文章和代码已经归档至【Github仓库:https://github.com/timerring/dive-into-AI 】或者公众号【AIShareLab】回复 神经网络基础 也可获取。
CNN
卷积神经网络发展史
卷积神经网络(convolutional neural networks, CNN )
CNN 是针对图像领域任务提出的神经网络,经历数代人的发展,在2012年之后大部分图像任务被CNN统治,例如图像分类,图像分割,目标检测,图像检索等。

CNN结构受视觉系统启发:1962 年,生物学家Torsten WieseI 和 David H. Hubel(1981年的诺贝尔医学奖)对猫的视觉系统进行研究,首次发现猫的视觉系统中存在层级机构,并且发现了两种重要的细胞 simple cells 和 compIex cells,不同类型细胞承担不同抽象层次的视觉感知功能。
猫的视觉系统实验
- 在猫脑上打开 3mm, 插入电极
- 让猫看各种形状、位置、亮度和运动的光条
- 观察大脑视觉神经元激活情况

神经元存在局部感受区域 ( receptive field),也称感受野
细胞感受区域存在差异:如C细胞和D细胞相反(图中X表示有响应,三角表示无响应)

细胞对角度有选择性。如图所示的该细胞对垂直光条响应最强。

细胞对运动方向有选择性(如图,a种方式感应更加强烈)

对CNN启发:
- 视觉系统是分层、分级的进行处理,从低级到高级的抽象过$\to$类比堆叠使用卷积和池化
- 神经元实际上是存在局部的感受区域的,具体来说,它们是局部敏感$\to$类比神经元局部连接
第一个卷积神经网络雏形——新认知机(Neocognitron)
1980 年,日本学者福岛邦彦(Kunihiko Fukushima) 借鉴猫视觉系统实验结论,提出具有层级结构的神经网络一一新认知机,堆叠使用类似于S细胞和C细胞的两个结构。S细胞和 C 细胞可类比现代CNN的卷积和池化。
缺点: 没有反向传播算法更新权值,模型性能有限。

福岛邦彦主页 :http://personalpage.flsi.or.jp/fukushima/index-e.html
第一个大规模商用卷积神经网络——Lenet-5
1989 年,Lecun 等人已开始研究Lenet;1998 年,Lecun等人提出Lenet-5,并成功在美国邮政系统中大规模应用于手写邮政编码识别
缺点:无大量数据和高性能计算资源

第一个技惊四座的卷积神经网络——AlexNet
2012年,AlexNet以超出第二名10.9个百分点的成绩夺得ILSVRC分类任务冠军,从此拉开卷积神经网络通知图像领域序幕。
- 算料:ImageNet
- 算力:GPU(GTX580 * 2)
- 算法:AlexNet

卷积操作
卷积层(Convolutional Layer)
图像识别特点:
- 特征具有局部性:例如老虎重要特征“王字”仅出现在头部区域 —— 卷积核每次仅连接K*K区域,K*K是卷积核尺寸;

- 特征可能出现在任何位置——卷积核参数重复使用(参数共享),在图像上滑动(示例图像来源:https://github.com/vdumoulin/conv_arithmetic)
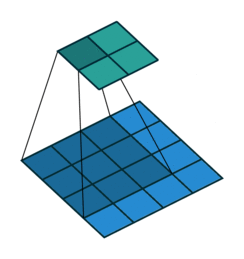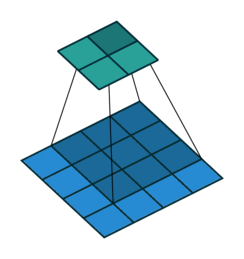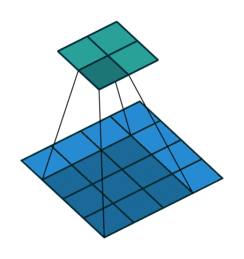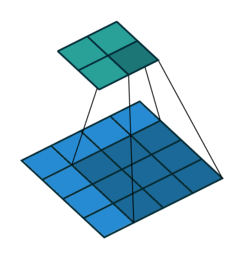

0×0+1x1+3×2+4×3 =19
- 下采样图像,不会改变图像目标
卷积核
卷积核:具可学习参数的算子,用于对输入图像进行特征提取,输出通常称为特征图(feature maps)。

具体的过程可以根据实际情况模拟以下,例如第一个边缘检测的卷积核,如果一个像素差别不大的图像,经过该卷积核卷积过程后,大概率是中间的8份额减去旁边的8个1份额,最后为0,显示为黑色。如果存在边缘非常明显的部分,经过减少之后数值仍然较大,显示为白色,因此可以形成边缘的轮廓。
2012年AlexNet网络第一个卷积层卷积核可视化,卷积核呈现边缘、频率和色彩上的特征模式。
填充 (Padding):在输入图像的周围添加额外的行/列
作用:
- 使卷积后图像分辨率不变,方便计算特征图尺寸的变化
- 弥补边界信息“丢失"
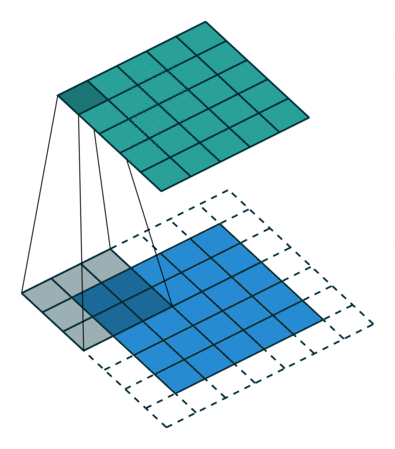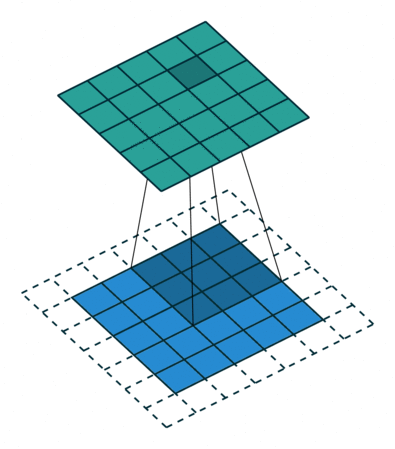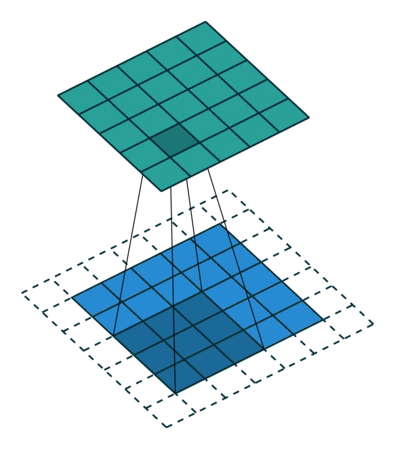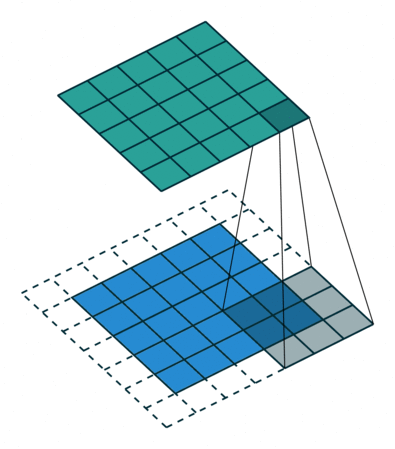

步幅(Stride) :卷积核滑动的行数和列数称为步幅,控制输出特征图的大小,会被缩小1/s倍。
卷积会向下取整,到边界不满足信息的话,会向下取整。(即使存在边缘信息,但是如果不满足步幅,也会舍弃)
输出特征图尺寸计算:
$$ \mathrm{F}_{\mathrm{o}}=\left[\frac{\mathrm{F}_{\text {in }}-\mathrm{k}+2 \mathrm{p}}{\mathrm{s}}\right]+1 $$
$$ > \frac{[4-3+2 * 0]}{1}+1=2 > $$
$$ > \frac{[6-3+2 * 1]}{2}+1=3 > $$
$$ > \frac{[5-3+2 * 1]}{1}+1=5 > $$
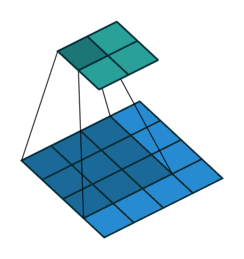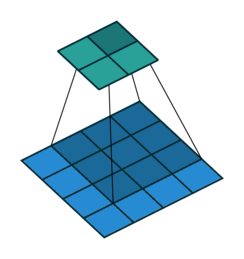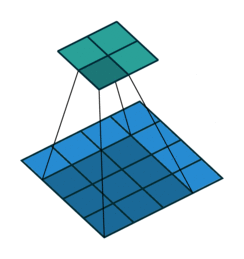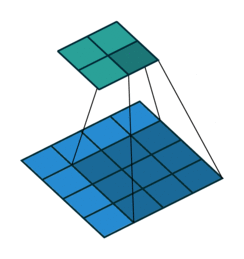
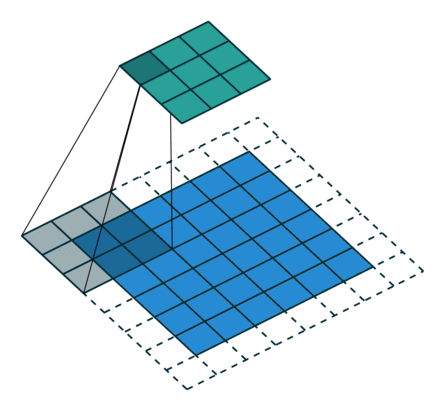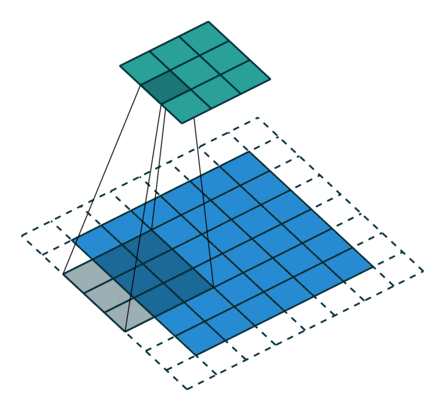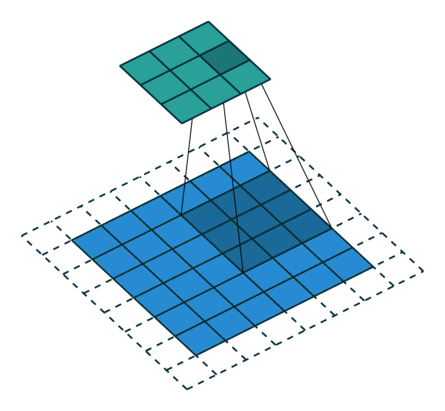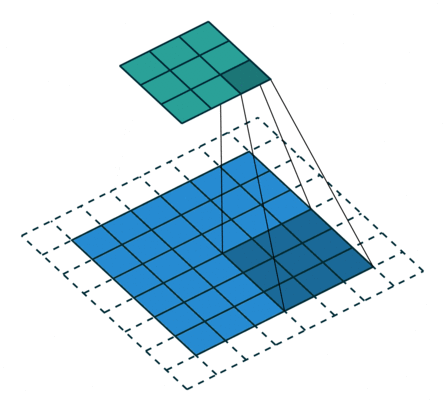
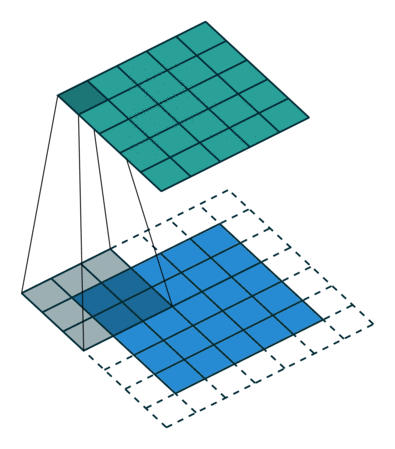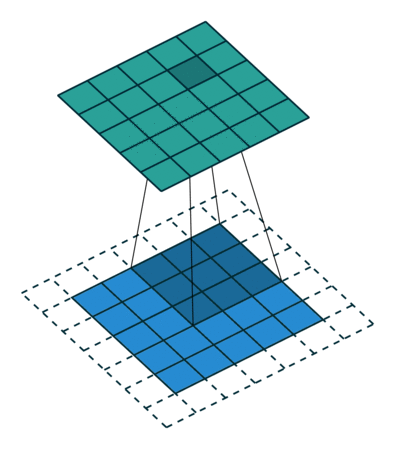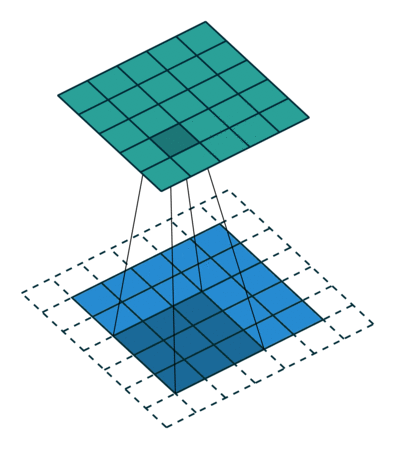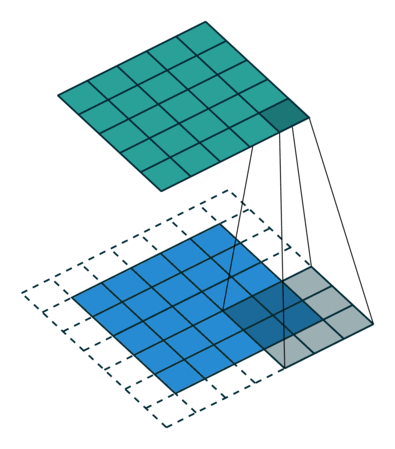
多通道卷积 : RGB图像是3*h*w的三维的数据,第一个维度3,表示channel,通道数
一个卷积核是3-D张量,第一个维与输入通道有关
注:卷积核尺寸通常指高、宽


如上,卷积核的规模为2x3x3x3。本质上还是一个二维卷积。
池化操作
图像识别特点
- 下采样图像,不会改变图像目标——降低计算量,减少特征冗余
池化:一个像素表示一块区域的像素值,降低图像分辨率
一块区域像素如何被一个像素代替:
- 方法1: Max Pooling,取最大值
- 方法2: Average Pooling,取平均值
现在的模型中很多都不太用池化操作,而采用一个步长为2的卷积代替池化,通过它也可以实现降低图像的分辨率。(池化也可以理解为一种特殊的卷积,例如可以将Max pooling理解为一个最大值权值为1,其他权值为0的卷积核,将Average Pooling理解为一个平均权值的卷积核)。

因此输出尺寸计算与卷积操作类似:(注意:池化层无可学习参数)
$$ \mathrm{F}_{\mathrm{o}}=\left\lfloor\frac{\mathrm{F}_{\text {in }}-\mathrm{k}+2 \mathrm{p}}{\mathrm{s}}\right\rfloor+1 $$
池化作用 :
缓解卷积层对位置的过度敏感

第一行为原矩阵,第二行为卷积后的矩阵,第三行为池化后的矩阵。左右对比可知,添加扰动后卷积结果受到影响,但是池化结果并未受到影响。参考:https://zhuanlan.zhihu.com/p/103350961
减少冗余
降低图像分辨率,从而减少参数量
Lenet-5及CNN结构进化史
1998-Lecun-Gradient-Based Learning Applied to Document Recognition
特征提取器:C1、S2、C3、S4
- C1层: 卷积核K1=(6, 1, 5, 5), p=1, s=1,output=(6, 28, 28)
- S2层: 最大池化层, 池化窗口=(2,2),s=2,output=(6, 14, 14)
- C3层: 卷积核K3=(16, 6, 5, 5), p=1, s=1,output=(16, 10, 10)
- S4层: 最大池化层, 池化窗口=(2,2),s=2,output=(16, 5, 5)
分类器:3个FC层
- FC层: 3个FC层输出分类

CNN进化史
- 1980 Neocognition 福岛邦彦
- 1998 Lenet-5 Lecun
- 2012 AlexNet Alex
- 2014 GoogLenet Google
- 2014 VGG-Net VGG
- 2015 ResNet Kaiming He
- 2017 DenseNet Gao Huang
- 2017 SE-Net Jie Hu
参考
所有卷积示例图像的来源:https://github.com/vdumoulin/conv_arithmetic

