1 架构演进遇到的痛点
1.1 分表分库痛点
主流架构一般分库分表都会涉及,追求性能的同时,带来各种痛点
分库分表并不是一门创新技术,它只是由于数据体系结构的限制而做的无奈之举
机器配置无法无限上升,成本飙升,迫不得已衍生的方案
也就是说分库分表会遇到很多问题举一下一个例子就是id问题的一个解决
2. 分布式订单生成策略
springboot下,基于sharding-jdbc的框架简介。
分表下的订单表案例介绍,userid维度(分库雷同)
启动与调试,按userid验证数据落库,再查询
重点:分布式id的生成策略
2.1 自增
2.1.1 问题背景
1)业务代码
@GetMapping("/incadd") public Incorder add(int userid){ Incorder incorder = new Incorder(); incorder.setUserid(userid); mapper.insert(incorder); return incorder; }
2)运行结果


3)分析
单表下自增功能不会造成数据错乱,数据库自身特性保障了主键的安全
会泄露id规律,数据隔离做不好的话,不法分子可能会循环撞库窃取订单数据
自增是表维度,一旦拆表,多个自增,有序性被打破
2.1.2 起始点分段
1)方案
设置表2的起始点,再来跑试试……
#用以下sql,或者客户端工具设置: ALTER TABLE incorder_1 AUTO_INCREMENT=10;
2)优缺点
简单容易,数据库层面设置,代码是不需要动的
边界的切分人为维护,操作复杂,触发器自动维护可以实现但在高并发下不推荐
2.1.3 分段步长自增
1)方案
‐‐查看 show session variables like 'auto_inc%'; show global variables like 'auto_inc%'; ‐‐设定自增步长 set session auto_increment_increment=2; ‐‐设置起始值 set session auto_increment_offset=1; ‐‐全局的 set global auto_increment_increment=2; set global auto_increment_offset=1;
3)问题
影响范围不可控,要么session每次设置,忘记会出乱子。要么全局设置,影响全库所有表
结论:不可取!!!
2.2 业务规则
2.2.1 方案思想
不用自增,自定义id,加上业务属性,从业务细分角度对并发性降维。例如淘宝,在订单号中加入用户id。
加上用户id后,并发性维度降低到单个用户,每个用户的下单速度变的可控。
时间戳+userid,业务角度,一个正常用户不可能1毫秒内下两个单子,即便有说明是刻意刷单,应该被前端限流。
2.2.2.实现
@GetMapping("/busiadd") public Strorder busiadd(int userid){ Strorder order = new Strorder(); order.setId(System.currentTimeMillis()+"‐"+userid); order.setUserid(userid); strorderMapper.save(order); return order; }
2.3 集中式分配
2.3.1 MaxId表
1)通过一张max表集中分配
CREATE TABLE `maxid` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `name` varchar(50) DEFAULT NULL, `nextid` bigint(20) DEFAULT NULL, PRIMARY KEY (`id`) ); insert into maxid(name,nextid) values ('orders',1000);
2)创建函数
DROP FUNCTION getid; ‐‐ 创建函数 CREATE FUNCTION getid(table_name VARCHAR(50)) RETURNS BIGINT(20) BEGIN ‐‐ 定义变量 DECLARE id BIGINT(20); ‐‐ 给定义的变量赋值 update maxid set nextid=nextid+1 where name = table_name; SELECT nextid INTO id FROM maxid WHERE name = table_name; ‐‐ 返回函数处理结果 RETURN id; END
3)StrorderMapper调整id策略,借助mybatis的SelectKey生成id,注意Before=true
@Insert({ "insert into strorder (id,userid)", "values (#{id},#{userid,jdbcType=INTEGER})" }) @SelectKey(statement="SELECT getid('orders') from dual", keyProperty="id", before=true, resultType=String.class) int getIdSave(Strorder record);
/** * maxid表验证 */ @GetMapping("/maxId") public Strorder maxId(int userid){ Strorder order = new Strorder(); order.setUserid(userid); strorderMapper.getIdSave(order); return order; }
4)启动验证分表的id情况,maxid表的记录情况。
5)优缺点
不需要借助任何中间件,数据库内部解决
表性能问题感人,下单业务如果事务过长,会造成锁等待
2.3.2 分布式缓存
通过redis的inc原子属性来实现
1)配置redis服务器
# Redis服务器地址 spring.redis.host=127.0.0.1 # Redis服务器连接端口 spring.redis.port=6379
2)使用redis主键
@GetMapping("/redisId") public Strorder redisId(int userid){ Strorder order = new Strorder(); order.setId(template.opsForValue().increment("next_order_id").toString()); order.setUserid(userid); strorderMapper.save(order); return order; }
3)优缺点
需要额外的中间件redis
与db相比不够直观,不方便查看当前增长的id值,需要额外连接redis服务器读取
性能不是问题,redis得到业界验证和认可
对redis集群的可靠性要求很高,禁止出现故障,否则全部入库被阻断
数据一致性需要注意,尽管redis有持久策略,down机恢复时需要确认和当前库中最大id的一致性
2.4 uuid
2.4.1 代码生成
1)业务代码
@GetMapping("/uuid") public Strorder uuid(int userid){ Strorder order = new Strorder(); order.setId(UUID.randomUUID().toString()); order.setUserid(userid); strorderMapper.save(order); return order; }
2)启动,数据库验证save结果
2.4.2 优缺点
最简单的方案,数据迁移方便
缺点也是非常明显的,太过冗长,非常的不友好,可读性极差
需要使用字符串存储,占用大量存储空间
在建立索引和基于索引进行查询时性能不如数字
2.5 雪花算法
2.5.1 概论

UUID 能保证保证时空唯一,但是过长且是字符,雪花算法由Twitter发明,是一串数字。
Snowflake是一种约定,它把时间戳、工作组 ID、工作机器 ID、自增序列号组合在一起,生成一个 64bits 的整数ID,能够使用 (2^41)/(1000606024365) = 69.7 年,每台机器每毫秒理论最多生成 2^12 个 ID
1 bit:固定为0二进制里第一个bit如果是 1,表示负数,但是我们生成的 id都是正数,所以第一个 bit 统一都是 0。41 bit:时间戳,单位毫秒41 bit 可以表示的数字多达 2^41 - 1,也就是可以标识 2 ^ 41 - 1 个毫秒值。
注意!这个时间不是绝对时间戳,而是相对值,所以需要定义一个系统开始上线的起始时间
10 bit:哪台机器产生的代表的是这个服务最多可以部署在 2^10 台机器上,也就是 1024 台机器。
官方定义,前5 个 bit 代表机房 id,后5 个 bit 代表机器 id。这10位是机器维度,可以根据公司的实际情况自由定制。
12 bit:自增序列同1毫秒内,同一机器,可以产生2 ^ 12 - 1 = 4096个不同的 id。
优缺点:
不依赖第三方介质例如 Redis、数据库,本地程序生成分布式自增 ID
只能保证在工作组中的机器生成的 ID 唯一,不同组下可能会重复
时间回拨后,生成的 ID 就会重复,所以需要保持时间是网络同步的。
2.5.2 实现
1)自己用java代码实现
工具类:
package com.itheima.sharding.config; import org.apache.commons.lang3.StringUtils; import org.springframework.beans.factory.annotation.Value; import org.springframework.stereotype.Component; @Component public class Snowflake { /** 序列的掩码,12个1,也就是(0B111111111111=0xFFF=4095) */ private static final long SEQUENCE_MASK = 0xFFF; /**系统起始时间,这里取2020‐01‐01 **/ private long startTimeStamp = 1577836800000L; /** 上次生成 ID 的时间截 */ private long lastTimestamp = ‐1L; /** 工作机器 ID(0~31) */ private long workerId; /** 数据中心 ID(0~31) */ private long datacenterId; /** 毫秒内序列(0~4095) */ private long sequence = 0L; /** * @param datacenterId 数据中心 ID (0~31) * @param workerId 工作机器 ID (0~31) */ public Snowflake(@Value("${snowflake.datacenterId}") long datacenterId, @Value("${snowflake.workerId}") long workerId) { if (workerId > 31 || workerId < 0) { throw new IllegalArgumentException("workId必须在0‐31之间,当前="+workerId); } if (datacenterId > 31 || datacenterId < 0) { throw new IllegalArgumentException("datacenterId必须在0‐31之间,当前="+datacenterId); } this.workerId = workerId; this.datacenterId = datacenterId; } /** * 加锁,线程安全 * @return long 类型的 ID */ public synchronized long nextId() { long timestamp = currentTime(); // 如果当前时间小于上一次 ID 生成的时间戳,说明系统时钟回退过这个时候应当抛出异常 if (timestamp < lastTimestamp) { throw new RuntimeException("时钟回退!时间差="+(lastTimestamp ‐ timestamp)); } // 同一毫秒内,序列增加 if (lastTimestamp == timestamp) { //超出阈值。思考下为什么这么运算? sequence = (sequence + 1) & SEQUENCE_MASK; // 毫秒内序列溢出 if (sequence == 0) { //自旋等待下一毫秒 while ((timestamp= currentTime()) <= lastTimestamp); } } else { //已经进入下一毫秒,从0开始计数 sequence = 0L; } //赋值为新的时间戳 lastTimestamp = timestamp; //移位拼接 long id = ((timestamp ‐ startTimeStamp) << 22) | (datacenterId << 17) | (workerId << 12) | sequence; System.out.println("new id = "+id); System.out.println("bit id = "+toBit(id)); return id; } /** * 返回当前时间,以毫秒为单位 */ protected long currentTime() { return System.currentTimeMillis(); } /** * 转成二进制展示 */ public static String toBit(long id){ String bit = StringUtils.leftPad(Long.toBinaryString(id), 64, "0"); return bit.substring(0,1) + " ‐ " + bit.substring(1,42) + " ‐ " + bit.substring(42,52)+ " ‐ " + bit.substring(52,64); } public static void main(String[] args) { Snowflake idWorker = new Snowflake(1, 1); for (int i = 0; i < 10; i++) { long id = idWorker.nextId(); System.out.println(id); System.out.println(toBit(id)); } } }
springboot启动参数,指定机器编号:
snowflake.datacenterId=1 snowflake.workerId=1
业务部分:
/** * 自定义雪花算法 */ @GetMapping("/myflake") public Strorder myflake(int userid){ Strorder order = new Strorder(); order.setId(String.valueOf(snowflake.nextId())); order.setUserid(userid); strorderMapper.save(order); return order; }
代码启动生成,分析位数
更改机器id,分析位数
2)借助sharding配置
配置信息,非常简单
spring.shardingsphere.sharding.tables.strorder.key‐generator.column=id spring.shardingsphere.sharding.tables.strorder.key‐generator.type=SNOWFLAKE spring.shardingsphere.sharding.tables.strorder.key‐generator.props.worker.id=3
Mapper代码
@Insert({ "insert into strorder (userid)", "values (#{userid,jdbcType=INTEGER})" }) @SelectKey(statement="SELECT max(id) from strorder where userid=#{userid,jdbcType=INTEGER}", keyProperty="id", before=false, resultType=String.class) int shardingIdSave(Strorder record);
业务代码
/** * sharding的雪花算法 */ @GetMapping("/shardingFlake") public Strorder shardingFlake(int userid){ Strorder order = new Strorder(); order.setUserid(userid); strorderMapper.shardingIdSave(order); System.out.println(Snowflake.toBit(Long.valueOf(order.getId()))); return order; }
结果分析
生成的id号由sharding-jdbc自动添加到maper的sql中
机器编号为3,所以打印的bit中机器为 00011,修改为其他机器,测试结果
sharding源码分析:
package org.apache.shardingsphere.core.strategy.keygen; import com.google.common.base.Preconditions; import java.util.Calendar; import java.util.Properties; import lombok.Generated; import org.apache.shardingsphere.spi.keygen.ShardingKeyGenerator; public final class SnowflakeShardingKeyGenerator implements ShardingKeyGenerator { public static final long EPOCH; private static final long SEQUENCE_BITS = 12L; private static final long WORKER_ID_BITS = 10L; private static final long SEQUENCE_MASK = 4095L; private static final long WORKER_ID_LEFT_SHIFT_BITS = 12L; private static final long TIMESTAMP_LEFT_SHIFT_BITS = 22L; private static final long WORKER_ID_MAX_VALUE = 1024L; private static final long WORKER_ID = 0L; private static final int DEFAULT_VIBRATION_VALUE = 1; private static final int MAX_TOLERATE_TIME_DIFFERENCE_MILLISECONDS = 10; private static TimeService timeService = new TimeService(); private Properties properties = new Properties(); private int sequenceOffset = ‐1; private long sequence; private long lastMilliseconds; public SnowflakeShardingKeyGenerator() { } public String getType() { return "SNOWFLAKE"; } public synchronized Comparable<?> generateKey() { long currentMilliseconds = timeService.getCurrentMillis(); if (this.waitTolerateTimeDifferenceIfNeed(currentMilliseconds)) { currentMilliseconds = timeService.getCurrentMillis(); } if (this.lastMilliseconds == currentMilliseconds) { if (0L == (this.sequence = this.sequence + 1L & 4095L)) { currentMilliseconds = this.waitUntilNextTime(currentMilliseconds); } } else { this.vibrateSequenceOffset(); this.sequence = (long)this.sequenceOffset; } this.lastMilliseconds = currentMilliseconds; return currentMilliseconds ‐ EPOCH << 22 | this.getWorkerId() << 12 | this.sequence; } //... // 获取机器编号 private long getWorkerId() { long result = Long.valueOf(this.properties.getProperty("worker.id", String.valueOf(0L))); Preconditions.checkArgument(result >= 0L && result < 1024L); return result; } //... //序列上限,等候下一毫秒 private long waitUntilNextTime(long lastTime) { long result; for(result = timeService.getCurrentMillis(); result <= lastTime; result = timeService.getCurrentMillis()) { ; } return result; } static { Calendar calendar = Calendar.getInstance(); calendar.set(2016, 10, 1); calendar.set(11, 0); calendar.set(12, 0); calendar.set(13, 0); calendar.set(14, 0); EPOCH = calendar.getTimeInMillis(); } }
3)时钟回退问题
关于snowflake算法的缺陷(时钟回拨问题),sharding-jdbc没有给出解决方案
缺点:
(1)由于“没有一个全局时钟”,每台服务器分配的ID是绝对递增的,但从全局看,生成的ID只是趋势递增的(有些服务器的时间早,有些服务器的时间晚)
最后一个容易忽略的问题:
生成的ID,例如message-id/ order-id/ tiezi-id,在数据量大时往往需要分库分表,这些ID经常作为取模分库分表的依据,为了分库分表后数据均匀,ID生成往往有“取模随机性”的需求,所以我们通常把每秒内的序列号放在ID的最末位,保证生成的ID是随机的。
又如果,我们在跨毫秒时,序列号总是归0,会使得序列号为0的ID比较多,导致生成的ID取模后不均匀。解决方法是,序列号不是每次都归0,而是归一个0到9的随机数,这个地方。
2.5.3 第三方实现
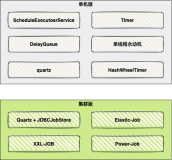
1) 百度UidGenerator
https://github.com/baidu/uid-generator/blob/master/README.zh_cn.md
位数不太一样,1-28-22-13
需要mysql数据库建表,来自动配置工作节点
支持spring配置与集成
支持bit位自定义,及bit分配相关建议
2) 美团Leaf-snowflak
https://tech.meituan.com/2017/04/21/mt-leaf.html
位数沿用snowflake方案的bit位设计
使用Zookeeper持久顺序节点的特性自动对snowflake节点配置wokerID
解决了时钟回退问题
线上可靠性验证,美团的金融、支付交易、餐饮、外卖、酒店旅游、猫眼电影等众多业务