
VIMA 是一个带有机械臂的 LLM ,它接受多模态 Prompt :文本、图像、视频或它们的混合。
是时候给大模型造个身体了,这是多家顶级研究机构在今年的 ICML 大会上向社区传递的一个重要信号。
在这次大会上,谷歌打造的 PaLM-E 和斯坦福大学李飞飞教授、英伟达高级研究科学家 Linxi "Jim" Fan(范麟熙,师从李飞飞)参与打造的 VIMA 机器人智能体悉数亮相,展示了具身智能领域的顶尖研究成果。

PaLM-E 诞生于今年 3 月份,是一个参数量达 5620 亿的具身多模态语言模型,集成了参数量 540B 的 PaLM 和参数量 22B 的视觉 Transformer(ViT),是目前已知的最大的视觉 - 语言模型。利用这个大模型控制机器人,谷歌把具身智能玩出了新高度。它能让机器人听懂人类指令,并自动将其分解为若干步骤并执行,越来越贴近人类对于智能机器人的期待和想象(更多细节参见:《5620 亿参数,最大多模态模型控制机器人,谷歌把具身智能玩出新高度》)。
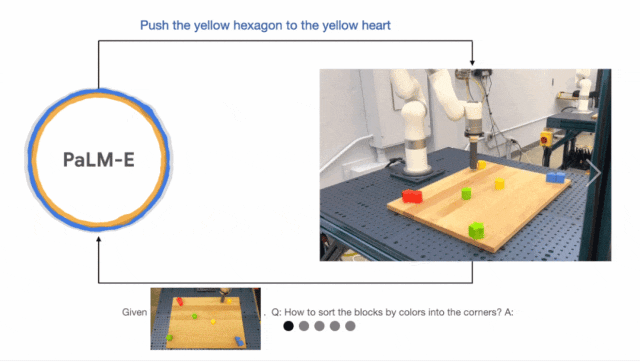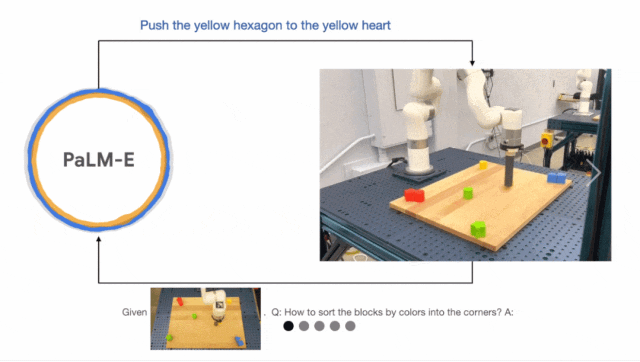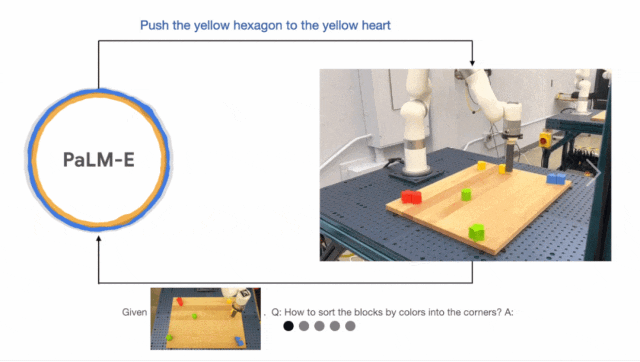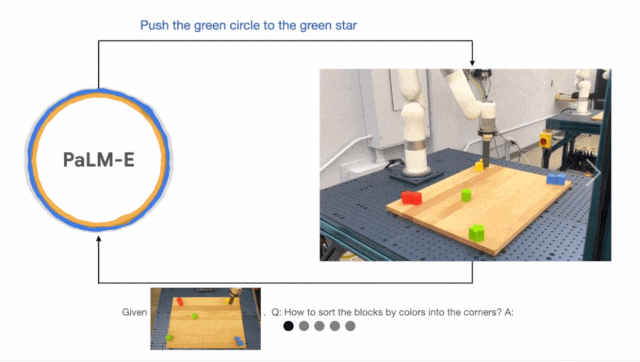
VIMA 则诞生于 2022 年 10 月,是一个基于 Transformer 架构的(仿真)机器人智能体,由来自斯坦福大学、玛卡莱斯特学院、英伟达、加州理工学院、清华大学、德克萨斯大学奥斯汀分校的多位研究者合作完成。论文一作 Yunfan Jiang 是斯坦福大学即将入学的计算机科学博士研究生,曾在英伟达实习,与 Linxi "Jim" Fan 等人合作。

论文地址:https://arxiv.org/pdf/2210.03094.pdf
论文主页:https://vimalabs.github.io/
Github 地址:https://github.com/vimalabs/VIMA
VIMA 智能体能像 GPT-4 一样接受 Prompt 输入,而且输入可以是多模态的(文本、图像、视频或它们的混合),然后输出动作,完成指定任务。
比如,我们可以要求它把积木按照图片所示摆好再还原:

让它按照视频帧的顺序完成一系列动作:

给出一些图示让它学习新概念:

通过图文混合提示对它施加一些限制:

为什么要研发这样的机器人智能体?作者在论文中写道:
在 GPT-3 等大模型中,基于 Prompt 的学习为将自然语言理解任务传达给通用模型提供了一种便捷灵活的接口。因此,他们设想,一台通用机器人也应该具备类似的直观且富有表现力的任务规范接口。
以家务机器人为例,我们可以通过简单的自然语言指令要求机器人给我们拿一杯水。如果有更具体(但语言难以准确描述)的需求,我们可以把指令改为语言 + 图像(给机器人指令的同时再给他一张参考图像,比如某个水杯的照片)。如果需要机器人学习新技能,机器人应该能够借助几个视频来自学、适应。需要与不熟悉的物体交互时,我们应该能通过几张简单的图像示例来教会机器人新的基本概念。最后,为了确保安全部署,我们可以进一步指定视觉约束,如「不要进入房间」。为了让一个机器人智能体具备所有这些能力,作者在这项工作中做出了三个关键贡献:
1、提出了一种新的多模态 prompting 形式,将各种各样的机器人操作任务转换为一个序列建模问题;
2、构建了一个大型基准,包含多样化的任务,以系统评估智能体的可扩展性和泛化能力;
3、开发了一个支持多模态 prompt 的机器人智能体,能够进行多任务学习和零样本泛化。
他们从以下观察开始:许多机器人操作任务可以通过语言、图像、视频的交织多模态 prompt 来描述(见图 1)。例如在重新排列任务中,我们可以给机器人输入以下图文 prompt:「请重新排列物品,使其与 {某场景图} 相一致」;在少样本仿真中,prompt 可以写成「遵循积木的运动轨迹:{视频帧 1}, {视频帧 2}, {视频帧 3}, {视频帧 4}」。

多模态 prompt 不仅比单个模态有更强的表达能力,还为训练通用型机器人提供了统一的序列 IO 接口。以前,不同的机器人操作任务需要不同的策略架构、目标函数、数据处理流程和训练过程,导致孤立的机器人系统无法轻易地结合多样的用例。相反,作者在论文中提出的多模态 prompt 接口使他们能够利用最新的大型 Transformer 模型进展,开发可扩展的多任务机器人学习器。
为了系统评估使用多模态 prompt 的智能体,他们开发了一个名为 VIMA-BENCH 的新基准测试,该基准构建在 Ravens 模拟器上。他们提供了 17 个具有多模态 prompt 模板的代表性任务。每个任务可以通过不同纹理和桌面物体的各种组合进行程序化实例化,产生数千个实例。VIMA-BENCH 建立了一个四级协议,逐步评估智能体的泛化能力,如图 2 所示。

该研究引入了 VIMA(VisuoMotor Attention agent)来从多模态 prompt 中学习机器人操作。模型架构遵循编码器 - 解码器 transformer 设计,这种设计在 NLP 中被证明是有效的并且是可扩展的。
为了证明 VIMA 具有可扩展性,该研究训练了 7 个模型,参数范围从 2M 到 200M 不等。结果表明本文方法优于其他设计方案,比如图像 patch token、图像感知器和仅解码器条件化(decoder-only conditioning)。在四个零样本泛化级别和所有模型容量上,VIMA 都获得了一致的性能提升,有些情况下提升幅度很大,例如在相同的训练数据量下,VIMA 任务成功率提高到最多 2.9 倍,在数据量减少 10 倍的情况下,VIMA 性能提高到 2.7 倍。
为了确保可复现性并促进社区未来的研究工作,该研究还开源了仿真环境、训练数据集、算法代码和预训练模型的 checkpoint。
方法介绍
本文旨在构建一个机器人智能体,该智能体可以执行多模态 prompt 任务。本文提出的 VIMA 兼具多任务编码器 - 解码器架构以及以对象为中心的设计。VIMA 的架构图如下:

VIMA 完整的演示流程:
,时长00:19
具体到细节,首先是输入 prompt,VIMA 包含 3 种格式:文本、包含单个对象的图像、包含全场景的图像。
对于输入文本,该研究使用预训练的 T5 tokenizer 和词嵌入来获取词 token;
对于全场景图像,该研究首先使用领域微调 Mask R-CNN 提取单个对象。每个对象通过 bounding box 和裁剪的图像来表示,之后分别使用 bounding box 编码器和 ViT 对它们进行编码,从而得到对象 token;
对于单个对象的图像,除了使用虚拟 bounding box,该研究以相同的方式获得 token。
然后,该研究遵循 Tsimpoukelli 等人的做法,通过预训练的 T5 编码器对 prompt 进行编码。由于 T5 已在大规模文本语料库上进行了预训练,因而 VIMA 继承了语义理解能力和稳健性质。为了适应来自新模态的 token,该研究在非文本 token 和 T5 之间插入了 MLP(多层感知机)层。
接着是机器人控制器。如上图 3 所示,机器人控制器(解码器)通过在 prompt 序列 P 和轨迹历史序列 H 之间使用一系列交叉注意力层来对其进行条件化。
该研究按照 Raffel 等人中的编码器 - 解码器约定,从 prompt 中计算关键键序列 K_P 和值序列 V_P,同时从轨迹历史中查询 Q_H。然后,每个交叉注意力层生成一个输出序列 ,其中 d 是嵌入维度。为了将高层与输入的轨迹历史序列相连接,该研究还添加了残差连接。
,其中 d 是嵌入维度。为了将高层与输入的轨迹历史序列相连接,该研究还添加了残差连接。
研究中还用到了交叉注意力层,其具有三个优势:1)加强与 prompt 的连接;2)保持原始 prompt token 的完整和深入流动;3)更好的计算效率。VIMA 解码器由 L 个交替的交叉注意力层和自注意力层组成。最后,该研究遵循 Baker 等人的做法,将预测的动作 token 映射到机械臂离散姿态。
最后是训练。该研究采用行为克隆(behavioral cloning)训练模型。具体而言,对于一个包含 T 个步骤的轨迹,研究者需要优化函数 。整个训练过程在一个离线数据集上进行,期间没有访问仿真器。为了使 VIMA 更具鲁棒性,该研究采用了对象增强技术,即随机注入 false-positive 检测输出。训练完成后,该研究选择模型 checkpoint 进行评估。
。整个训练过程在一个离线数据集上进行,期间没有访问仿真器。为了使 VIMA 更具鲁棒性,该研究采用了对象增强技术,即随机注入 false-positive 检测输出。训练完成后,该研究选择模型 checkpoint 进行评估。
实验
实验旨在回答以下三个问题:
基于多模态 prompt,构建多任务的、基于 transformer 的机器人智能体的最佳方案是什么?
本文方法在模型容量和数据大小方面的缩放特性是什么?
不同的组件,如视觉 tokenizers、prompt 条件和 prompt 编码,如何影响机器人的性能?
下图(上部)比较了不同模型大小(参数范围从 2M 到 200M)的性能,结果表明,VIMA 在性能上明显优于其他方法。尽管像 VIMA-Gato 和 VIMA-Flamingo 这样的模型在较大的模型大小下表现有所提升,但 VIMA 在所有模型大小上始终表现出优异的性能。
下图(底部)固定模型大小为 92M,比较了不同数据集大小(0.1%、1%、10% 和完整数据)带来的影响。结果表明,VIMA 具有极高的样本效率,可以在数据为原来 1/10 的情况下实现与其他方法相当的性能。

对视觉 tokenizer 的消融研究:下图比较了 VIMA-200M 模型在不同视觉 tokenizer 上的性能。结果表明,本文提出的对象 token 优于所有直接从原始像素学习的方法,此外,这种方法还优于 Object Perceiver 方法。

下图表明,交叉注意力在低参数状态和较难的泛化任务中特别有用。

相关阅读:
《5620 亿参数,最大多模态模型控制机器人,谷歌把具身智能玩出新高度》

