
一 一切根源都从产品小姐姐无厘头需求开始
最近在开发业务项目的时候,产品小姐姐突然来到我身边,然后就对着电脑一顿操作,具体场景大致是这样的。
场景一:

如上图所示,当在数万级别的数据中,选择一条,点击查看,跳转到当前数据的详情页,当点击按钮返回返回来,或者是浏览器前进后退等其他操作,返回到列表页的时候。要记录当前列表的位置。也就是要还原点击查看查看前的页面。但是当点击tab菜单按钮的时候,要清除页面信息。
场景二:

如上图所示,当我们编辑内容的时候,一些数据可能从其他页面获得,所以要求,无论切换路由,切换页面,当前页面的编辑信息均不能被置空,只有点击确定 ,重置,表单才内容置空。
场景三: 场景一 + 场景二 是更复杂的缓存页面信息场景。
二 梳理需求
接这个需求的时候,咋眼一看,what ,好像是 vue 中的 keepalive + vue router功能,但是,我们几个项目技术栈是react ,react , react! react 中没有对应的 keepalive内置 api,后来上GitHub上搜索相关项目,感觉有很多不符合业务需求的情况。还有一些潜在的风险。 瞬间慌了~~~。内心有一种万只神兽奔腾的感觉。

在漂亮产品小姐姐面前,怎么能说不,那不显得研发能力差,强行装了一波说很简单,只能硬着头皮接下来了。产品小姐姐临走前还说还鬼魅的笑了笑,说可以把几个项目的部分页面都加上这种效果。
1 解决方案
1 数据状态缓存到公共管理可行性
这个需求首先让我想到的是用redux或者是mobx来把页面的状态缓存起来,然后切换页面的时候,把这些数据缓存进去,再次切换回来的时候,将数据取出来,这样就一个问题,即便能缓存state层,但是如果一些表单组件是非受控组件,是无法缓存下来的,还有一些dom状态是缓存不了的,比如手动添加的一些样式等。还有就是实际情况比较复杂,有富文本组件,你是无法直接获取绑定的state的。
第二个原因就是有好几个项目,而且页面比较多,如果都建立数据管理,那么工作量会非常的大。
所以数据状态缓存的可行性不高,即便可以实现,也需要大量的复制粘贴,这不是我们的追求。
2 react-keepalive-router诞生
所以我们只能选择自己开发一个项目,然后把它开源,并应用在公司项目中来。既然选择缓存页面,那么为什么不在react-router中的 Route组件和Switch组件中做文章呢,我们需要对Route 和 Switch 组件做一些功能性的拓展,正好笔者之前自己研究过react-router源码,并写了一篇(这一次彻底弄懂react-router路由原理)[https://juejin.cn/post/6886290490640039943#comment] ,感兴趣的同学可以三连一波,因为项目是在router路由层面,所以给它起了一个名字react-keepalive-router。接下来就要对整个项目做一个系统的设计。
三设计阶段
1 了解react-fiber
为什么我们的项目要提到react-fiber呢,这里我先说一下,react-fiber, React Fiber 是从 v16 版本开始对 Stack Reconciler 进行的重写,是 v16 版本的核心算法实现。react在初始化构建过程中,会产生一个由child指向子fiber,sibling指向兄弟fiber,return指向父fiber三个指针构建的fiber树结构,里面保存着dom信息,update信息,props信息等,我们核心思想就是,在切换页面的时候,组件销毁,但是作为渲染调度的react fiber保存keepalive状态。只要fiber存活,就能获取到dom元素,数据层state等信息。

2 基于 react-router-dom 和 react 16.8
首先我们需要对react-router库中的 Route组件和Switch组件作出改造,可以通过路由层面实现缓存路由功能。因为在设计之初,我就想着将用不同的状态管理keepalive状态,这样的好处是,后续可以给缓存路由组件,增加一些额外的声明周期,比如说vue中 activated 和 deactivated一样。因为设计思想是状态管理,项目依赖中不想引入redux等第三方库,所以这里选了react-hooks中 useReducer恰到好处。这就是react基础库 16.8+的原因之一。另外一个原因就是hooks中有useMemo这样防止渲染穿透的api,有助于调节路由组件的更新次数。
工作流程分析
受到react-router-cache-route开源项目的启发,我在设计整个流程的时候,采取了交换dom树的方式。
初始化 : 整体设计思路第一次切入缓存页面的时候,会自动生成一个容器组件,缓存Route会把组件,交给容器组件来挂载,然后容器组件生成fiber,render之后生成对应的dom树,将dom树交给Route组件(也就是我们的正常的页面)。
切换页面: 切换页面的时候,路由组件是肯定卸载的,这时候需要将我们的dom还给容器组件,然后容器组件进入冻结状态。
再次切换到缓存页面:再次进入路由页面的时候,首先从容器中,发现有该页面的缓存,那么将容器解封状态,然后将dom树,还给当前路由页面。完成keepalive状态。
缓存销毁:: 项目支持销毁缓存功能,调用销毁方法,会卸载当前缓存容器,进一步销毁fiber 和 dom ,完成整个销毁功能。
工作流程图

工作原理图

设计的优势在哪里?
设计优势:
1 因为内部运用了 useReducer 状态管理,管理缓存状态,可以更灵活,操纵缓存路由组件,采用react hooks全新api,渲染节流,手动解除缓存,增加了缓存的状态周期,监听函数等。
2 这套缓存页面的思想,不仅仅可以用在路由页面级别,后期可以迁移的component组件级别上来。也是后续维护和开发的方向。
四 使用简介 + 快速上手
我们开始设计项目的用法,api,已经应用场景。通过上述工作原理,讲述了 keepliveRouteSwitch 和 keepliveRoute 在整个缓存过程中的作用,
下载
因为我们是把项目上传到了npm方便其他项目用,所以可以直接从 npm 上下载。
npm install react-keepalive-router --save
# or
yarn add react-keepalive-router
使用
1 基本用法
KeepaliveRouterSwitch
KeepaliveRouterSwitch可以理解为常规的Switch,也可以理解为 keepaliveScope,我们确保整个缓存作用域,只有一个 KeepaliveRouterSwitch 就可以了。
常规用法
import { BrowserRouter as Router, Route, Redirect ,useHistory } from 'react-router-dom'
import { KeepaliveRouterSwitch ,KeepaliveRoute ,addKeeperListener } from 'react-keepalive-router'
const index = () => {
useEffect(()=>{
/* 增加缓存监听器 */
addKeeperListener((history,cacheKey)=>{
if(history)console.log('当前激活状态缓存组件:'+ cacheKey )
})
},[])
return <div >
<div >
<Router >
<Meuns/>
<KeepaliveRouterSwitch>
<Route path={'/index'} component={Index} ></Route>
<Route path={'/list'} component={List} ></Route>
{ /* 我们将详情页加入缓存 */ }
<KeepaliveRoute path={'/detail'} component={ Detail } ></KeepaliveRoute>
<Redirect from='/*' to='/index' />
</KeepaliveRouterSwitch>
</Router>
</div>
</div>
}
这里应该注意⚠️的是对于复杂的路由结构。或者KeepaliveRouterSwitch 包裹的子组件不是Route ,我们要给 KeepaliveRouterSwitch 增加特有的属性 withoutRoute 就可以了。如下例子🌰🌰🌰:
例子一
<KeepaliveRouterSwitch withoutRoute >
<div>
<Route path="/a" component={ComponentA} />
<Route path="/b" component={ComponentB} />
<KeepaliveRoute path={'/detail'} component={ Detail } ></KeepaliveRoute>
</div>
</KeepaliveRouterSwitch>
例子二
或者我们可以使用 renderRoutes 等api配合 KeepliveRouterSwitch 使用 。
import {renderRoutes} from "react-router-config"
<KeepliveRouterSwitch withoutRoute >{ renderRoutes(routes) }</KeepliveRouterSwitch>
KeepaliveRoute
KeepaliveRoute 基本使用和 Route没有任何区别。
在当前版本中⚠️⚠️⚠️如果 KeepaliveRoute 如果没有被 KeepaliveRouterSwitch包裹就会失去缓存作用。
效果
2 其他功能
1 缓存组件激活监听器
如果我们希望对当前激活的组件,有一些额外的操作,我们可以添加监听器,用来监听缓存组件的激活状态。
addKeeperListener((history,cacheKey)=>{
if(history)console.log('当前激活状态缓存组件:'+ cacheKey )
})
第一个参数未history对象,第二个参数为当前缓存路由的唯一标识cacheKey
2 清除缓存
缓存的组件,或是被route包裹的组件,会在props增加额外的方法cacheDispatch用来清除缓存。
如果props没有cacheDispatch方法,可以通过
import React from 'react'
import {
useCacheDispatch } from 'react-keepalive-router'
function index(){
const cacheDispatch = useCacheDispatch()
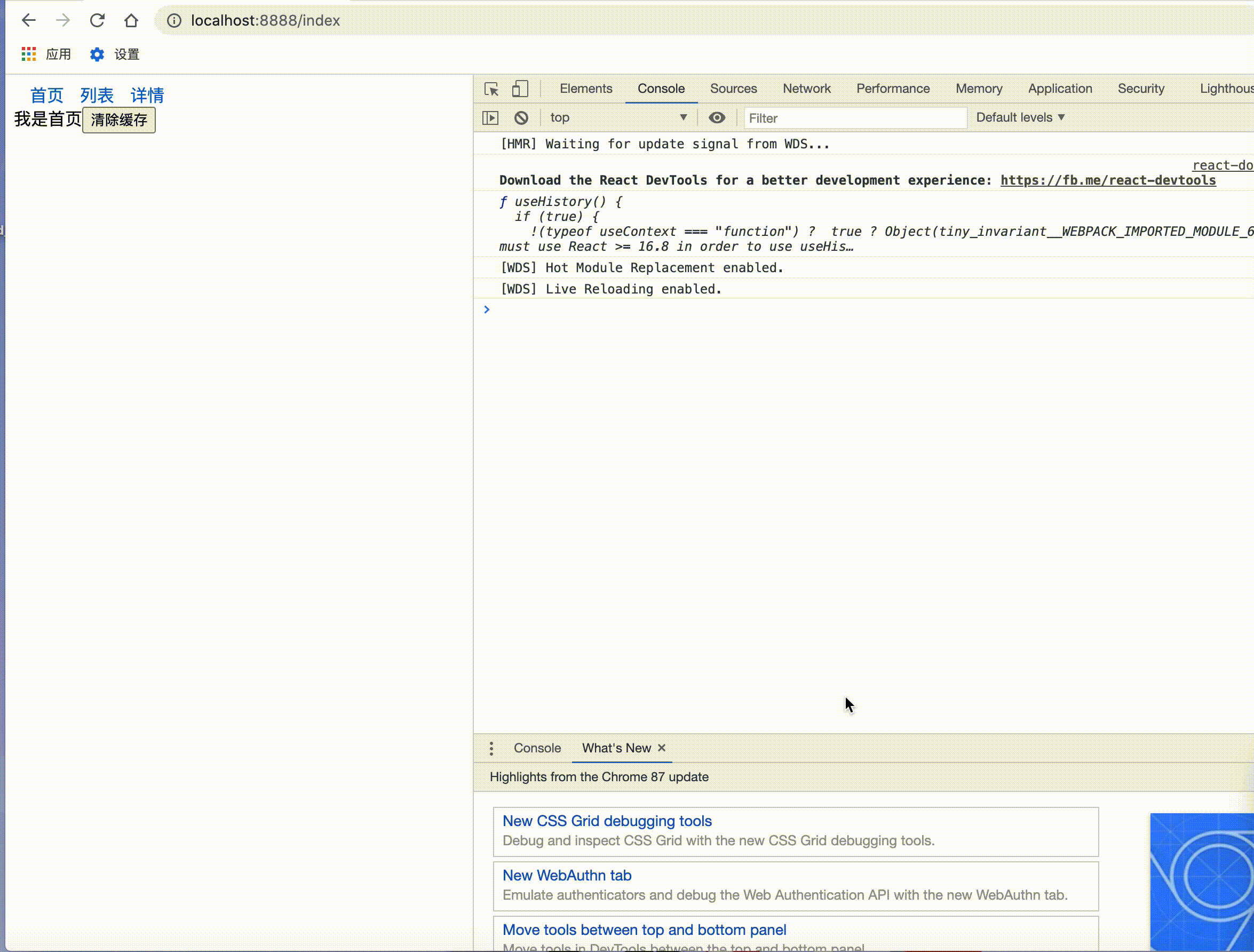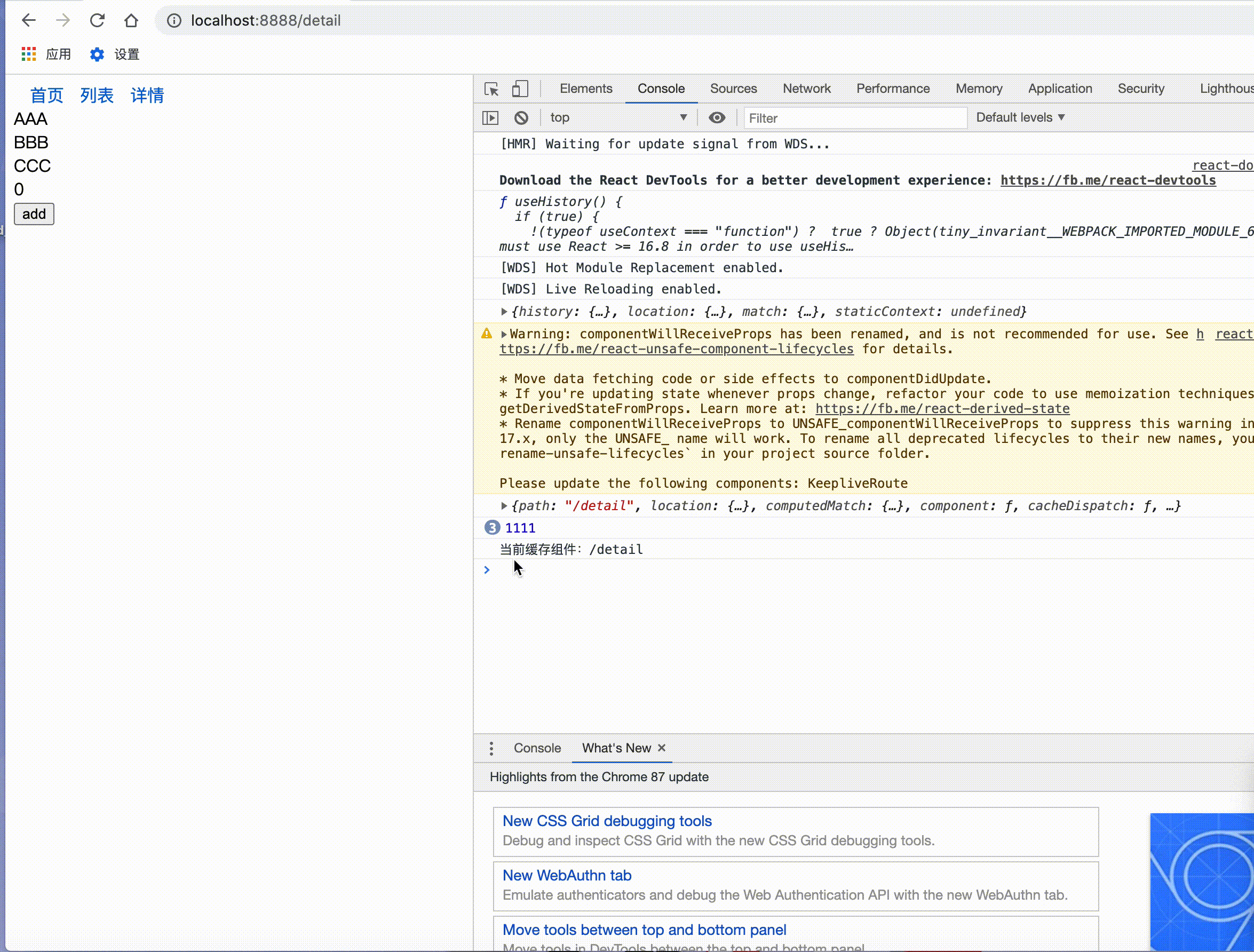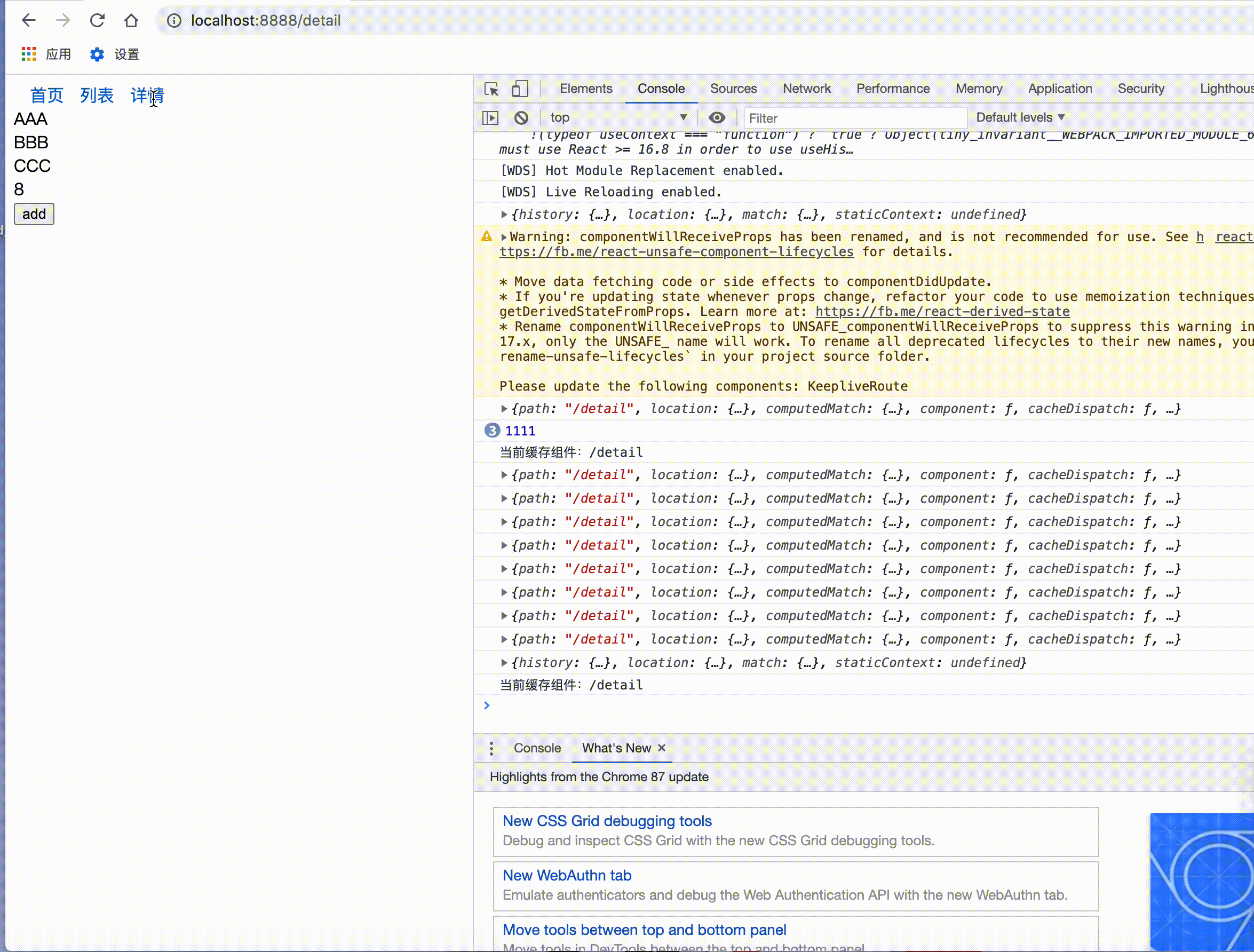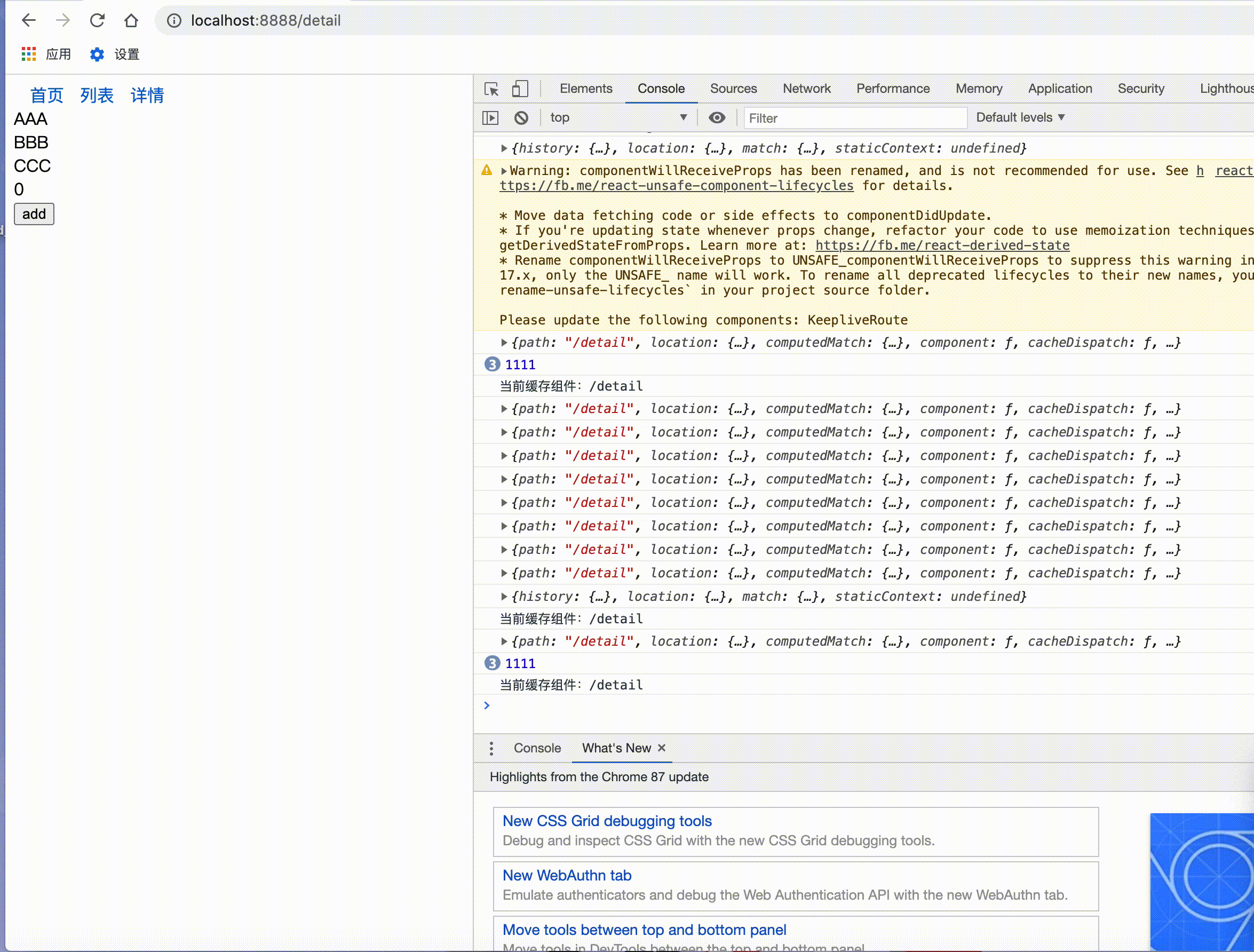
return <div>我是首页
<button onClick={
()=> cacheDispatch({
type:'reset' }) } >清除缓存</button>
</div>
}
export default index
1 清除所有缓存
cacheDispatch({
type:'reset' })
2 清除单个缓存
cacheDispatch({
type:'reset',payload:'cacheId' })
3 清除多个缓存
cacheDispatch({
type:'reset',payload:['cacheId1','cacheId2'] })
五 验证阶段
由于这里使用公司项目不是很合适,我用了一个自己的项目做demo:
接下来就是验证阶段首先我们看一下产品小姐姐第一个需求:

第二个需求:

完美实现产品需求。
六 打包阶段 + 发布npm阶段
rollup打包
接下来就是 rollup 打包阶段,rollup打包阶段。项目结构是这样的。

rollup.config.js是整个rollup的配置文件,然后我们通过 rollup 打包后的文件存在 lib文件夹下。

rollup.config.js 内容如下
import resolve from 'rollup-plugin-node-resolve'
import babel from 'rollup-plugin-babel'
import {
uglify } from 'rollup-plugin-uglify'
export default [
{
input: 'src/index.js',
output: {
name: 'keepaliveRouter',
file: 'lib/index.js',
format: 'cjs',
sourcemap: true
},
external: [
'react',
'react-router-dom',
'invariant'
],
plugins: [
resolve(),
babel({
exclude: 'node_modules/**'
})
]
},
/* 压缩` */
{
input: 'src/index.js',
output: {
name: 'keepaliveRouter',
file: 'lib/index.min.js',
format: 'umd'
},
external: [
'react',
'react-router-dom',
'invariant'
],
plugins: [
resolve(),
babel({
exclude: 'node_modules/**'
}),
uglify()
]
}
]
发布npm
对于发布npm
第一步:需要在npm注册账号。https://www.npmjs.com/signup
第二步: 登陆 npm login
第三步:创建 package.json
{
"name": "react-keepalive-router", /* 名称 */
"version": "1.1.0", /* 版本号 */
"description": "基于`react 16.8+` ,`react-router 4+` 开发的`react`缓存组件,可以用于缓存页面组件,类似`vue`的`keepalive`包裹`vue-router`的效果功能。", /* 描述 */
"main": "index.js", /* 入口文件 */
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1",
"build": "rollup --config"
},
"keywords": [ /* npm 关键词 */
"keep alive",
"react",
"react router",
"react keep alive route",
"react hooks"
],
"homepage": "https://github.com/GoodLuckAlien/react-keepalive-router", /* 指向 github */
"peerDependencies": {
/* npm 项目依赖 */
"react": ">=16.8",
"react-router-dom": ">=4",
"invariant": ">=2"
},
"author": "alien",
"license": "ISC",
"devDependencies": {
/* 开发环境下依赖 */
"@babel/core": "^7.12.3",
"@babel/preset-react": "^7.12.5",
"@babel/preset-env": "^7.12.1",
"@babel/plugin-proposal-class-properties": "^7.12.1",
"rollup": "^2.33.3",
"rollup-plugin-node-resolve": "^5.2.0",
"rollup-plugin-babel": "^4.4.0",
"rollup-plugin-uglify": "^6.0.4"
},
"dependencies": {
/* 生产环境依赖 */
"invariant": "^2.2.4"
}
}
第四步:万事俱备之后,用 npm publish 发布。
第五步:升级版本,升级版本很简单,需要我们在package.json 升级版本号,然后重新 npm publish 就可以了。
废弃版本号
如果我们想废弃某个版本 , 执行命令 npm deprecate <pkg>[@<version>] <message>
废弃包
如果我们想废弃包 npm unpublish <pkg> --force
.npmignore
.npmignore里面声明的文件和文件价名称,不会被上传到 npm , 我的项目除了 README.md ,package.json 和 lib 下打包的文件之外,大部分文件是开发时候或者编译阶段用到的,不需要上传到npm,所以需要在 .npmignore 这么写
docs
node_modules
src
md
.babelrc
.gitignore
.npmignore
.prettierrc
rollup.config.js
yarn.lock
七 总结
项目地址
从需求到开源的流程跑通之后,会有很大的成就感,刚开始独立开发的项目肯定很有很多bug,不怕有bug,要有一颗勇于修复bug并把项目维护下去的决心。
送人玫瑰,手留余香,阅读的朋友可以给笔者点赞,关注一波。陆续更新前端文章。
感觉有用的朋友可以关注笔者公众号 前端Sharing 持续更新前端文章。



