pytorch lightning 官方手册
pytorch lightning 官方手册 Welcome to ⚡ PyTorch Lightning — PyTorch Lightning 2.1.0dev documentation
https://lightning.ai/docs/pytorch/latest/
Pytorch Lightning简介
PyTorch Lightning是面向专业AI研究人员和机器学习工程师的深度学习框架,他们需要在不牺牲大规模性能的情况下获得最大的灵活性。lightning 使你的想法到论文和产品同样速度。
LightningModule是原始PyTorch的一个轻量化结构,允许最大的灵活性和最小的库文件。它作为一个模型“配方”,指定所有的训练细节。
少写80%的代码。Lightning删除了大约80%的重复代码(样板),以最小化bug的表面面积,这样您就可以专注于交付价值而不是工程。
保持最大的灵活性,可以在training_step中定义完整的PyTorch训练代码。
处理任意大小的数据集,没有特殊的要求,直接使用PyTorch dataloader处理海量数据集

安装Lightning
pip install lightning
或者
conda install lightning -c conda-forge
安装后导入相关包
from pytorch_lightning.callbacks import ModelCheckpoint from pytorch_lightning import LightningModule, Trainer from pytorch_lightning.loggers import TestTubeLogger
定义LightningModule
LightningModule将你的PyTorch代码组织成6个部分:
初始化(__init__和setup())。
训练 (training_step())
验证(validation_step())
测试(test_step())
预测(predict_step())
优化器和LR调度器(configure_optimizers())
当你使用Lightning时,代码不是抽象的——只是组织起来的。所有不在LightningModule中的其他代码都已由Trainer自动为您执行。
net = MyLightningModuleNet() trainer = Trainer() trainer.fit(net)
不需要.cuda()或.to(device)调用。Lightning已经为你做了这些。如下:
# don't do in Lightning x = torch.Tensor(2, 3) x = x.cuda() x = x.to(device) # do this instead x = x # leave it alone! # or to init a new tensor new_x = torch.Tensor(2, 3) new_x = new_x.to(x)
当在分布式策略下运行时,默认情况下,Lightning会为您处理分布式采样器。
# Don't do in Lightning... data = MNIST(...) sampler = DistributedSampler(data) DataLoader(data, sampler=sampler) # do this instead data = MNIST(...) DataLoader(data)
LightningModule其实是一个torch.nn.Module,但增加了一些功能:
net = Net.load_from_checkpoint(PATH) net.freeze() out = net(x)
示例:利用Lightning 构建网络训练网络
1. 构建模型
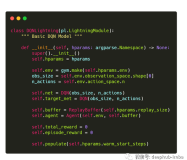
import lightning.pytorch as pl import torch.nn as nn import torch.nn.functional as F class LitModel(pl.LightningModule): def __init__(self): super().__init__() self.l1 = nn.Linear(28 * 28, 10) def forward(self, x): return torch.relu(self.l1(x.view(x.size(0), -1))) def training_step(self, batch, batch_idx): x, y = batch y_hat = self(x) loss = F.cross_entropy(y_hat, y) return loss def configure_optimizers(self): return torch.optim.Adam(self.parameters(), lr=0.02)
2 训练网络
train_loader = DataLoader(MNIST(os.getcwd(), download=True, transform=transforms.ToTensor())) trainer = pl.Trainer(max_epochs=1) model = LitModel() trainer.fit(model, train_dataloaders=train_loader)
3 其他LightningModule:
Name |
Description |
|
初始化 |
|
仅通过模型运行数据(与training_step分开) |
|
完整的训练步骤 |
|
完整的验证步骤 |
|
完整的测试步骤 |
|
完整的预测步骤 |
|
定义优化器和LR调度器 |
3.1 Lightning 数据集加载
数据集有两种实现方法:
- 直接调用第三方公开数据集(如:MNIST等数据集)
- 自定义数据集(自己去继承torch.utils.data.dataset.Dataset,自定义类)
3.1.1 使用公开数据集
from torch.utils.data import DataLoader, random_split import pytorch_lightning as pl class MyExampleModel(pl.LightningModule): def __init__(self, args): super().__init__() dataset = MNIST(os.getcwd(), download=True, transform=transforms.ToTensor()) train_dataset, val_dataset, test_dataset = random_split(dataset, [50000, 5000, 5000]) self.train_dataset = train_dataset self.val_dataset = val_dataset self.test_dataset = test_dataset ... def train_dataloader(self): return DataLoader(self.train_dataset, batch_size=self.batch_size, shuffle=False, num_workers=0) def val_dataloader(self): return DataLoader(self.val_dataset, batch_size=self.batch_size, shuffle=False) def test_dataloader(self): return DataLoader(self.test_dataset, batch_size=1, shuffle=True)
3.1.2 自定义dataset
(1)自己完成dataset的编写
# -*- coding: utf-8 -*- ''' @Description: Define the format of data used in the model. ''' import sys import pathlib import torch from torch.utils.data import Dataset from utils import sort_batch_by_len, source2ids abs_path = pathlib.Path(__file__).parent.absolute() sys.path.append(sys.path.append(abs_path)) class SampleDataset(Dataset): """ The class represents a sample set for training. """ def __init__(self, data_pairs, vocab): self.src_texts = [data_pair[0] for data_pair in data_pairs] self.tgt_texts = [data_pair[1] for data_pair in data_pairs] self.vocab = vocab self._len = len(data_pairs) # Keep track of how many data points. def __len__(self): return self._len def __getitem__(self, index): # print("\nself.src_texts[{0}] = {1}".format(index, self.src_texts[index])) src_ids, oovs = source2ids(self.src_texts[index], self.vocab) # 将当前文本self.src_texts[index]转为ids,oovs为超出词典范围的词汇文本 item = { 'x': [self.vocab.SOS] + src_ids + [self.vocab.EOS], 'y': [self.vocab.SOS] + [self.vocab[i] for i in self.tgt_texts[index]] + [self.vocab.EOS], 'x_len': len(self.src_texts[index]), 'y_len': len(self.tgt_texts[index]), 'oovs': oovs, 'len_oovs': len(oovs) } return item
(2)自定义DataModule类(继承LightningDataModule)来调用DataLoader
from torch.utils.data import DataLoader, random_split import pytorch_lightning as pl class MyDataModule(pl.LightningDataModule): def __init__(self): super().__init__() def prepare_data(self): # 在该函数里一般实现数据集的下载等,只有cuda:0 会执行该函数 # download, split, etc... # only called on 1 GPU/TPU in distributed pass def forward() def setup(self, stage): # make assignments here (val/train/test split) # called on every process in DDP # 实现数据集的定义,每张GPU都会执行该函数, stage 用于标记是用于什么阶段 if stage == 'fit' or stage is None: self.train_dataset = MyDataset(self.train_file_path, self.train_file_num, transform=None) self.val_dataset = MyDataset(self.val_file_path, self.val_file_num, transform=None) if stage == 'test' or stage is None: self.test_dataset = MyDataset(self.test_file_path, self.test_file_num, transform=None) def train_dataloader(self): return DataLoader(self.train_dataset, batch_size=self.batch_size, shuffle=False, num_workers=0) def val_dataloader(self): return DataLoader(self.val_dataset, batch_size=self.batch_size, shuffle=False) def test_dataloader(self): return DataLoader(self.test_dataset, batch_size=1, shuffle=True)
3.2Training
3.2.1Training Loop:
要激活训练循环,重写training_step()。
class LitClassifier(pl.LightningModule): def __init__(self, model): super().__init__() self.model = model def training_step(self, batch, batch_idx): x, y = batch y_hat = self.model(x) loss = F.cross_entropy(y_hat, y) return loss #一定要返回loss,其中batch 即为从 train_dataloader 采样的一个batch的数据,batch_idx即为目前batch的索引
3.2.2 Train Epoch-level Metrics:
如果您想计算时间级别的度量并记录它们,请使用log()。
def training_step(self, batch, batch_idx): x, y = batch y_hat = self.model(x) loss = F.cross_entropy(y_hat, y) # logs metrics for each training_step, # and the average across the epoch, to the progress bar and logger self.log("train_loss", loss, on_step=True, on_epoch=True, prog_bar=True, logger=True) return loss
3.2.3Train Epoch-level Operations
如果需要使用每个training_step()的所有输出,则重写 on_train_epoch_end()方法。
def __init__(self): super().__init__() self.training_step_outputs = [] def training_step(self, batch, batch_idx): x, y = batch y_hat = self.model(x) loss = F.cross_entropy(y_hat, y) preds = ... self.training_step_outputs.append(preds) return loss def on_train_epoch_end(self): all_preds = torch.stack(self.training_step_outputs) # do something with all preds ... self.training_step_outputs.clear() # free memory
3.3 Validation
3.3.1 Validation Loop
要在训练时激活验证循环,重写validation_step()函数。
class LitModel(pl.LightningModule): def validation_step(self, batch, batch_idx): x, y = batch y_hat = self.model(x) loss = F.cross_entropy(y_hat, y) self.log("val_loss", loss)
也可以通过重写validation_step()并调用validate(),在验证数据加载器上只运行验证循环。
model = Model() trainer = Trainer() trainer.validate(model)
建议在单个设备上进行验证,以确保每个样品/取样得到准确评估一次。这有助于确保以正确的方式对研究论文进行基准测试。否则,在多设备设置中,当使用DistributedSampler时,样本可能会重复,例如strategy="ddp"。它在一些设备上复制一些样本,以确保所有设备在输入不均匀的情况下具有相同的批大小。
3.3.2 Validation Epoch-level Metrics
如果需要使用每个validation_step()的所有输出,则重写 on_validation_epoch_end()函数。注意,这个方法在on_train_epoch_end()之前调用。
def __init__(self): super().__init__() self.validation_step_outputs = [] def validation_step(self, batch, batch_idx): x, y = batch y_hat = self.model(x) loss = F.cross_entropy(y_hat, y) pred = ... self.validation_step_outputs.append(pred) return pred def on_validation_epoch_end(self): all_preds = torch.stack(self.validation_step_outputs) # do something with all preds ... self.validation_step_outputs.clear() # free memory
3.4 Testing
3.4.1Test Loop
启用测试循环的过程与启用验证循环的过程相同。详情请参阅上述部分。为此,重写test_step()函数。
model = Model() trainer = Trainer() trainer.fit(model) # automatically loads the best weights for you trainer.test(model)
有两种方式来调用test():
# call after training trainer = Trainer() trainer.fit(model) # automatically auto-loads the best weights from the previous run trainer.test(dataloaders=test_dataloader) # or call with pretrained model model = MyLightningModule.load_from_checkpoint(PATH) trainer = Trainer() trainer.test(model, dataloaders=test_dataloader)
同上, 建议在单个设备上进行验证,以确保每个样品得到准确评估一次。这有助于确保以正确的方式对研究论文进行基准测试。否则,在多设备设置中,当使用DistributedSampler时,样本可能会重复,例如。策略=“ddp”。它在一些设备上复制一些样本,以确保所有设备在输入不均匀的情况下具有相同的批大小。
3.5 Inference
3.5.1Prediction Loop
默认情况下,predict_step()方法运行forward()方法。为了定制这种行为,只需重写predict_step()方法。如下,重写predict_step()并尝试Monte Carlo Dropout:
class LitMCdropoutModel(pl.LightningModule): def __init__(self, model, mc_iteration): super().__init__() self.model = model self.dropout = nn.Dropout() self.mc_iteration = mc_iteration def predict_step(self, batch, batch_idx): # enable Monte Carlo Dropout self.dropout.train() # take average of `self.mc_iteration` iterations pred = torch.vstack([self.dropout(self.model(x)).unsqueeze(0) for _ in range(self.mc_iteration)]).mean(dim=0) return pred
两种方式调用 predict():
# call after training trainer = Trainer() trainer.fit(model) # automatically auto-loads the best weights from the previous run predictions = trainer.predict(dataloaders=predict_dataloader) # or call with pretrained model model = MyLightningModule.load_from_checkpoint(PATH) trainer = Trainer() predictions = trainer.predict(model, dataloaders=test_dataloader)
NOTE:
在training_step 后面都紧跟着其相应的 training_step_end(self,batch_parts)和training_epoch_end(self, training_step_outputs) 函数;
validation_step 后面都紧跟着其相应的 validation_step_end(self,batch_parts)和validation_epoch_end(self, training_step_outputs) 函数;
test_step 后面都紧跟着其相应的 test_step_end(self,batch_parts)和 test_epoch_end(self, training_step_outputs) 函数
3.6 利用Trainer保存模型
在Trainer中设置default_root_dir参数, Lightning 会自动保存最近训练的epoch的模型到当前的工作空间(or.getcwd()),也可以在定义Trainer的时候指定:
trainer = Trainer(default_root_dir='/your/path/to/save/checkpoints')
也可以关闭自动保存模型:
trainer = Trainer(checkpoint_callback=False
3.7 加载预训练模型,完整流程
def main(hparams): system = NeRFSystem(hparams) checkpoint_callback = \ ModelCheckpoint(filepath=os.path.join(f'ckpts/{hparams.exp_name}', '{epoch:d}'), monitor='val/psnr', mode='max', save_top_k=-1) logger = TestTubeLogger(save_dir="logs", name=hparams.exp_name, debug=False, create_git_tag=False, log_graph=False) trainer = Trainer(max_epochs=hparams.num_epochs, checkpoint_callback=checkpoint_callback, resume_from_checkpoint=hparams.ckpt_path, logger=logger, weights_summary=None, progress_bar_refresh_rate=hparams.refresh_every, gpus=hparams.num_gpus, accelerator='ddp' if hparams.num_gpus>1 else None, num_sanity_val_steps=1, benchmark=True, profiler="simple" if hparams.num_gpus==1 else None) trainer.fit(system) if __name__ == '__main__': hparams = get_opts() main(hparams)
4 完整实例如下,NeRFW:
import os from opt import get_opts import torch from collections import defaultdict from torch.utils.data import DataLoader from datasets import dataset_dict # models from models.nerf import * from models.rendering import * # optimizer, scheduler, visualization from utils import * # losses from losses import loss_dict # metrics from metrics import * # pytorch-lightning from pytorch_lightning.callbacks import ModelCheckpoint from pytorch_lightning import LightningModule, Trainer from pytorch_lightning.loggers import TestTubeLogger class NeRFSystem(LightningModule): def __init__(self, hparams): super().__init__() self.hparams = hparams # self.hparams.update(hparams) self.loss = loss_dict['nerfw'](coef=1) self.models_to_train = [] self.embedding_xyz = PosEmbedding(hparams.N_emb_xyz-1, hparams.N_emb_xyz) self.embedding_dir = PosEmbedding(hparams.N_emb_dir-1, hparams.N_emb_dir) self.embeddings = {'xyz': self.embedding_xyz, 'dir': self.embedding_dir} if hparams.encode_a: self.embedding_a = torch.nn.Embedding(hparams.N_vocab, hparams.N_a) self.embeddings['a'] = self.embedding_a self.models_to_train += [self.embedding_a] if hparams.encode_t: self.embedding_t = torch.nn.Embedding(hparams.N_vocab, hparams.N_tau) self.embeddings['t'] = self.embedding_t self.models_to_train += [self.embedding_t] self.nerf_coarse = NeRF('coarse', in_channels_xyz=6*hparams.N_emb_xyz+3, in_channels_dir=6*hparams.N_emb_dir+3) self.models = {'coarse': self.nerf_coarse} if hparams.N_importance > 0: self.nerf_fine = NeRF('fine', in_channels_xyz=6*hparams.N_emb_xyz+3, in_channels_dir=6*hparams.N_emb_dir+3, encode_appearance=hparams.encode_a, in_channels_a=hparams.N_a, encode_transient=hparams.encode_t, in_channels_t=hparams.N_tau, beta_min=hparams.beta_min) self.models['fine'] = self.nerf_fine self.models_to_train += [self.models] def get_progress_bar_dict(self): items = super().get_progress_bar_dict() items.pop("v_num", None) return items def forward(self, rays, ts): """Do batched inference on rays using chunk.""" B = rays.shape[0] results = defaultdict(list) for i in range(0, B, self.hparams.chunk): rendered_ray_chunks = \ render_rays(self.models, self.embeddings, rays[i:i+self.hparams.chunk], ts[i:i+self.hparams.chunk], self.hparams.N_samples, self.hparams.use_disp, self.hparams.perturb, self.hparams.noise_std, self.hparams.N_importance, self.hparams.chunk, # chunk size is effective in val mode self.train_dataset.white_back) for k, v in rendered_ray_chunks.items(): results[k] += [v] for k, v in results.items(): results[k] = torch.cat(v, 0) return results def setup(self, stage): dataset = dataset_dict[self.hparams.dataset_name] kwargs = {'root_dir': self.hparams.root_dir} if self.hparams.dataset_name == 'phototourism': kwargs['img_downscale'] = self.hparams.img_downscale kwargs['val_num'] = self.hparams.num_gpus kwargs['use_cache'] = self.hparams.use_cache elif self.hparams.dataset_name == 'blender': kwargs['img_wh'] = tuple(self.hparams.img_wh) kwargs['perturbation'] = self.hparams.data_perturb self.train_dataset = dataset(split='train', **kwargs) self.val_dataset = dataset(split='val', **kwargs) def configure_optimizers(self): self.optimizer = get_optimizer(self.hparams, self.models_to_train) scheduler = get_scheduler(self.hparams, self.optimizer) return [self.optimizer], [scheduler] def train_dataloader(self): return DataLoader(self.train_dataset, shuffle=True, num_workers=4, batch_size=self.hparams.batch_size, pin_memory=True) def val_dataloader(self): return DataLoader(self.val_dataset, shuffle=False, num_workers=4, batch_size=1, # validate one image (H*W rays) at a time pin_memory=True) def training_step(self, batch, batch_nb): rays, rgbs, ts = batch['rays'], batch['rgbs'], batch['ts'] results = self(rays, ts) loss_d = self.loss(results, rgbs) loss = sum(l for l in loss_d.values()) with torch.no_grad(): typ = 'fine' if 'rgb_fine' in results else 'coarse' psnr_ = psnr(results[f'rgb_{typ}'], rgbs) self.log('lr', get_learning_rate(self.optimizer)) self.log('train/loss', loss) for k, v in loss_d.items(): self.log(f'train/{k}', v, prog_bar=True) self.log('train/psnr', psnr_, prog_bar=True) return loss def validation_step(self, batch, batch_nb): rays, rgbs, ts = batch['rays'], batch['rgbs'], batch['ts'] rays = rays.squeeze() # (H*W, 3) rgbs = rgbs.squeeze() # (H*W, 3) ts = ts.squeeze() # (H*W) results = self(rays, ts) loss_d = self.loss(results, rgbs) loss = sum(l for l in loss_d.values()) log = {'val_loss': loss} typ = 'fine' if 'rgb_fine' in results else 'coarse' if batch_nb == 0: if self.hparams.dataset_name == 'phototourism': WH = batch['img_wh'] W, H = WH[0, 0].item(), WH[0, 1].item() else: W, H = self.hparams.img_wh img = results[f'rgb_{typ}'].view(H, W, 3).permute(2, 0, 1).cpu() # (3, H, W) img_gt = rgbs.view(H, W, 3).permute(2, 0, 1).cpu() # (3, H, W) depth = visualize_depth(results[f'depth_{typ}'].view(H, W)) # (3, H, W) stack = torch.stack([img_gt, img, depth]) # (3, 3, H, W) self.logger.experiment.add_images('val/GT_pred_depth', stack, self.global_step) psnr_ = psnr(results[f'rgb_{typ}'], rgbs) log['val_psnr'] = psnr_ return log def validation_epoch_end(self, outputs): mean_loss = torch.stack([x['val_loss'] for x in outputs]).mean() mean_psnr = torch.stack([x['val_psnr'] for x in outputs]).mean() self.log('val/loss', mean_loss) self.log('val/psnr', mean_psnr, prog_bar=True) def main(hparams): system = NeRFSystem(hparams) checkpoint_callback = \ ModelCheckpoint(filepath=os.path.join(f'ckpts/{hparams.exp_name}', '{epoch:d}'), monitor='val/psnr', mode='max', save_top_k=-1) logger = TestTubeLogger(save_dir="logs", name=hparams.exp_name, debug=False, create_git_tag=False, log_graph=False) trainer = Trainer(max_epochs=hparams.num_epochs, checkpoint_callback=checkpoint_callback, resume_from_checkpoint=hparams.ckpt_path, logger=logger, weights_summary=None, progress_bar_refresh_rate=hparams.refresh_every, gpus=hparams.num_gpus, accelerator='ddp' if hparams.num_gpus>1 else None, num_sanity_val_steps=1, benchmark=True, profiler="simple" if hparams.num_gpus==1 else None) trainer.fit(system) if __name__ == '__main__': hparams = get_opts() main(hparams)