1. 现象
线上k8s集群报警,登陆查看dockerd内存使用10G+(Node集群大小是15G),Dockerd占用内存70%
2. 排查思路
2.1 docker 版本
查看docker info 和docker version是否有特殊配置
docker info:
Client:
Debug Mode: false
Server:
Containers: 54
Running: 26
Paused: 0
Stopped: 28
Images: 60
Server Version: 19.03.15
Storage Driver: overlay2
Backing Filesystem: xfs
Supports d_type: true
Native Overlay Diff: true
Logging Driver: json-file
Cgroup Driver: cgroupfs
Plugins:
Volume: local
Network: bridge host ipvlan macvlan null overlay
Log: awslogs fluentd gcplogs gelf journald json-file local logentries splunk syslog
Swarm: inactive
Runtimes: runc
Default Runtime: runc
Init Binary: docker-init
containerd version: 8686ededfc90076914c5238eb96c883ea093a8ba
runc version: v1.0.2-0-g52b36a2d
init version: fec3683
Security Options:
seccomp
Profile: default
Kernel Version: 4.19.25-200.1.el7.bclinux.x86_64
Operating System: BigCloud Enterprise Linux For LDK 7 (Core)
OSType: linux
Architecture: x86_64
CPUs: 8
Total Memory: 15.16GiB
Name: ecs-prod-003
ID: SBD2:S775:KOMB:TU2S:YSN6:6OJ7:U4KS:DLCT:QVM4:5UCI:YUA4:NEUC
Docker Root Dir: /var/lib/docker
Debug Mode: true
File Descriptors: 173
Goroutines: 167
System Time: 2023-05-08T17:01:41.750342975+08:00
EventsListeners: 0
Registry: https://index.docker.io/v1/
Labels:
Experimental: false
Insecure Registries:
0.0.0.0/0
127.0.0.0/8
Registry Mirrors:
http://xx.xx.xx.xx:7999/
Live Restore Enabled: true
[root@ecs-xxxx-003 /]# dockerd -v
Docker version 19.03.15, build 99e3ed8919
docker version
Client: Docker Engine - Community
Version: 19.03.15
API version: 1.40
Go version: go1.13.15
Git commit: 99e3ed8919
Built: Sat Jan 30 03:17:57 2021
OS/Arch: linux/amd64
Experimental: false
Server: Docker Engine - Community
Engine:
Version: 19.03.15
API version: 1.40 (minimum version 1.12)
Go version: go1.13.15
Git commit: 99e3ed8919
Built: Sat Jan 30 03:16:33 2021
OS/Arch: linux/amd64
Experimental: false
containerd:
Version: v1.5.7
GitCommit: 8686ededfc90076914c5238eb96c883ea093a8ba
runc:
Version: 1.0.2
GitCommit: v1.0.2-0-g52b36a2d
docker-init:
Version: 0.18.0
GitCommit: fec3683
Storage Driver: overlay2 也是用最新版本,没有问题的; containerd version也是依赖v1.5.7 、runc 也是比较高版本1.0.2 整个版本还算比较新
PS: debug模式,也是出现问题后,重启dockerd之前开启的。 不会有大影响;
2.2 daeman.json 配置
[root@ecs-xxx-003 /]# cat /etc/docker/daemon.json
{
"debug": true,
"live-restore": true,
"registry-mirrors": ["http://xxx.xxx.xxx.xxx:7999"]
}
[root@ecs-xxx-003 /]# service docker status
Redirecting to /bin/systemctl status docker.service
● docker.service - Docker Application Container Engine
Loaded: loaded (/usr/lib/systemd/system/docker.service; enabled; vendor preset: disabled)
Active: active (running) since Thu 2023-05-04 10:18:14 CST; 5 days ago
Docs: https://docs.docker.com
Main PID: 160002 (dockerd)
Tasks: 41
Memory: 2.1G
CGroup: /system.slice/docker.service
└─160002 /usr/bin/dockerd --insecure-registry=0.0.0.0/0 --data-root=/var/lib/docker --log-opt max-size=50m --log-opt max-file=5 -H fd:// --containerd=/run/containerd/containerd.sock
开启了live-restore模式。设置了--data-root数据存储路径和 --log-opt 日志滚动切分。 功能设置也正常
2.3 日志是否有问题
首先查询dockerd file日志,观察固定时间内:
....
May 2 00:10:24 ecs-prod-003 dockerd: time="2023-05-02T00:10:24.148458112+08:00" level=info msg="Container a9acd5210705 failed to exit within 10 seconds of kill - trying direct SIGKILL"
May 2 00:10:36 ecs-prod-003 dockerd: time="2023-05-02T00:10:36.020613181+08:00" level=info msg="Container a9acd5210705c3e2e95ca459d1b244883c0ba2a5ee94650cb2fa23422367e6e9 failed to exit within 10 seconds of signal 15 - using the force"
May 2 00:10:46 ecs-prod-003 dockerd: time="2023-05-02T00:10:46.108339401+08:00" level=info msg="Container a9acd5210705 failed to exit within 10 seconds of kill - trying direct SIGKILL"
May 2 00:10:58 ecs-prod-003 dockerd: time="2023-05-02T00:10:58.034965957+08:00" level=info msg="Container a9acd5210705c3e2e95ca459d1b244883c0ba2a5ee94650cb2fa23422367e6e9 failed to exit within 10 seconds of signal 15 - using the force"
May 2 00:11:08 ecs-prod-003 dockerd: time="2023-05-02T00:11:08.184787392+08:00" level=info msg="Container a9acd5210705 failed to exit within 10 seconds of kill - trying direct SIGKILL"
May 2 00:11:20 ecs-prod-003 dockerd: time="2023-05-02T00:11:20.072593490+08:00" level=info msg="Container a9acd5210705c3e2e95ca459d1b244883c0ba2a5ee94650cb2fa23422367e6e9 failed to exit within 10 seconds of signal 15 - using the force"
May 2 00:11:30 ecs-prod-003 dockerd: time="2023-05-02T00:11:30.193889464+08:00" level=info msg="Container a9acd5210705 failed to exit within 10 seconds of kill - trying direct SIGKILL"
May 2 00:11:42 ecs-prod-003 dockerd: time="2023-05-02T00:11:42.031475401+08:00" level=info msg="Container a9acd5210705c3e2e95ca459d1b244883c0ba2a5ee94650cb2fa23422367e6e9 failed to exit within 10 seconds of signal 15 - using the force"
May 2 00:11:52 ecs-prod-003 dockerd: time="2023-05-02T00:11:52.118355116+08:00" level=info msg="Container a9acd5210705 failed to exit within 10 seconds of kill - trying direct SIGKILL"
May 2 00:12:04 ecs-prod-003 dockerd: time="2023-05-02T00:12:04.051169727+08:00" level=info msg="Container a9acd5210705c3e2e95ca459d1b244883c0ba2a5ee94650cb2fa23422367e6e9 failed to exit within 10 seconds of signal 15 - using the force"
May 2 00:12:14 ecs-prod-003 dockerd: time="2023-05-02T00:12:14.164452224+08:00" level=info msg="Container a9acd5210705 failed to exit within 10 seconds of kill - trying direct SIGKILL"
May 2 00:12:26 ecs-prod-003 dockerd: time="2023-05-02T00:12:26.043414628+08:00" level=info msg="Container a9acd5210705c3e2e95ca459d1b244883c0ba2a5ee94650cb2fa23422367e6e9 failed to exit within 10 seconds of signal 15 - using the force"
May 2 00:12:36 ecs-prod-003 dockerd: time="2023-05-02T00:12:36.083507423+08:00" level=info msg="Container a9acd5210705 failed to exit within 10 seconds of kill - trying direct SIGKILL"
May 2 00:12:48 ecs-prod-003 dockerd: time="2023-05-02T00:12:48.285459273+08:00" level=info msg="Container a9acd5210705c3e2e95ca459d1b244883c0ba2a5ee94650cb2fa23422367e6e9 failed to exit within 10 seconds of signal 15 - using the force"
May 2 00:12:58 ecs-prod-003 dockerd: time="2023-05-02T00:12:58.429207582+08:00" level=info msg="Container a9acd5210705 failed to exit within 10 seconds of kill - trying direct SIGKILL"
时间刚好好从4月30日到5月2日,比较大量的failed to exit within 10 seconds of signal 15 - using the force 和 failed to exit within 10 seconds of kill - trying direct SIGKILL
可能是问题所在。
3. 流程梳理:dockerd与containerd相关处理流
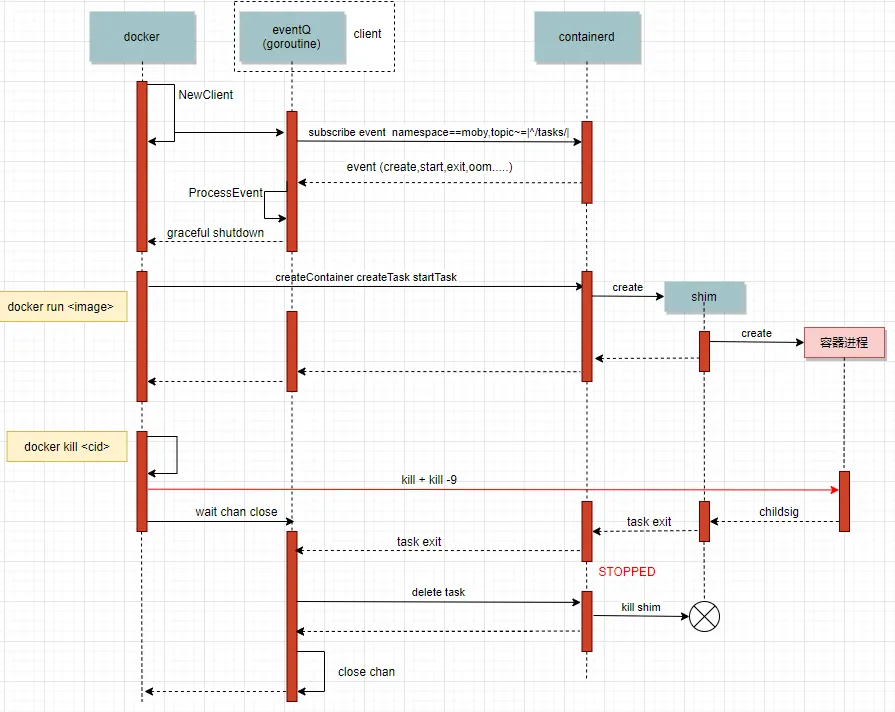
dockerd和底层containerd-shim 整个生命交互流程如上图。
4. 源码梳理
Kubelet的PLGE Pod生命周期管理,会给docker发送stop Event, 如果没有相应在发送kill Event. docker kill时的wait chan close导致的,wait的时候会启动另一个goroutine,每次docker kill都会造成这两个goroutine的泄露。
docker stop部分:
// containerStop sends a stop signal, waits, sends a kill signal.
func (daemon *Daemon) containerStop(container *containerpkg.Container, seconds int) error {
if !container.IsRunning() {
return nil
}
stopSignal := container.StopSignal()
// 1. Send a stop signal
if err := daemon.killPossiblyDeadProcess(container, stopSignal); err != nil {
// While normally we might "return err" here we're not going to
// because if we can't stop the container by this point then
// it's probably because it's already stopped. Meaning, between
// the time of the IsRunning() call above and now it stopped.
// Also, since the err return will be environment specific we can't
// look for any particular (common) error that would indicate
// that the process is already dead vs something else going wrong.
// So, instead we'll give it up to 2 more seconds to complete and if
// by that time the container is still running, then the error
// we got is probably valid and so we force kill it.
ctx, cancel := context.WithTimeout(context.Background(), 2*time.Second)
defer cancel()
if status := <-container.Wait(ctx, containerpkg.WaitConditionNotRunning); status.Err() != nil {
logrus.Infof("Container failed to stop after sending signal %d to the process, force killing", stopSignal)
if err := daemon.killPossiblyDeadProcess(container, 9); err != nil {
return err
}
}
}
// 2. Wait for the process to exit on its own
ctx := context.Background()
if seconds >= 0 {
var cancel context.CancelFunc
ctx, cancel = context.WithTimeout(ctx, time.Duration(seconds)*time.Second)
defer cancel()
}
if status := <-container.Wait(ctx, containerpkg.WaitConditionNotRunning); status.Err() != nil {
logrus.Infof("Container %v failed to exit within %d seconds of signal %d - using the force", container.ID, seconds, stopSignal)
// 3. If it doesn't, then send SIGKILL
if err := daemon.Kill(container); err != nil {
// Wait without a timeout, ignore result.
<-container.Wait(context.Background(), containerpkg.WaitConditionNotRunning) //这一步会挂起
logrus.Warn(err) // Don't return error because we only care that container is stopped, not what function stopped it
}
}
daemon.LogContainerEvent(container, "stop")
return nil
}
docker kill部分代码:
// Kill forcefully terminates a container.
func (daemon *Daemon) Kill(container *containerpkg.Container) error {
if !container.IsRunning() {
return errNotRunning(container.ID)
}
// 1. Send SIGKILL
if err := daemon.killPossiblyDeadProcess(container, int(syscall.SIGKILL)); err != nil {
// While normally we might "return err" here we're not going to
// because if we can't stop the container by this point then
// it's probably because it's already stopped. Meaning, between
// the time of the IsRunning() call above and now it stopped.
// Also, since the err return will be environment specific we can't
// look for any particular (common) error that would indicate
// that the process is already dead vs something else going wrong.
// So, instead we'll give it up to 2 more seconds to complete and if
// by that time the container is still running, then the error
// we got is probably valid and so we return it to the caller.
if isErrNoSuchProcess(err) {
return nil
}
ctx, cancel := context.WithTimeout(context.Background(), 2*time.Second)
defer cancel()
if status := <-container.Wait(ctx, containerpkg.WaitConditionNotRunning); status.Err() != nil {
return err
}
}
// 2. Wait for the process to die, in last resort, try to kill the process directly
if err := killProcessDirectly(container); err != nil {
if isErrNoSuchProcess(err) {
return nil
}
return err
}
// Wait for exit with no timeout.
// Ignore returned status.
<-container.Wait(context.Background(), containerpkg.WaitConditionNotRunning) //这一步会挂起
return nil
}
具体可以查看: v19.03.15中kill部分、 v19.03.15中stop部分
因为没收到containerd发来的task exit的信号,无法从container.Wait返回的chan中读到数据,从而导致每次docker stop调用阻塞两个goroutine。 导致goroutine 泄露。
到底是那个 pod 和 container 导致问题.

验证了确实在不断删除容器,但是删不掉,是容器 D进程 或者 Z 进程导致
5. 本问题梳理
Kubelet 为了保证最终一致性,发现宿主上还有不应该存在的容器就会一直不断的去尝试删除,每次删除都会调用docker stop的api,与dockerd建立一个uds连接,dockerd删除容器的时候会启动一个goroutine通过rpc形式调用containerd来删除容器并等待最终删除完毕才返回,等待的过程中会另起一个goroutine来获取结果,然而containerd在调用runc去真正执行删除的时候因为容器内D进程 或者 Z进程,无法删除容器,导致没有发出task exit信号,dockerd的两个相关的goroutine也就不会退出。
整个过程不断重复,最终就导致fd、内存、goroutine一步步的泄露,系统逐渐走向不可用。
5.1 触发条件
由于Pod中容器容器内D进程 或者 Z进程,无法删除容器。
5.2 根本原因
由于Docker server版本有没有设置gorounte timeout,导致gorounte挂起, 从而导致fd、内存泄漏
社区目前以及修复:
https://github.com/moby/moby/pull/42956
5.3 引起的容器
本环境中由于fluentd pod异常导致
从ContainerID a9acd5210705 跟踪关联Kubelet日志信息
May 1 10:47:56 ecs-prod-003 kubelet: 2023-05-01 10:47:56.381 [INFO][88861] ipam.go 1172: Releasing all IPs with handle 'k8s-pod-network.a9acd5210705c3e2e95ca459d1b244883c0ba2a5ee94650cb2fa23422367e6e9'
May 1 10:47:56 ecs-prod-003 kubelet: 2023-05-01 10:47:56.429 [INFO][88861] ipam_plugin.go 314: Released address using handleID ContainerID="a9acd5210705c3e2e95ca459d1b244883c0ba2a5ee94650cb2fa23422367e6e9" HandleID="k8s-pod-network.a9acd5210705c3e2e95ca459d1b244883c0ba2a5ee94650cb2fa23422367e6e9" Workload="ecs--prod--003-k8s-fluentd--hjj42-eth0"
May 1 10:47:56 ecs-prod-003 kubelet: 2023-05-01 10:47:56.429 [INFO][88861] ipam_plugin.go 323: Releasing address using workloadID ContainerID="a9acd5210705c3e2e95ca459d1b244883c0ba2a5ee94650cb2fa23422367e6e9" HandleID="k8s-pod-network.a9acd5210705c3e2e95ca459d1b244883c0ba2a5ee94650cb2fa23422367e6e9" Workload="ecs--prod--003-k8s-fluentd--hjj42-eth0"
May 1 10:47:56 ecs-prod-003 kubelet: 2023-05-01 10:47:56.433 [INFO][88846] k8s.go 498: Teardown processing complete. ContainerID="a9acd5210705c3e2e95ca459d1b244883c0ba2a5ee94650cb2fa23422367e6e9"
May 1 20:29:34 ecs-prod-003 kubelet: 2023-05-01 20:29:34.865 [INFO][286438] plugin.go 503: Extracted identifiers ContainerID="a9acd5210705c3e2e95ca459d1b244883c0ba2a5ee94650cb2fa23422367e6e9" Node="ecs-prod-003" Orchestrator="k8s" WorkloadEndpoint="ecs--prod--003-k8s-fluentd--hjj42-eth0"
May 1 20:29:34 ecs-prod-003 kubelet: 2023-05-01 20:29:34.874 [INFO][286438] k8s.go 473: Endpoint deletion will be handled by Kubernetes deletion of the Pod. ContainerID="a9acd5210705c3e2e95ca459d1b244883c0ba2a5ee94650cb2fa23422367e6e9" endpoint=&v3.WorkloadEndpoint{
TypeMeta:v1.TypeMeta{
Kind:"WorkloadEndpoint", APIVersion:"projectcalico.org/v3"}, ObjectMeta:v1.ObjectMeta{
Name:"ecs--prod--003-k8s-fluentd--hjj42-eth0", GenerateName:"fluentd-", Namespace:"kube-system", SelfLink:"", UID:"d6097c23-9b88-4708-93e0-226bb313e7f3", ResourceVersion:"99857676", Generation:0, CreationTimestamp:v1.Time{
Time:time.Time{
wall:0x0, ext:63802199288, loc:(*time.Location)(0x29ce720)}}, DeletionTimestamp:(*v1.Time)(nil), DeletionGracePeriodSeconds:(*int64)(nil), Labels:map[string]string{
"controller-revision-hash":"86b64f7748", "k8s-app":"fluentd-logging", "pod-template-generation":"1", "projectcalico.org/namespace":"kube-system", "projectcalico.org/orchestrator":"k8s", "projectcalico.org/serviceaccount":"fluentd", "version":"v1"}, Annotations:map[string]string(nil), OwnerReferences:[]v1.OwnerReference(nil), Finalizers:[]string(nil), ClusterName:"", ManagedFields:[]v1.ManagedFieldsEntry(nil)}, Spec:v3.WorkloadEndpointSpec{
Orchestrator:"k8s", Workload:"", Node:"ecs-prod-003", ContainerID:"", Pod:"fluentd-hjj42", Endpoint:"eth0", IPNetworks:[]string{
"172.20.83.196/32"}, IPNATs:[]v3.IPNAT(nil), IPv4Gateway:"", IPv6Gateway:"", Profiles:[]string{
"kns.kube-system", "ksa.kube-system.fluentd"}, InterfaceName:"cali843ab5e3ccd", MAC:"", Ports:[]v3.EndpointPort(nil)}}
May 1 20:29:34 ecs-prod-003 kubelet: 2023-05-01 20:29:34.874 [INFO][286438] k8s.go 485: Cleaning up netns ContainerID="a9acd5210705c3e2e95ca459d1b244883c0ba2a5ee94650cb2fa23422367e6e9"
May 1 20:29:34 ecs-prod-003 kubelet: 2023-05-01 20:29:34.874 [INFO][286438] linux_dataplane.go 457: veth does not exist, no need to clean up. ContainerID="a9acd5210705c3e2e95ca459d1b244883c0ba2a5ee94650cb2fa23422367e6e9" ifName="eth0"
May 1 20:29:34 ecs-prod-003 kubelet: 2023-05-01 20:29:34.874 [INFO][286438] k8s.go 492: Releasing IP address(es) ContainerID="a9acd5210705c3e2e95ca459d1b244883c0ba2a5ee94650cb2fa23422367e6e9"
May 1 20:29:34 ecs-prod-003 kubelet: 2023-05-01 20:29:34.874 [INFO][286438] utils.go 168: Calico CNI releasing IP address ContainerID="a9acd5210705c3e2e95ca459d1b244883c0ba2a5ee94650cb2fa23422367e6e9"
May 1 20:29:34 ecs-prod-003 kubelet: 2023-05-01 20:29:34.895 [INFO][286452] ipam_plugin.go 302: Releasing address using handleID ContainerID="a9acd5210705c3e2e95ca459d1b244883c0ba2a5ee94650cb2fa23422367e6e9" HandleID="k8s-pod-network.a9acd5210705c3e2e95ca459d1b244883c0ba2a5ee94650cb2fa23422367e6e9" Workload="ecs--prod--003-k8s-fluentd--hjj42-eth0"
May 1 20:29:34 ecs-prod-003 kubelet: 2023-05-01 20:29:34.895 [INFO][286452] ipam.go 1172: Releasing all IPs with handle 'k8s-pod-network.a9acd5210705c3e2e95ca459d1b244883c0ba2a5ee94650cb2fa23422367e6e9'
May 1 20:29:34 ecs-prod-003 kubelet: 2023-05-01 20:29:34.903 [WARNING][286452] ipam_plugin.go 312: Asked to release address but it doesn't exist. Ignoring ContainerID="a9acd5210705c3e2e95ca459d1b244883c0ba2a5ee94650cb2fa23422367e6e9" HandleID="k8s-pod-network.a9acd5210705c3e2e95ca459d1b244883c0ba2a5ee94650cb2fa23422367e6e9" Workload="ecs--prod--003-k8s-fluentd--hjj42-eth0"
May 1 20:29:34 ecs-prod-003 kubelet: 2023-05-01 20:29:34.903 [INFO][286452] ipam_plugin.go 323: Releasing address using workloadID ContainerID="a9acd5210705c3e2e95ca459d1b244883c0ba2a5ee94650cb2fa23422367e6e9" HandleID="k8s-pod-network.a9acd5210705c3e2e95ca459d1b244883c0ba2a5ee94650cb2fa23422367e6e9" Workload="ecs--prod--003-k8s-fluentd--hjj42-eth0"
May 1 20:29:34 ecs-prod-003 kubelet: 2023-05-01 20:29:34.907 [INFO][286438] k8s.go 498: Teardown processing complete. ContainerID="a9acd5210705c3e2e95ca459d1b244883c0ba2a5ee94650cb2fa23422367e6e9"
[root@ecs-prod-003 /var/log]# grep "kubelet" /var/log/messages-20230507 |grep "fef3e1fbee14"
May 1 11:03:56 ecs-prod-003 kubelet: E0501 11:03:37.635343 4568 remote_runtime.go:276] "StopContainer from runtime service failed" err="rpc error: code = DeadlineExceeded desc = context deadline exceeded" containerID="fef3e1fbee146788d1557ec20204e10922eeb2607969a26d1323588cc8a7f469"
May 1 11:04:00 ecs-prod-003 kubelet: E0501 11:03:37.635447 4568 kuberuntime_container.go:666] "Container termination failed with gracePeriod" err="rpc error: code = DeadlineExceeded desc = context deadline exceeded" pod="kube-system/fluentd-hjj42" podUID=d6097c23-9b88-4708-93e0-226bb313e7f3 containerName="fluentd" containerID="docker://fef3e1fbee146788d1557ec20204e10922eeb2607969a26d1323588cc8a7f469" gracePeriod=5
May 1 11:04:01 ecs-prod-003 kubelet: E0501 11:03:37.635513 4568 kuberuntime_container.go:691] "Kill container failed" err="rpc error: code = DeadlineExceeded desc = context deadline exceeded" pod="kube-system/fluentd-hjj42" podUID=d6097c23-9b88-4708-93e0-226bb313e7f3 containerName="fluentd" containerID={
Type:docker ID:fef3e1fbee146788d1557ec20204e10922eeb2607969a26d1323588cc8a7f469}
May 1 11:13:56 ecs-prod-003 kubelet: E0501 11:13:56.984106 4568 remote_runtime.go:276] "StopContainer from runtime service failed" err="rpc error: code = Unknown desc = operation timeout: context deadline exceeded" containerID="fef3e1fbee146788d1557ec20204e10922eeb2607969a26d1323588cc8a7f469"
May 1 11:13:56 ecs-prod-003 kubelet: E0501 11:13:56.985104 4568 kuberuntime_container.go:666] "Container termination failed with gracePeriod" err="rpc error: code = Unknown desc = operation timeout: context deadline exceeded" pod="kube-system/fluentd-hjj42" podUID=d6097c23-9b88-4708-93e0-226bb313e7f3 containerName="fluentd" containerID="docker://fef3e1fbee146788d1557ec20204e10922eeb2607969a26d1323588cc8a7f469" gracePeriod=5
May 1 11:13:56 ecs-prod-003 kubelet: E0501 11:13:56.985160 4568 kuberuntime_container.go:691] "Kill container failed" err="rpc error: code = Unknown desc = operation timeout: context deadline exceeded" pod="kube-system/fluentd-hjj42" podUID=d6097c23-9b88-4708-93e0-226bb313e7f3 containerName="fluentd" containerID={
Type:docker ID:fef3e1fbee146788d1557ec20204e10922eeb2607969a26d1323588cc8a7f469}
May 1 23:37:46 ecs-prod-003 kubelet: I0501 23:37:46.243371 285578 scope.go:111] "RemoveContainer" containerID="fef3e1fbee146788d1557ec20204e10922eeb2607969a26d1323588cc8a7f469"
6. 修复方式
此问题修复方式:https://github.com/moby/moby/pull/42956
落地版本在: v20.10.10
7. 最佳方式:
短期方式
如果用户系统要求,不能更新docker版本,可通过内部优雅重启方式
{
"log-driver": "json-file",
"log-opts": {
"max-size": "50m",
"max-file": "5"
},
"oom-score-adjust": -1000,
"registry-mirrors": ["https://xxxxx"],
"storage-driver": "overlay2",
"storage-opts":["overlay2.override_kernel_check=true"],
"live-restore": true
}
live-restore: true 和 oom-score-adjust: -1000 将被oomkill调整权限最高,如果发生以上问题,可优雅重启
长期方式
性能相关:
- 升级golang编译编译到1.16+,支持内存快速回收, 使用
MADV_DONTNEED代替MADV_FREE做操作系统回收内存: golang/@05e6d28 - docker log 流处理问题修复: https://github.com/moby/moby/pull/40796
- docker logger reade length: https://github.com/moby/moby/pull/43165
- docker high log output container oom: https://github.com/moby/moby/issues/42125
升级版本到 v20.10.14+

