
一 前言
在一些电商的小程序项目中,长列表是一个很普遍的场景,在加载大量的列表数据的过程中,可能会遇到手机卡顿,白屏等问题。也许数据进行分页处理可以防止一次性加载数据带来的性能影响,但是随着数据量越来越大,还是会让小程序应用越来越卡顿,响应速度越来越慢。这种问题不仅仅在小程序上,在移动端 h5 项目中同样存在。
这个时候就需要优化长列表,今天将一起讨论一下,长列表的优化方案及其实践。
二 小程序长列表性能瓶颈
影响小程序长列表性能的因素有很多。我们先分析一下小程序长列表的性能卡点是什么?
元素节点限制:一个太大的 WXML 节点树会增加内存的使用,样式重排时间也会更长,影响体验。微信小程序官方建议一个页面 WXML 节点数量应少于 1000 个,节点树深度少于 30 层,子节点数不大于 60 个。这种现象的本质原因是每次 setData 都需要创建新的虚拟树、和旧树 diff 操作耗时都比较高。
图片性能和内存的影响:长列表的情况一般会有大量的图片,内存占用增长,长列表中的大量图片会导致内存占用急剧上升,内存增长如果超过了限制,也会导致小程序出现白屏或黑屏,甚至整个小程序发生闪退。
setData 频率以及数据量的影响,长列表的情况下,会有很多列表单元项,如果每个 item 内部会触发 setData,会造成 setData 的频率急速上升;并且在向每一个 item 注入数据的时候,会造成数据量传输过大,这也是一种性能的开销。而且如果在首次渲染过程中,加载大量的数据,就会造成,首次 setData 的时候耗时高。
那么上述有一个问题,为什么向 item 注入数据会影响性能呢?这些主要是因为小程序的设计。
整个小程序框架系统分为两部分:逻辑层(App Service)和 视图层(View)。小程序提供了自己的视图层描述语言 WXML 和 WXSS,以及基于 JavaScript 的逻辑层框架,并在视图层与逻辑层间提供了数据传输和事件系统,让开发者能够专注于数据与逻辑。

但是当外层向每一个 Item 注入数据的时候,本质上是外层逻辑层注入数据到视图层,再从视图层传输到 item 组件的逻辑层。如下图所示。

解决方案:
那么如上是造成长列表性能瓶颈的原因,那么解决手段是什么呢?
无论是上述那种性能卡点,本质上原因就是 Item 的数量过多导致的,在小程序和移动端 h5 上,由于滑动加载,会导致数据量越来越大,item 越来越多,所以 控制 item 数量 是解决问题的关键。
三 传统优化方案
通过上面我们知道了,解决长列表的手段本身就是控制 item 的数量,原理就是当数据填充的时候,理论上数据是越来越多的,但是可以通过手段,让视图上的 item 渲染,而不在视图范围内的数据不需要渲染,那就不去渲染,这样的好处有:
由于只渲染视图部分,那么非视图部分,不需要渲染,或者只放一个 skeleton 骨架元素展位就可以了,首先这大大减少了元素的数量,也减少了图片的数量,直接减少了应用占用的内存量,减少了白屏的情况发生。
由于 item 数量减少了,减少 diff 对比的数量,提升了对比的效率。
- 如果 item 里面还有 setData 的操作,那么有间接性的减少 setData 的数量,以及数据的传输量。
明白了基本原理之后,接下来看一下具体的实现方案。
1 基于 scroll-view 计算
让视图区域的 item 真实的渲染,这是长列表优化的主要手段,那么第一个问题就是如何知道哪些 item 在可视区域内? 正常情况下,当在移动端滑动设备的时候,只有手机屏幕内可视区域是真正需要渲染的部分,如下所示:

那就首先就要知道哪些 item 在屏幕区域内,一般情况下,这种长列表都是基于 scroll-view 实现的,scroll-view 提供了很多回调函数可以处理滚动期间发生的事件。比如 scroll,scrolltoupper,scrolltolower 等。
在 scroll 滑动过程中,可以通过 srollTop 和 scroll-view 的高度,以及每一个 item 的高度,来计算哪些 item 是在视图范围内的。
下面我们来简单的计算一下,在视图区域内的 item 的索引:
- startIndex:为在视图区域内的起始索引。
- endIndex:为在视图区域内的末尾索引。
那么计算流程如下所示:

- 通过 scrollTop 和每个 item 的高度 itemHeight 计算起始索引 startIndex。
- 再通过 startIndex 和容器高度 height 计算出末尾索引 endIndex。
那么处于 startIndex 和 endIndex 的 item 就是在视图区域的 item 。那么通过 slice 截取到列表就是需要渲染的内容。
this.setData({
renderList:this.data.dataList.slice(startIndex,endIndex)
})
但是如果只让视图中的 item 进行渲染,那么其他 item 的地方如何处理呢,因为我们需要 scroll-view 构造出真实滑动到当前位置的效果。这个时候为了创建出 scroll-view 真实的滑动效果,不需要渲染数据的地方可以用一个空的元素占位。
缓冲区
但是正常情况下,不会直接将 startIndex 和 endIndex 作为真正渲染的内容。因为滑动的速度是快速的,以竖直方向上的滑动为例子,如果快速上滑或者下滑过程中,需要触发 setData 改变渲染的内容,那么更新不及时的情况下,不会让用户看到真实的列表内容,这样就会造成一个极差的用户体验。
为了解决这个问题,引出了一个上下缓冲的概念,就是在渲染真实的列表 item 的时候,在滑动的两个边界加上一定的缓冲区,在缓冲区的 item 也会正常渲染。
还是以上下滑动为例子,我们来看一下,缓冲区是如何定义的。
- 比如在视图区域的 item 的起始索引为 startIndex,那么如果留一定缓冲区的话,那么起始索引就变成了,startIndex - bufferCount(这里直接认为 startIndex > bufferCount 的前提下)。
- 同理视图区域 item 的末尾索引为 endIndex,那么需要在 endIndex 基础上加上缓冲区,所以就变成了 endIndex + bufferCount 。
所以 [ startIndex - bufferCount , endIndex + bufferCount ] 为真正的渲染区间,在这个区间内部的 item 都会真实的渲染。
如下图,我们来看一下在滑动过程中,渲染区间的变化情况:

对于 bufferCount ,总结好处有以下二点:
- 缓冲区从本质上防止在快速上滑或者下滑过程中,setData 更新数据不及时,带来不友好的视觉效果。
- 有了 bufferCount ,可以让滑动到达一定长度再进行重新计算渲染边界,这样有效的得减少了滑动过程中 setData 的频率。bufferCount 缓冲数量越大,那么 setData 频率就会越小,但是如果 bufferCount 过大,就违背了虚拟列表的初衷—减少元素数量,所以开发者需要合理的控制 bufferCount 的大小,正常情况下,屏幕的一屏或者两屏为宜。
2 基于 observer 处理
小程序提供了 createIntersectionObserver 接口,可以创建 IntersectionObserver 对象来判断元素是否在可视区域内。
这个 api 一般用于判断曝光埋点,微信官方建议使用节点布局相交状态监听 IntersectionObserver 推断某些节点是否可见、有多大比例可见;
先来看一下这个方法的基础方法:
createIntersectionObserver 创建并返回一个 IntersectionObserver 对象实例。在自定义组件或包含自定义组件的页面中,应使用 this.createIntersectionObserver([options]) 来代替。接下来看一下 IntersectionObserver 对象上有哪些方法。
IntersectionObserver.relativeTo(string selector, Object margins)
使用选择器指定一个节点,作为参照区域之一。IntersectionObserver.relativeToViewport(Object margins)
指定页面显示区域作为参照区域之一。IntersectionObserver.observe(string targetSelector, IntersectionObserver.observeCallback callback)
指定目标节点并开始监听相交状态变化情况。IntersectionObserver.disconnect()
停止监听。回调函数将不再触发。
基础使用:
wxml中:
<!--index.wxml-->
<view class="container">
<view class="usermotto" />
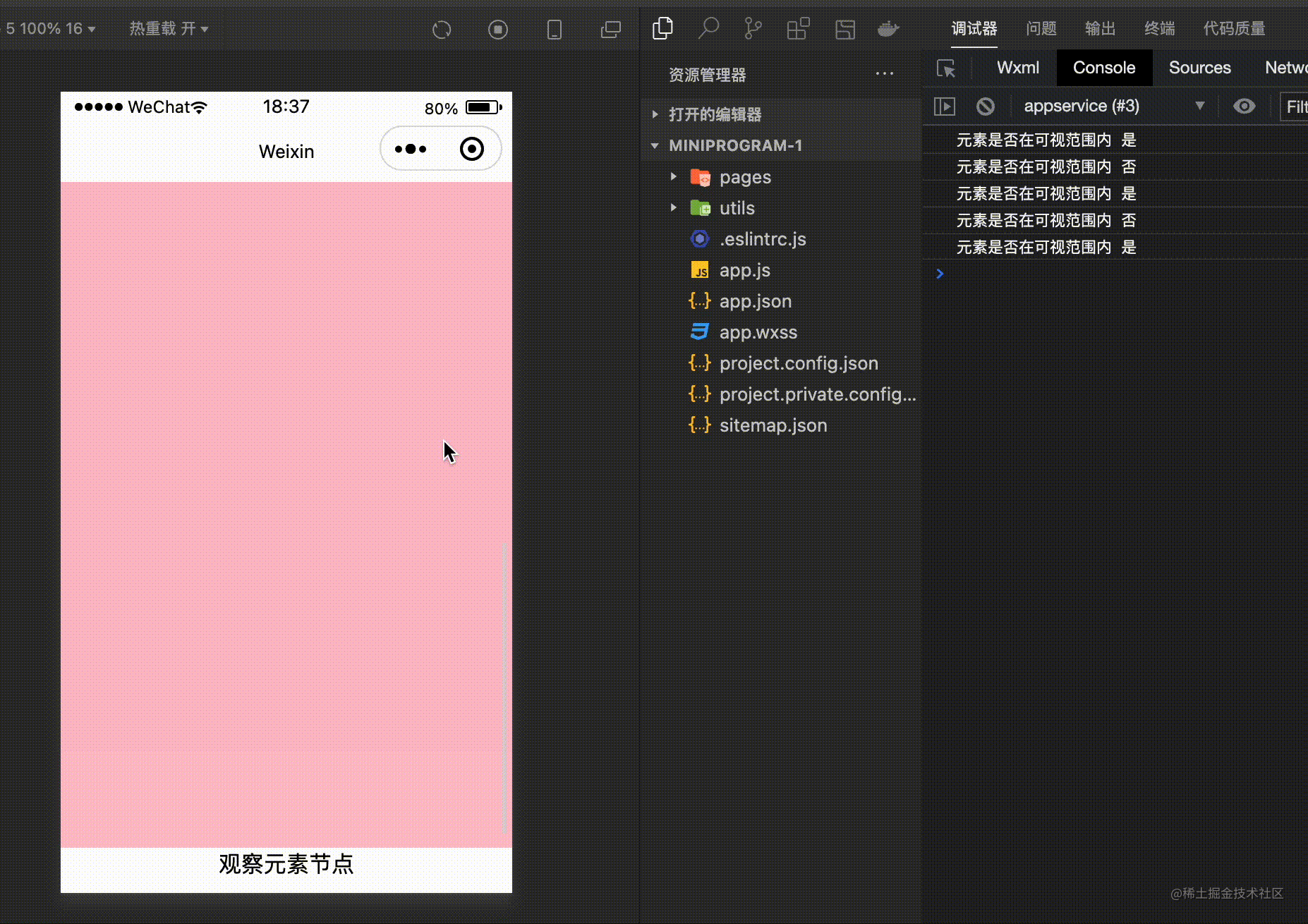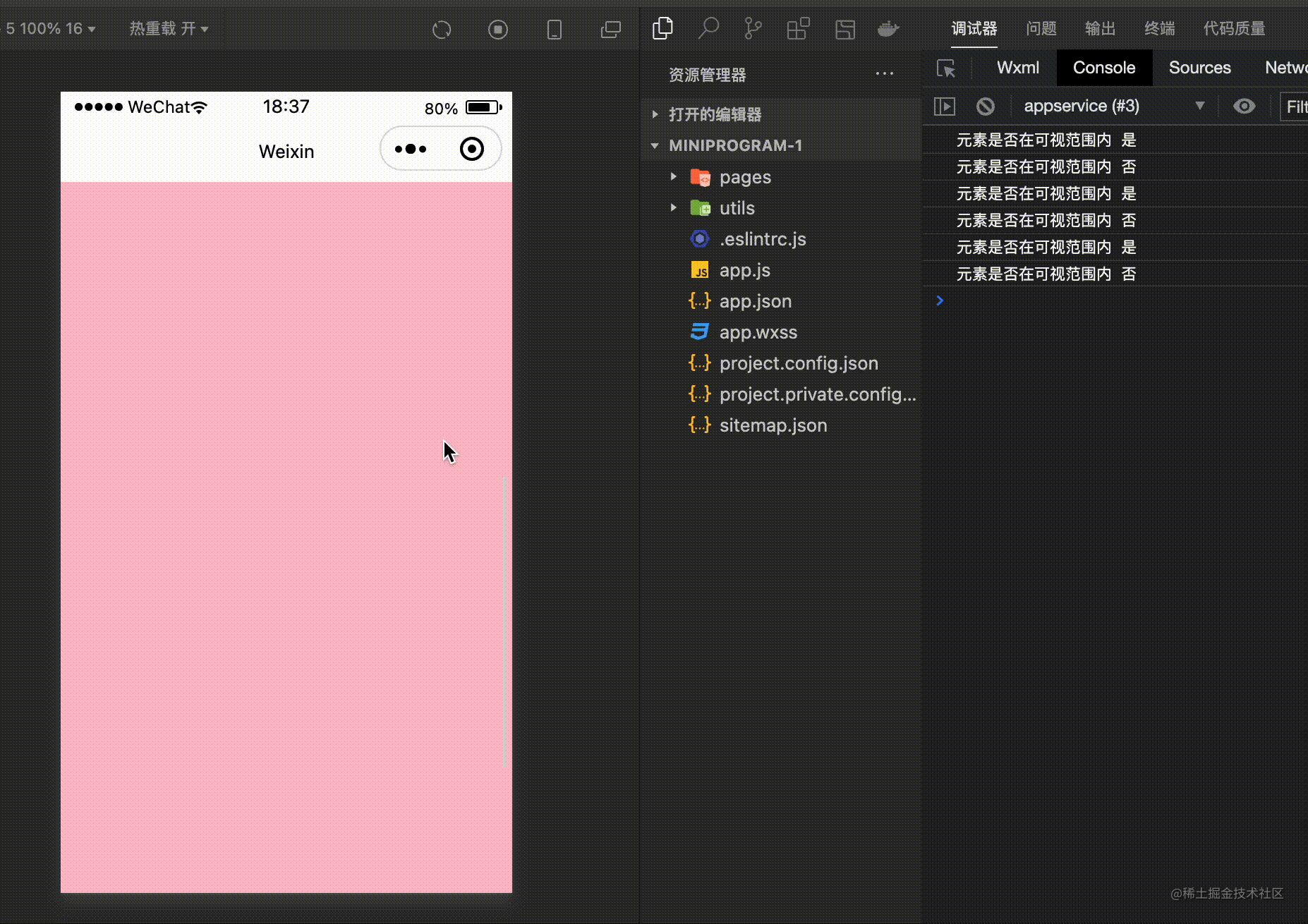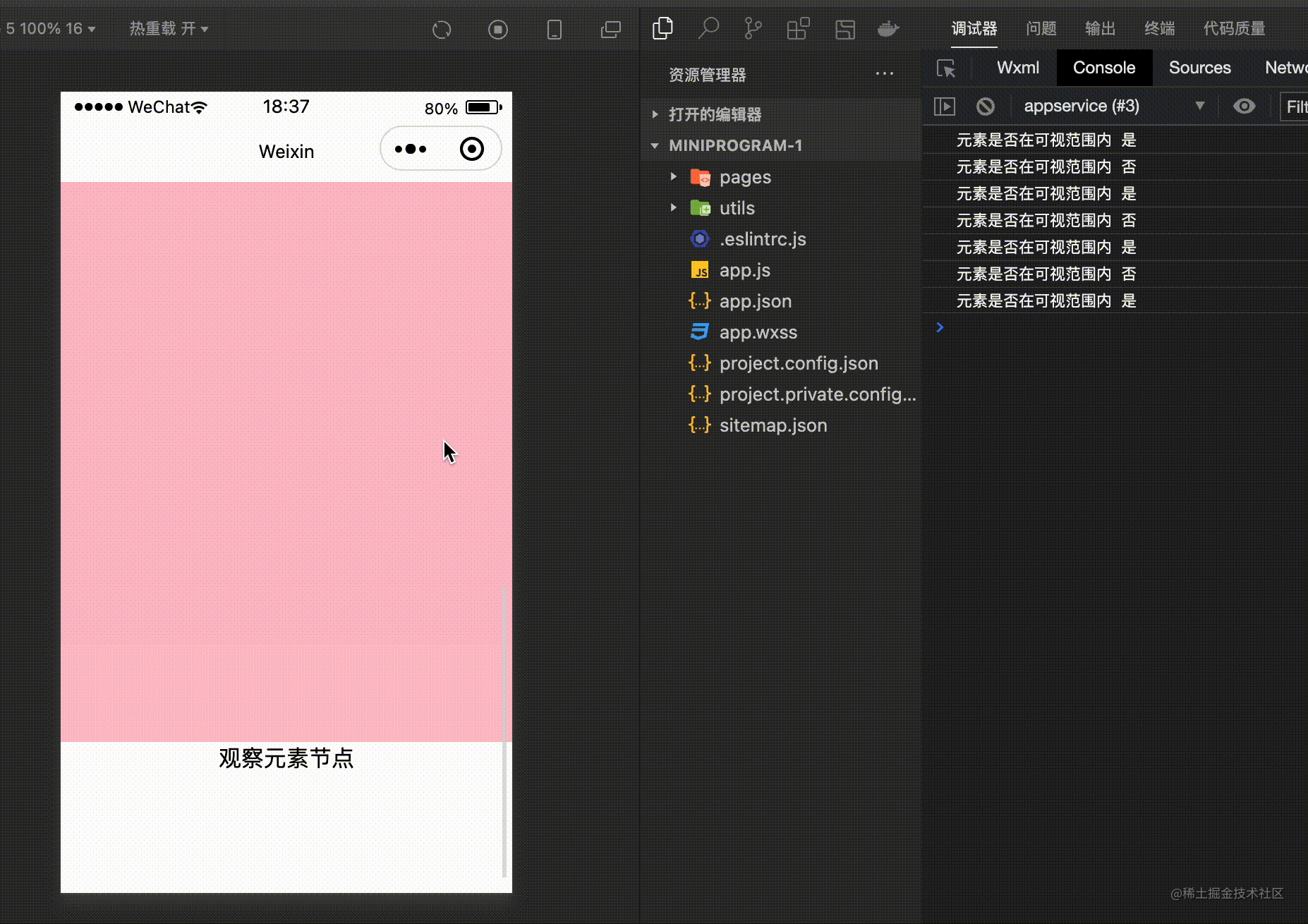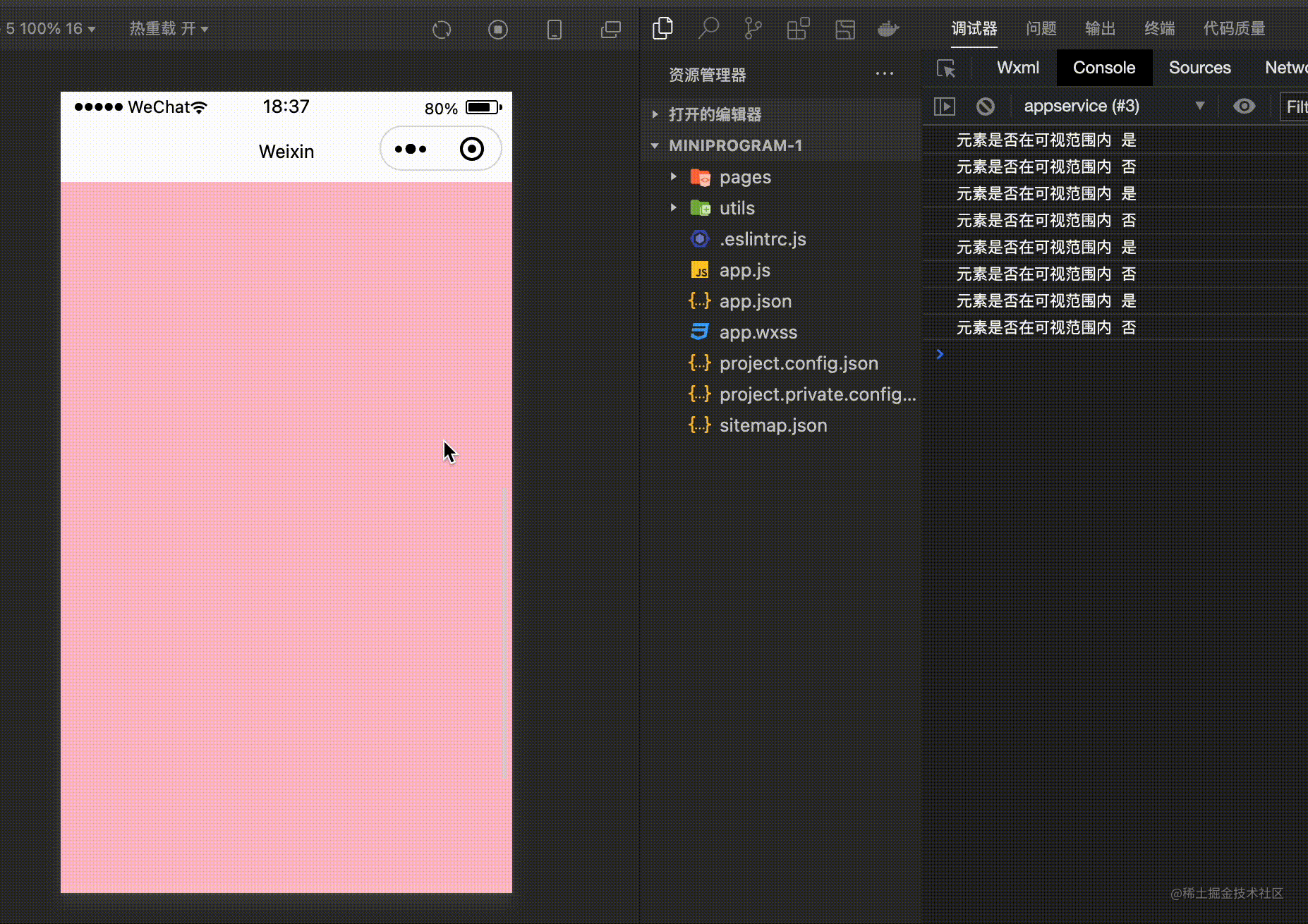
<view id="currentView" >观察元素节点</view>
</view>
js中:
Page({
onLoad() {
const Observer = wx.createIntersectionObserver(this)
Observer.relativeToViewport({
top: 0, // 当元素到达顶部触发回调事件
bottom:0, // 当元素到达底部触发回调事件
}).observe('#currentView',(res)=>{
console.log('元素是否在可视范围内',res.intersectionRatio <= 0 ? '否' : '是' )
})
},
})
如上通过 IntersectionObserver 对象来监听元素的位置,然后可以通过 res.intersectionRatio 判断元素是否在指定的区域内部。
实现原理:
那么这个方法,既然能判断元素的曝光,那么也可以用来做长列表优化使用。它的实现原理如下所示:

这种方式可以把数据进行分组,然后每组创建一个 IntersectionObserver ,当分组处于视图区域内的时候,才渲染本分组的数据,那么其他分组没有在视图范围内,所以不需要渲染真实的元素,只需要渲染占位元素或者是骨架节点就可以了。
缓冲距离:
这种实现方案也会存在相同的问题,就是在快速滑动过程中,如果只选择上下边界 top:0 和 bottom:0 ,那么也会造成滑动时候,渲染不及时导致无法看到正常的列表元素的情况发生。
为了解决这个问题,那么也会设置一定的缓冲距离,这个一般会在边界处入手。比如我们可以设置当列表分组在距离屏幕上边界和下边界一屏距离的时候就触发事件,渲染真实的元素。
wx.getSystemInfo({
success: (res) => {
const {
windowHeight } = res
const Observer = wx.createIntersectionObserver(this)
Observer.relativeToViewport({
top: windowHeight, // 距离屏幕顶部一屏距离
bottom:windowHeight,// 距离屏幕底部一屏距离
}).observe('#xxx',(res)=>{
//...
this.setData({
// ...选择渲染的列表
})
})
},
});
如上面所示,通过 getSystemInfo 获取屏幕高度 windowHeight,然后设置 top ,bottom 为屏幕高度,这样当列表分组处于距离屏幕顶部一屏距离和屏幕底部一屏距离都会触发事件,然后就可以通过 intersectionRatio 判断当前列表分组是消失在视图区域,还是进入到视图区域。
实现的原理图如下:

3 经典落地方案
长列表解决方案目前已经非常成熟了,有很多解决思路,但是本质上都是大相径庭的。这里介绍两种能够在实际开发中落地的技术方案。
- 微信小程序官方 recycle-view 方案。
- Taro 的虚拟列表方案。
微信 recycle-view 方案
对于长列表方案,微信官方有一套自己的解决方案,就是 recycle-view 。
核心的思路就是只渲染显示在屏幕的数据,基本实现就是监听 scroll 事件,并且重新计算需要渲染的数据,不需要渲染的数据留一个空的 div 占位元素。
滚动过程中,重新渲染数据的同时,需要设置当前数据的前后的 div 占位元素高度,同时是指在同一个渲染周期内。。
在滚动过程中,为了避免频繁出现白屏,会多渲染当前屏幕的前后2个屏幕的内容。
长列表组件由2个自定义组件 recycle-view、recycle-item 和一组 API 组成,对应的代码结构如下
├── miniprogram-recycle-view/
└── recycle-view 组件
└── recycle-item 组件
└── index.js
包结构详细描述如下:
| 目录/文件 | 描述 |
|---|---|
| recycle-view 组件 | 长列表组件 |
| recycle-item 组件 | 长列表每一项 item 组件 |
| index.js | 提供操作长列表数据的API |
来看一下具体的使用:
-
- 安装组件
npm install --save miniprogram-recycle-view
-
在页面的 json 配置文件中添加 recycle-view 和 recycle-item 自定义组件的配置
{ "usingComponents": { "recycle-view": "miniprogram-recycle-view/recycle-view", "recycle-item": "miniprogram-recycle-view/recycle-item" } }
-
WXML 文件中引用 recycle-view
<recycle-view batch="{ {batchSetRecycleData}}" id="recycleId"> <view slot="before">长列表前面的内容</view> <recycle-item wx:for="{ {recycleList}}" wx:key="id"> <view> <image style='width:80px;height:80px;float:left;' src="{ {item.image_url}}"></image> { {item.idx+1}}. { {item.title}} </view> </recycle-item> <view slot="after">长列表后面的内容</view> </recycle-view>
-
页面 JS 管理 recycle-view 的数据
const createRecycleContext = require('miniprogram-recycle-view') Page({ onReady: function() { var ctx = createRecycleContext({ id: 'recycleId', dataKey: 'recycleList', page: this, itemSize: { // 这个参数也可以直接传下面定义的this.itemSizeFunc函数 width: 162, height: 182 } }) ctx.append(newList) // ctx.update(beginIndex, list) // ctx.destroy() }, itemSizeFunc: function (item, idx) { return { width: 162, height: 182 } } })通过这种的优缺点是显而易见的。首先对于 view 和 item 的结构是清晰的,但是对于数据需要手动通过 ctx.append 进行追加,而且对于整个 recycle-view 和 recycle-item 的处理逻辑是要和业务层耦合在一起的,这种方式对于小程序的开发者有一定技术熟练度的要求。
当然 recycle-view 是基于微信原生小程序实现的,所以可以适用于原生小程序,以及基于原生小程序衍变的其他平台小程序,比如支付宝小程序,美团小程序等。即便是 api 层面不兼容,也可以通过下载改造的方式,来应用到我们的项目中。
Taro 虚拟列表方案
Taro 是多端统一开发的解决方案,可以一套代码运行到移动 web 端,小程序端,React Native 端,Taro 的实现原理也如出一辙,比起全量渲染数据生成的视图,Taro 只渲染当前可视区域(visible viewport)的视图,非可视区域的视图在用户滚动到可视区域再渲染:

如上图就是大致的实现原理。
基本使用:
使用 React/Nerv 我们可以直接从 @tarojs/components/virtual-list 引入虚拟列表(VirtualList)组件:
import VirtualList from '@tarojs/components/virtual-list'
以 Taro React 为例子,接下来看一下 VirtualList 的具体使用:
function buildData (offset = 0) {
return Array(100).fill(0).map((_, i) => i + offset);
}
const Row = React.memo(({
id, index, style, data }) => {
return (
<View id={
id} className={
index % 2 ? 'ListItemOdd' : 'ListItemEven'} style={
style}>
Row {
index} : {
data[index]}
</View>
);
})
export default class Index extends Component {
state = {
data: buildData(0),
}
render() {
const {
data } = this.state
const dataLen = data.length
return (
<VirtualList
height={
500} /* 列表的高度 */
width='100%' /* 列表的宽度 */
itemData={
data} /* 渲染列表的数据 */
itemCount={
dataLen} /* 渲染列表的长度 */
itemSize={
100} /* 列表单项的高度 */
>
{
Row} /* 列表单项组件,这里只能传入一个组件 */
</VirtualList>
);
}
}
VirtualList 的五个属性都是必填项。VirtualList 的数据处理,数据截取,空白填充都是内部实现的,开发者只需要关注将 data 数据注入到 VirtualList 就可以了。这样让虚拟列表使用成本大大降低,也降低了和业务的耦合度。
VirtualList 这种方式是基于 Taro 平台开发的,所以它的使用场景就有一定局限性,开发者只能通过 Taro 中使用,比如一些原生小程序,就很不适用了,即便是想要通过改造源码的方式来让 VirtualList 兼容原生小程序或者其他平台的小程序,成本也是巨大的,无异于重构一下项目。
四 改进版优化方案
接下来我们实现一个长列表组件,选用的是第二种基于 IntersectionObserver 这种方式,我们实现的这个长列表遵循一下原则:
- 和业务低耦合,业务只负责往长列表绑定列表数据就可以了。列表数据是可以追加的。
- 长列表组件提供了两个抽象节点,一个是真实渲染的 item ,一个是占位的 skeleton。
- 除此之外,因为列表一般会有头部和尾部,所以提供两个插槽用于占位使用。分别为列表前的 before,和列表后的 after。
如何使用
业务组件使用:
在正式讲解之前,先来看一下长列表组件是如何使用的:
业务组件 wxml 文件:
<long-list-view
list="{
{list}}"
generic:item="list-item"
generic:skeleton="list-skeleton"
/>
可以看到 long-list-view 的 props 只有三个。
- list 为输入给 long-list-view 的数据源。
- generic:item 为抽象节点,指向了 list-item。
- generic:skeleton 也是抽象节点,指向了 list-skeleton。
我们看一下业务组件的 json 文件:
"usingComponents": {
"list-item":"...", // 业务组件每个卡片组件 item
"list-skeleton":"...", // 当业务组件不渲染时,占位的组件
"long-list-view":"..." // 长列表组件
}
这里引入了一个新的感念—抽象节点。那么我们先来看看什么是抽象节点。
抽象节点
有时,自定义组件模板中的一些节点,其对应的自定义组件不是由自定义组件本身确定的,而是自定义组件的调用者确定的。这时可以把这个节点声明为“抽象节点”。
例如,我们现在来实现一个“选框组”(selectable-group)组件,它其中可以放置单选框(custom-radio)或者复选框(custom-checkbox)。这个组件的 wxml 可以这样编写:
<!-- selectable-group.wxml -->
<view wx:for="{
{labels}}">
<label>
<selectable disabled="{
{false}}"></selectable>
{
{item}}
</label>
</view>
其中,“selectable”不是任何在 json 文件的 usingComponents 字段中声明的组件,而是一个抽象节点。它需要在 componentGenerics 字段中声明:
{
"componentGenerics": {
"selectable": true
}
}
通过上面明白了抽象节点的使用。那么为什么要用抽象节点呢?
- 正常情况下,我们长列表组件是作为公共组件使用的,这时就存在一个问题,我们的 item 组件如果不用抽象节点的情况下,组件 item 是需要注册到长列表组件中去的,那么也就是长列表本身只能服务于这一种场景,和业务强关联到了一起。
- 这里可能有的同学会想到用 slot 插槽解决,但是 slot 作为 item的话,我们是无法去循环 slot 插槽的,但是也并不是不能解决,就像微信官方 recycle-view 一样,可以通过内外层 recycle-view 和 recycle-item 嵌套,然后通过 relations 建立起关联,这样本质上需要维护两个公共组件。
recycle-item
relations: {
'./recycle-view': {
type: 'parent', // 关联的目标节点应为子节点
linked() {
}
}
},
recycle-view
relations: {
'../recycle-item/recycle-item': {
type: 'child', // 关联的目标节点应为子节点
}
}
言归正传,我们主要是通过抽象节点实现的,抽象节点的注册是在业务组件中的,但是使用是在公共组件中的,这样就大大降低和业务组件的耦合程度。
说明白了抽象节点,然后我们来看一下长列表组件结构。
├── long-list-view/
└── index.js
└── index.wxml
└── index.json
└── index.wxss
首先要在 index.json 声明当前组件和抽象节点。
index.json
{
"component": true,
"componentGenerics": {
"item": true, //抽象节点 item
"skeleton": true //抽象节点 skeleton
}
}
接下来就是重点看一下 index.js 。从上面我们知道传入长列表组件中的数据 list ,list 是随着加载数据增多,会越来越多;同时还有有一种情况发生,就是如果 list 变化特别频繁,那么会让长列表一直触发 setData 来执行渲染任务,这样也会造成卡顿的,那么我们长列表需要做的事情是:
- 把 list 规范化,也就是只处理新增的列表数据,将它们按照 observer 分组处理。这样当视图容器滚动的时候,只渲染目标范围内的分组数据。
- 第二点就是对于渲染任务,需要做时间切片处理,防止 list 变化特别频繁,造成一直处于 setData 更新,而使得用户响应比较慢。
时间切片
时间切片的手段通常可以采用 setTimeout 来模拟实现,比如一次性有 50 个 item 需要渲染,那么 list 每次追加 10 个item ,这个时候就会让 setData 在短时间内执行 5 次,并且还要有视图上的响应,这样就会造成性能上和用户体验上的问题。
那么时间切片是如何解决这个问题的呢? 首先每一次渲染会创建一个渲染任务 task,但是并不会立即执行 task,而是把 task 放进一个待渲染的队列 renderPendingQueue 中,然后每次执行队列中的一个任务,当任务执行完毕后,通过 setTimeout 来在下一次的宏任务中再次执行下个更新任务。其原理图如下所示:

下面我们来实现这个功能:
Component({
properties:{
list: {
type: Array,
value: [],
/* 通过 observer 来监听 list 的变化 */
observer(val, preVal) {
if (val.length) {
const cloneVal = val.slice();
/* 找到增量传入的 list */
cloneVal.splice(0, preVal.length);
/* 创建一个渲染任务 */
const task = () => {
/* setList 为真正需要执行的渲染列表的方法 */
this.setList(cloneVal);
};
/* 把渲染任务放入到待渲染队列中 */
this.renderPendingQueue.push(task);
/* 开始执行渲染任务 */
this.runRenderTask();
}
},
},
},
methods:{
/* 更新待渲染对列 */
runRenderTask() {
/* 如果没有渲染任务了,或者渲染任务已经开始,那么直接返回 */
if (this.renderPendingQueue.length === 0 || this.isRenderTask) return;
/* 取出第一个渲染任务 */
const current = this.renderPendingQueue.shift();
/* 开始渲染 */
this.isRenderTask = true;
/* 执行渲染任务 */
typeof current === 'function' && current();
},
},
})
这个的处理逻辑是:
- 首先通过对 props 中的 list 属性进行监听,找到增量传入的 list ,然后创建一个渲染任务,把渲染任务放入到待渲染队列中 ,接下来开始执行渲染任务。
- 在执行更新任务的方法中,如果没有渲染任务了,或者渲染任务已经开始,那么直接返回;反之取出第一个渲染任务,开始执行。
从上面可以知道,setList 为真正需要执行的渲染列表的方法,我们接着往下看:
Component({
//...
data:{
/* 待渲染的视图列表 */
viewList: [],
/* 手机屏幕高度 */
winHeight: 0,
/* 分组索引 */
groupIndex:0
},
lifetimes: {
ready() {
wx.getSystemInfo({
success: (res) => {
this.setData({
/* 获取屏幕的高度 */
winHeight: res.windowHeight,
});
},
});
/* 保存所有数据 */
this.wholeList = []
/* 记录分组高度 */
this.groupHeightArr = []
}
},
methods:{
/* 装载数据 */
setList(val) {
const {
groupIndex } = this.data;
const newList = this.data.viewList;
/* 把数据保存到 wholeList 中 */
this.wholeList[groupIndex] = val;
/* 插入到视图列表中 */
newList[groupIndex] = val;
this.data.groupIndex++;
/* 直接渲染最新加入的数据 */
this.setData(
{
viewList: newList,
},
() => {
/* 记录渲染后的视图高度 */
this.setHeight(groupIndex);
}
);
},
},
})
setList 做的事情很简单,将增量的列表数据渲染出来,然后开始通过 setHeight 将渲染后的数据高度记录下来,这里有的同学会问,为什么要记录渲染后的数据高度,原因很简单,如果列表单元项 item 在规定的渲染区域之外,那么需要 skeleton 占位,但是需要设置 skeleton 高度,所以需要记录分组的高度作为占位节点的高度。
Component({
//...
methods:{
//...
···/* 设置高度 */
setHeight(groupIndex) {
const query = wx.createSelectorQuery().in(this);
query && query
.select(`#wrp_${
groupIndex}`)
.boundingClientRect((res) => {
/* 记录分组的高度 */
this.groupHeightArr[groupIndex] = res && res.height;
})
.exec();
/* 开始监听分组变化 */
this.observePage(groupIndex);
},
},
})
通过 setHeight 来记录高度之后。那么接下来就需要给当前分组创建一个 IntersectionObserver 来判断:
- 如果当前分组,在规定视图范围内,那么渲染真实的 item 元素。
- 如果当前分组,不在规定的视图范围内,那么渲染 skeleton 占位节点。
Component({
//...
methods:{
//...
/* 观察页面变化 */
observePage(groupIndex) {
wx.createIntersectionObserver(this)
.relativeToViewport({
/* 这里规定的有效区域为两个屏幕 */
top: 2 * this.data.winHeight,
bottom: 2 * this.data.winHeight,
})
.observe(`#wrp_${
groupIndex}`, (res) => {
const newList = this.data.viewList;
const nowWholeList = this.wholeList[groupIndex];
if (res.intersectionRatio <= 0) {
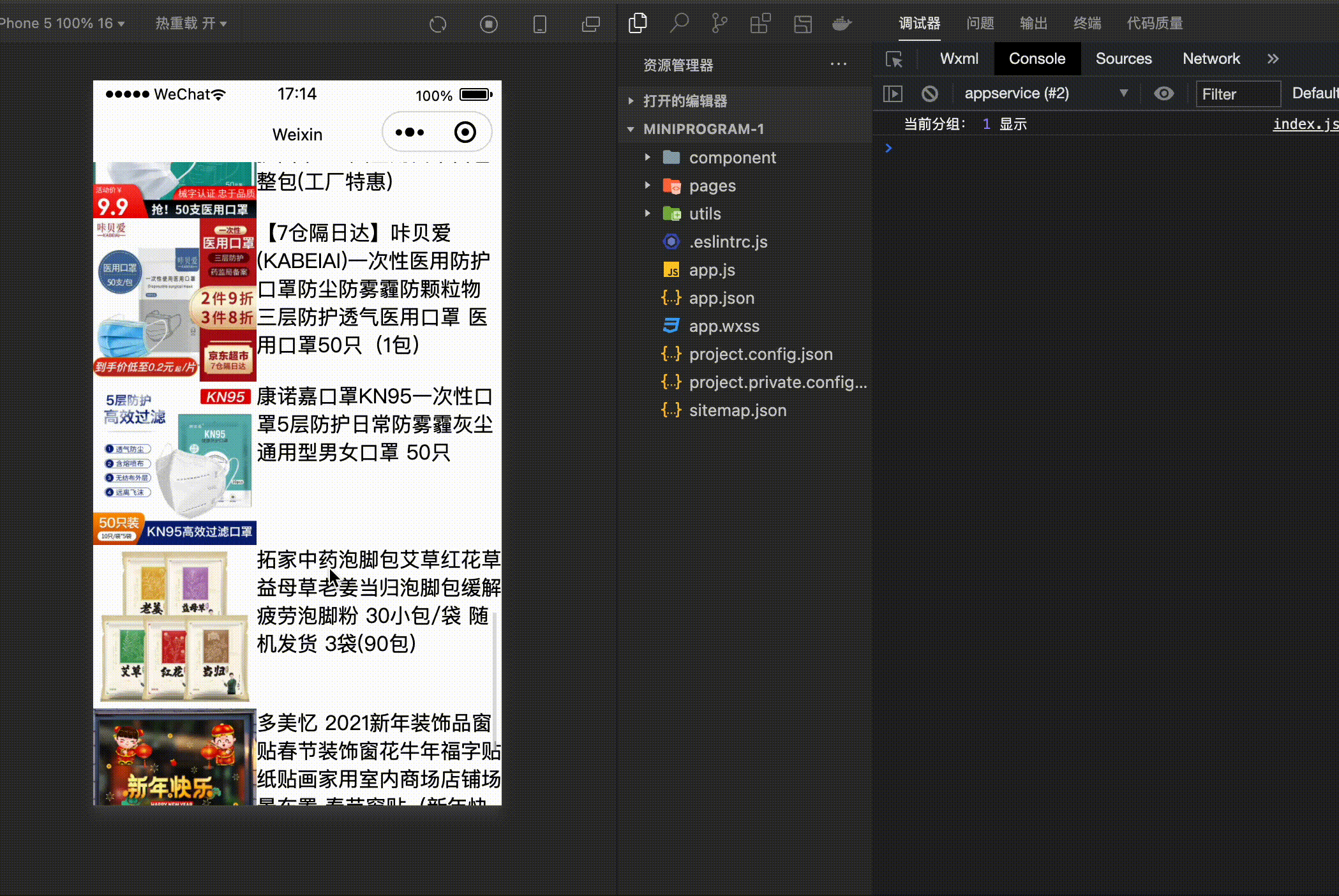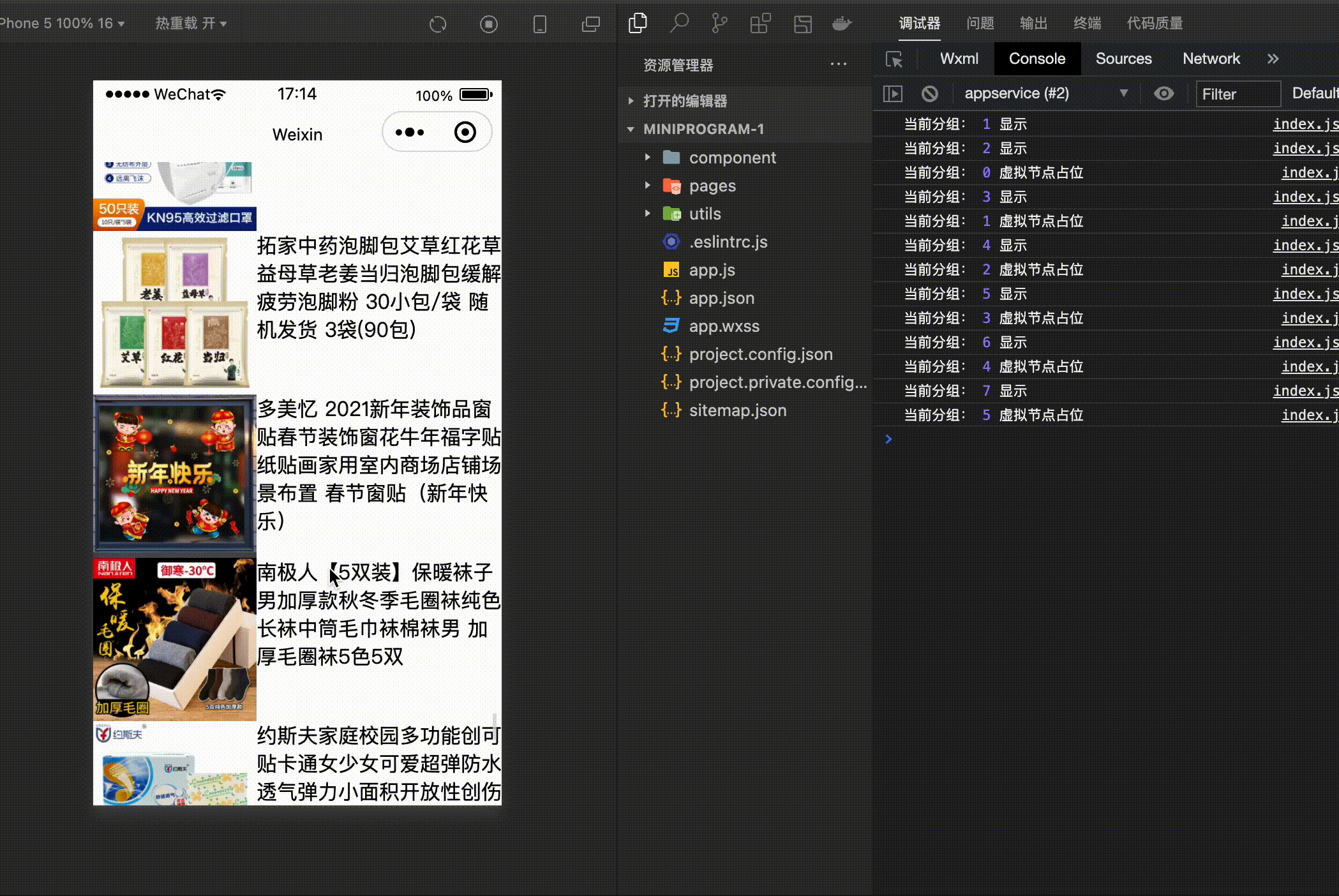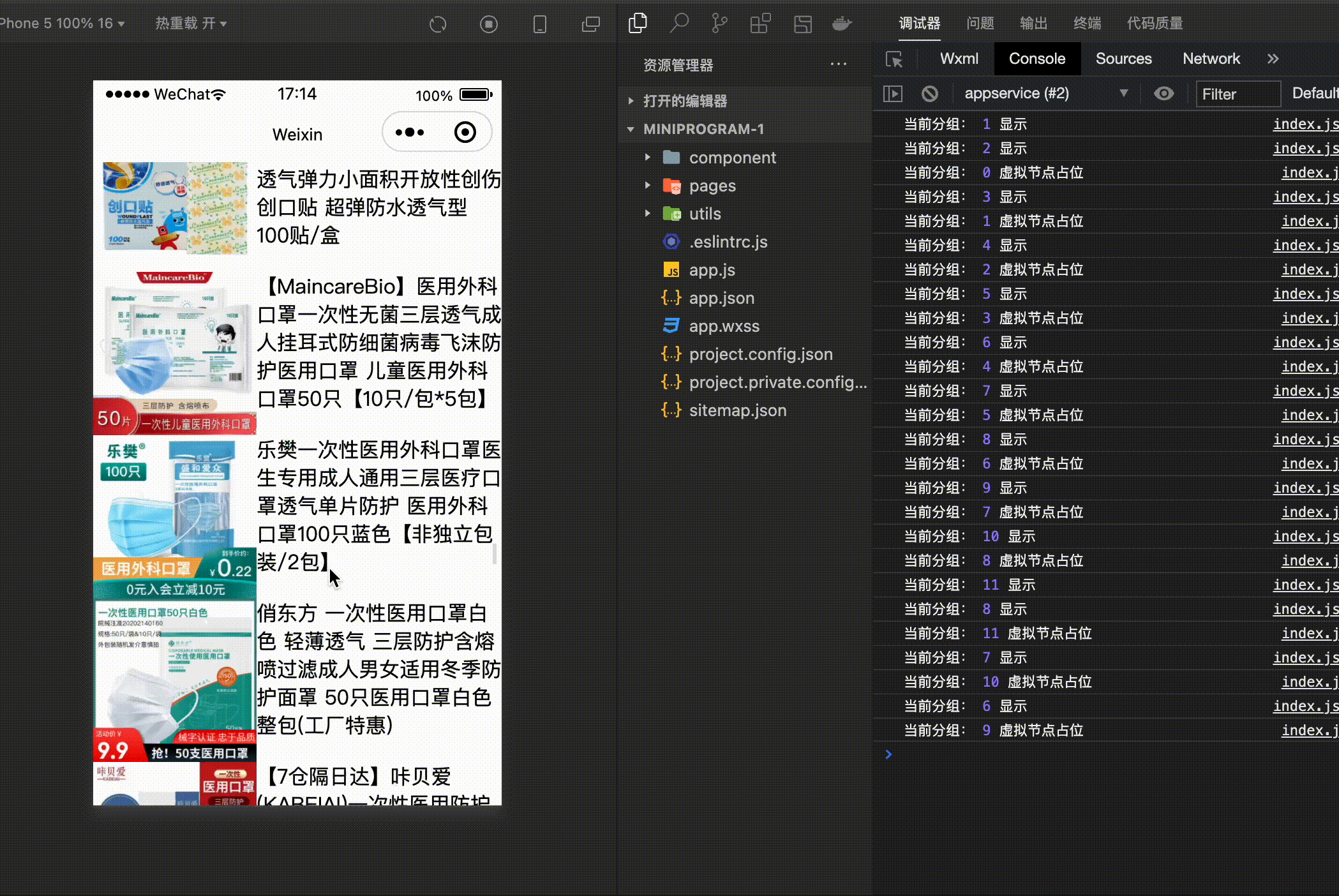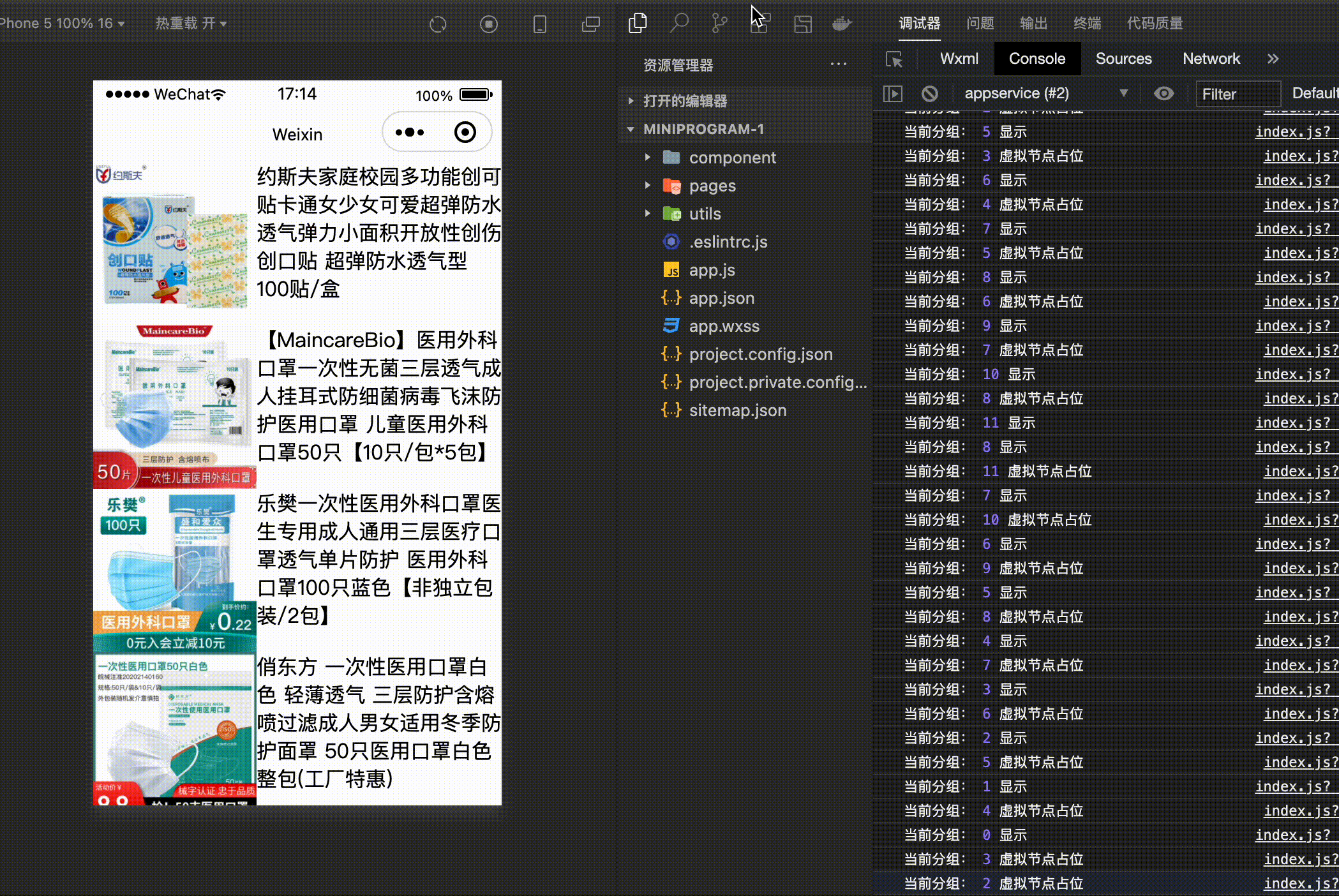
console.log('当前分组:',groupIndex,'虚拟节点占位' )
/* 如果不在有效的视图范围内,那么不需要渲染真实的数据,只需要计算高度,进行占位就可以了。 */
const listViewHeightArr = [];
const listViewItemHeight = this.groupHeightArr[groupIndex] / nowWholeList.length;
for (let i = 0; i < nowWholeList.length; i++) {
listViewHeightArr.push({
listViewItemHeight });
}
newList[groupIndex] = listViewHeightArr;
} else {
console.log('当前分组:',groupIndex,'显示' )
/* 如果在有效的区域内,那么直接渲染真实的数据就可以了 */
newList[groupIndex] = this.wholeList[groupIndex];
}
this.setData({
viewList: newList,
}, () => {
this.isRenderTask = false;
/* 渲染下一个更新任务 */
this.runRenderTask();
});
});
},
},
})
看一下 observePage 做了哪些事情?
- 首先通过 IntersectionObserver 创建一个观察者对象,这里规定的有效区域为两个屏幕。
- 接下来当滑动屏幕的时候,如果不在有效的视图范围内,那么不需要渲染真实的数据,只需要计算高度,进行占位就可以了。
- 如果在有效的区域内,那么直接渲染真实的数据就可以了。
接下来看一下 wxml 如何处理的:
<view class="list-view">
<!-- 列表前自定义插槽 -->
<slot name="before" />
<view
wx:for="{
{ viewList }}"
id="wrp_{
{ groupIndex }}"
wx:for-index="groupIndex"
wx:for-item="listItem"
wx:key="index"
>
<view
wx:for="{
{ listItem }}"
wx:for-item="listItem"
wx:key="index"
>
<block wx:if="{
{ listItem.listViewItemHeight }}">
<!-- 不在可视范围内 -->
<view style="height: {
{
listItem.listViewItemHeight}}px;overflow: hidden">
<skeleton/>
</view>·
</block>
<block wx:else>
<!-- 在可视范围内 -->
<item listItem="{
{listItem}}"/>
</block>
</view>
</view>
<!-- 列表后自定义插槽 -->
<slot name="after" />
</view>
模拟使用:
接下来我们做一下模拟:
<scroll-view
scroll-y="{
{ true }}"
bindscrolltolower="handleScrollLower"
style="height:{
{
winHeight}}px;"
lower-threshold="200"
>
<long-list-view
list="{
{list}}"
generic:item="item"
generic:skeleton="skeleton"
/>
</scroll-view>
数据是模拟的,接下来看一下整体的效果:
五 总结
本章节介绍了在小程序端长列表的性能瓶颈,介绍了常用的解决方案,感兴趣的同学可以试着实现一下长列表,也希望做小程序列表优化的同学看到,能够有一个启发。
创作不易,希望喜欢的可以给作者 点赞 + 关注 一波 🌹🌹🌹 。

