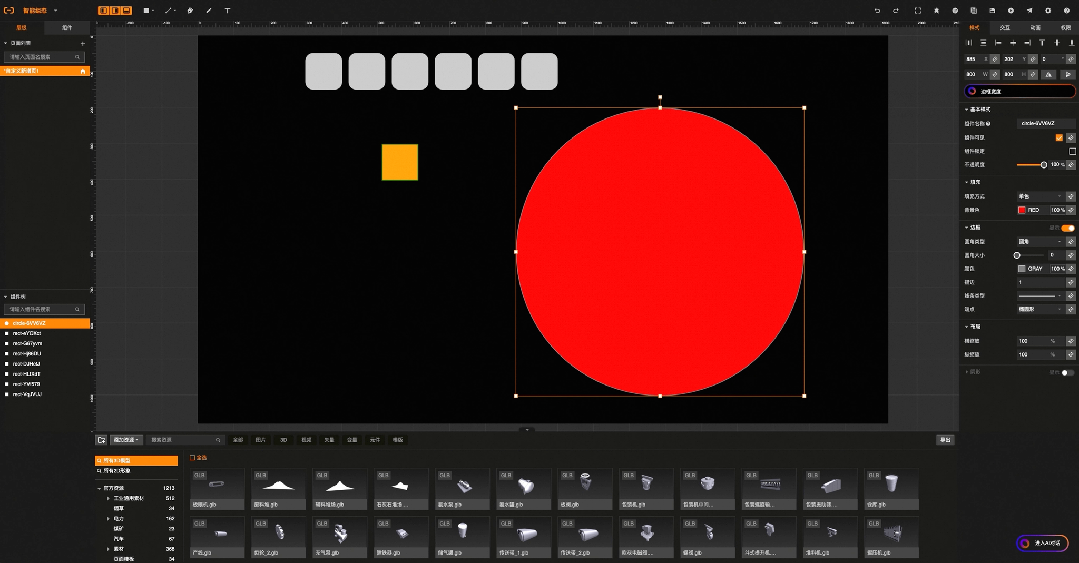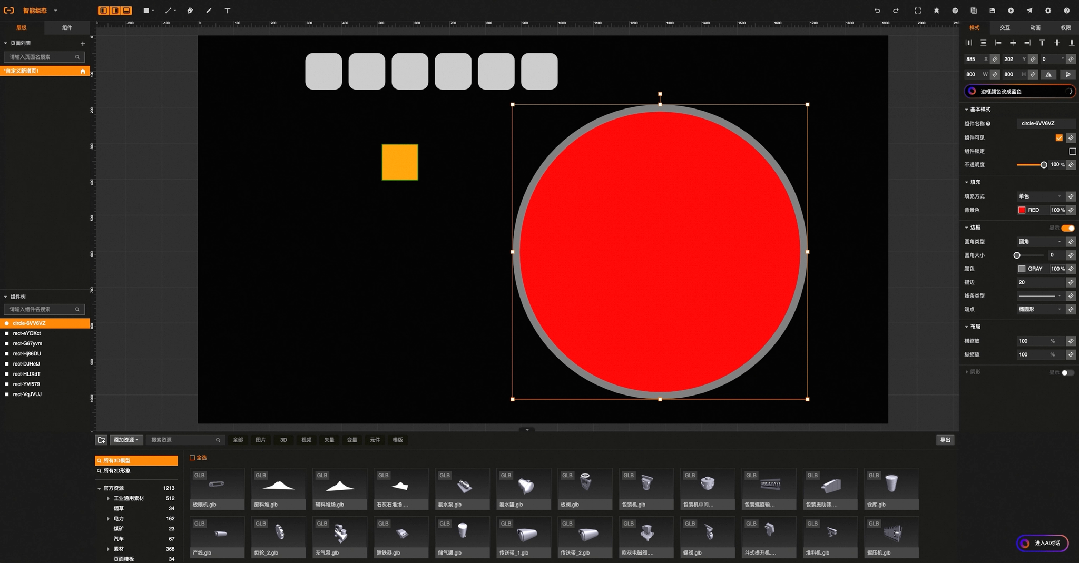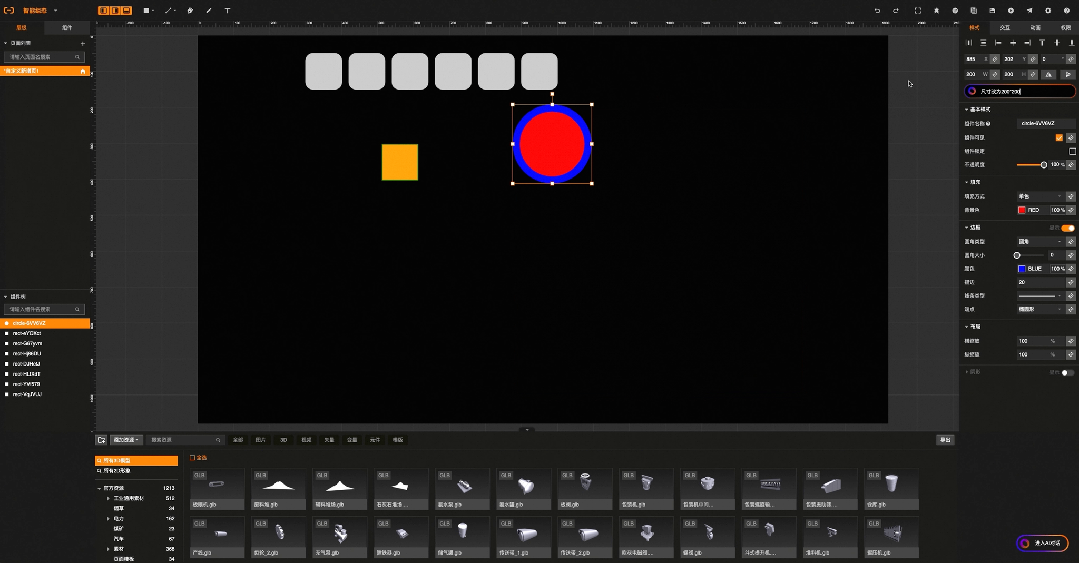
而大模型提供的能量就是极大简化了natural language processing 应用研发门槛和成本.,如果不依赖大模型,一般会有2种方式 1)自己训练模型,需要准备大量的指令和训练数据,做监督学习,模型调优,模型部署与剪裁 2)使用成熟的NLP框架,如Spacy,需要详细的词法分析的工程化工作,且效果并不好,出错率也高,并且需要针对每一条语音指令做规则处理。使用Spacy实现语言指令大致过程如下 :
importspacynlp=spacy.load("zh_core_web_lg") text="把背景颜色改为红色"doc=nlp(text)
这段代码中doc是一个语言文档,包含一个数字,里面给出这句话每个词及词的词性,比如动词、介词宾语、主语、助动词、量词、副词...等。其中包含一个root节点作为语句的起始。无论使用哪一种,成本和门槛都很高。
基于大模型实现语言指令就很简单,你所要做的就是会使用Prompt就够了,研究下Prompt工程,合理的设定问题和问题反馈的格式就可以做到。我实现这段功能的prompt也比较简单,如下所示。prompt定义了问题,输入、返回格式、小样本案例、异常处理示例。通过这个Prompt,输入 " 帮我把字体大小改成12" ,就可以得到{ "fontSize":"12"},接下来就简单了,在工业组态应用程序中修改对应ComponentID的Props值就完成了功能。这部分在技术实现中我在详细去解释。
defprops_prompt(input): example='''example: 输入示例1:帮我把字体大小改成12输出示例1:{ "fontSize":"12"} 输入示例2:帮我把名称改成组件001,边框颜色改成红色输出示例2:{ "name":"组件001" , "borderC":"red"} 输入示例3:请将透明度修改为0.5,位置修改为x:100,y:200输出示例3:{ "opacity":0.5 , "x":100, "y":200} 输入示例4:背景颜色改为黄色输出示例4:{"bgColor":"yellow"} '''ret=f'''一个组件有如下属性。key表示属性英文名称,value表示属性中文名称,如果一个key对应多个多个中文名称,用|分割"name": "组件名称", "content": "文字内容|文字|内容", "w": "宽度 长度", "h": "高度", "x": "x位置", "y": "y位置", "z": "z位置", "borderW":"边框大小 | 边框粗细", "borderW":"边框", "visible": "显示 true|隐藏 false", "opacity": "透明度", "borderC": "边框颜色", "bgColor": "背景颜色", "color": "文字颜色", "fontSize": "字体大小 | 文字大小", "textAlign": "文字水平对齐方式", //左对齐left 居中对齐middle 右对齐right"verticalAlign": "文字垂直对齐方式", //上对齐top 居中对齐middle 下对齐bottom接下来我会输入一句话,用来修改组件对应属性的值返回结果格式为json,对应内容是 {{ "英文key": "修改的数值" }} 请不要返回除了json以外的其他任何内容用户输入内容为:{input} 给你一些参考示例: {example} 异常处理: 如果用户想要修改的属性不再列表中,请返回: {{ "error": "支持修改的属性包括:文字内容,长度、宽度、边框大小、边框颜色、透明的、隐藏、显示、文字颜色、文字内容、字体大小" }} '''returnret
另外一个案例就是图片生成和图片搜索,我们提供了1000多个工业常用领域的素材库,通过自然语言区实现图片搜索,会比搜索框更高效。


组态智能版中的自然语言素材生成是搜索 + text2img的能力。使用了阿里云的Imageenhan服务。但目前市面上的text2img服务,无论是Imageenhan、stable diffusion、midjourney 对与工业场景的素材生成效果差强人意,所以组态产品还是优先在工业素材库中进行2D3D素材匹配。

小结:目前基于LLM已经做到的功能,和接下来可以继续探索部分
黄色:已经实现
灰色:未来规划

更多精彩内容,欢迎观看:
工业组态 + LLM : 大模型技术引领传统工业软件创新与实践(下)


