
一、结构体变量的声明
typedef char BTDataType; typedef struct BinaryTreeNode { struct BinaryTreeNode* left; struct BinaryTreeNode* right; BTDataType val; }BTNode;
二、 通过前序遍历的数组构建二叉树
给定你一个通过前序遍历字符数组你将如何把它构建成一颗二叉树呢(字符串中‘#’代表NULL)?
这里最好的方法肯定是递归,因为这个是前序遍历的数组,是典型的DFS(深度优先),而深度优先最适合的方法就是递归。
BTNode* BinaryTreeCreate(BTDataType* a, int* pi) { assert(a); //如果遇到‘#’,那说明遇到NULL了,pi指向的下标需要++ //跳过这个字符‘#’,然后返回一颗NULL树 if (a[*pi] == '#') { (*pi)++; return NULL; } //动态开辟一颗子树 BTNode* root = (BTNode*)malloc(sizeof(BTNode)); if (root == NULL) { perror("malloc fail"); return NULL; } //给这棵树赋值数组对应的字符 root->val = a[*pi]; (*pi)++; //再递归构造棵树的左子树和右子树 root->left = BinaryTreeCreate(a, pi); root->right = BinaryTreeCreate(a, pi); //最后返回这颗树 return root; }
三、二叉树的销毁
void BinaryTreeDestory(BTNode* root) { //如果遇到空树就返回 if (root == NULL) { return; } //递归销毁这棵树的左子树和右子树 BinaryTreeDestory(root->left); BinaryTreeDestory(root->right); //最后把这棵树的根销毁 free(root); root = NULL; }
四、统计二叉树结点的个数
int BinaryTreeSize(BTNode* root) { //如果遇到空树,就返回0 if (root == NULL) { return 0; } //否则就返回左子树的结点数+右子树的结点数+自己本身 return BinaryTreeSize(root->left) + BinaryTreeSize(root->right) + 1; }
五、统计二叉树叶子节点(无左右孩子的节点)的个数
int BinaryTreeLeafSize(BTNode* root) { //如果遇到空树就返回,那证明后面就没有子树了,也就没有叶子节点,返回0 if (root == NULL) { return 0; } //如果这棵树的左子树和右子树都为NULL,那证明这个结点就是叶子节点(根据叶子节点的定义),返回1 if (root->left == NULL && root->right == NULL) { return 1; } //否则就返回左子树的叶子节点的个数+右子树叶子节点的个数 else { return BinaryTreeLeafSize(root->left) + BinaryTreeLeafSize(root->right); } }
六、求二叉树第K层的节点的个数
这个函数的实现思路是:求一颗二叉树的第K层的节点的个数可以看作是求左右子树的第K-1层的节点的个数。,这也是一种分治的思想,可以用递归来实现。
int BinaryTreeLevelKSize(BTNode* root, int k) { //如果遇到空树,那就证明要么这一层就是所求的第K层的,要么就是 //还没递归到第K层就出现了空树,无论是哪一种情况都说明这一层和 //后面都不会有位于第K层的节点了,所以返回0 // if (root == NULL) { return 0; } //如果K递减到,说明这一个跟节点就位于第K层,返回1 if (k == 1) { return 1; } //否则就返回左子树的第K-1层的节点+右子树第K-1层的节点树 return BinaryTreeLevelKSize(root->left, k - 1) + BinaryTreeLevelKSize(root->right, k - 1); }
七、查找值为x的节点并返回节点的地址
BTNode* BinaryTreeFind(BTNode* root, BTDataType x) { //如果遇到空树就证明这一颗子树找不到x if (root == NULL) { return NULL; } //如果这棵树的根节点的值就是查找的x,就返回这个根节点 //返回上一层调用这个函数的栈帧 if (root->val == x) { return root; } //如果根节点不是要找的,就递归到左子树查找x BTNode* leftFind = BinaryTreeFind(root->left, x); //找到了就返回 if (leftFind) { return leftFind; } //左子树找不到就递归到右子树查找 BTNode* rightFind = BinaryTreeFind(root->right, x); //找到了就返回 if (rightFind) { return rightFind; } //如果根不是,左子树找不到,右子树找不到,那就不可能找到这个值了 //这里返回NULL是返回到上一层调用这个函数的栈帧中,并不是直接得出 //结果,等到返回到第一层调用这个函数的栈帧后依然找不到这个值才是 //真正的在这一整棵树都找不到这个值,建议话递归展开图理解 return NULL; // 不能写成 // return BinaryTreeFind(root->left, x) || BinaryTreeFind(root->right, x); // 因为这里要求的是返回节点的地址, //“||”是逻辑运算符,只能得到逻辑结果,即真或者加(0为假,非0为真) // 所以这样写的话直接返回的逻辑结果是布尔值,并不符合要求 //不建议写成 /*return BinaryTreeFind(root->left, x) ? BinaryTreeFind(root->left, x) : BinaryTreeFind(root->right, x);*/ //因为如果在左子树找到了这个节点,但是由于没有保存 //导致返回的时候又要再找一遍,如果这棵树的深度越深, //那么再找一遍的话越往下的子树呗反复调用的次数就越多 //大大降低了效率 }
八、二叉树的遍历
二叉树的前中后序遍历其实都是一样的递归思路的,只不过访问节点的时间不同。三个遍历都是按照一下这张图片这样走的。

8.1 前序遍历
先访问根节点,再递归访问左子树,最后递归访问右子树。
void BinaryTreePrevOrder(BTNode* root) { //如果遇到空树就打印一个‘#’,再返回, // 这样能够更加直观地反映这棵树的真实的形状 if (root == NULL) { printf("%c ",'#'); return; } //否则先访问它的根节点,再递归访问它的左子树,最后递归访问它的右子树(这里的访问是打印) printf("%c ", root->val); BinaryTreePrevOrder(root->left); BinaryTreePrevOrder(root->right); }
8.2 中序遍历
和前序遍历是一样的道理,只是访问根节点的时机不同,先递归访问左子树,再访问根节点,最后递归访问右子树。
void BinaryTreeInOrder(BTNode* root) { if (root == NULL) { printf("%c ", '#'); return; } BinaryTreeInOrder(root->left); printf("%c ", root->val); BinaryTreeInOrder(root->right); }
8.3 后序遍历
先递归访问左子树,再访问右子树,最后递归访问根节点。
void BinaryTreePostOrder(BTNode* root) { if (root == NULL) { printf("%c ", '#'); return; } BinaryTreePostOrder(root->left); BinaryTreePostOrder(root->right); printf("%c ", root->val); }
8.4 层序遍历
这个层序遍历就是一层一层的往下遍历,直到叶子节点。
这里的层序遍历是典型的BFS(广度优先)。
这里我们需要用到一个队列来协助这里的遍历才能使问题更加简化一些。
思路:首先是根节点先进队列,访问这个根节点,然后根节点出队列,在节点出队列的同时判断这个节点的左孩子节点是否为空,不为空就入队列,为空则不入,再判断右孩子节点是否为空,不为空就入队列,否则不入,循环以上的动作(根节点出队列的同时把左右孩子(不为空)的带进队列)当这个队列为空的时候,就证明这棵树遍历完了。
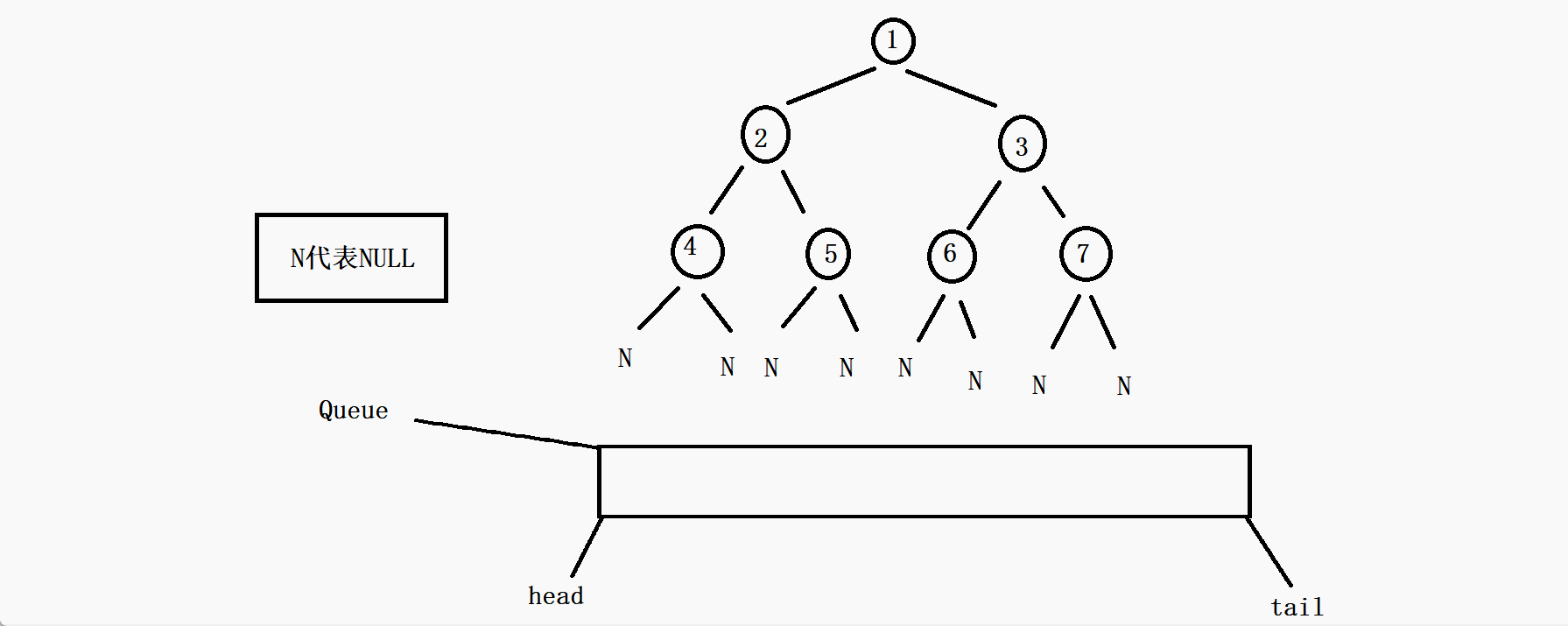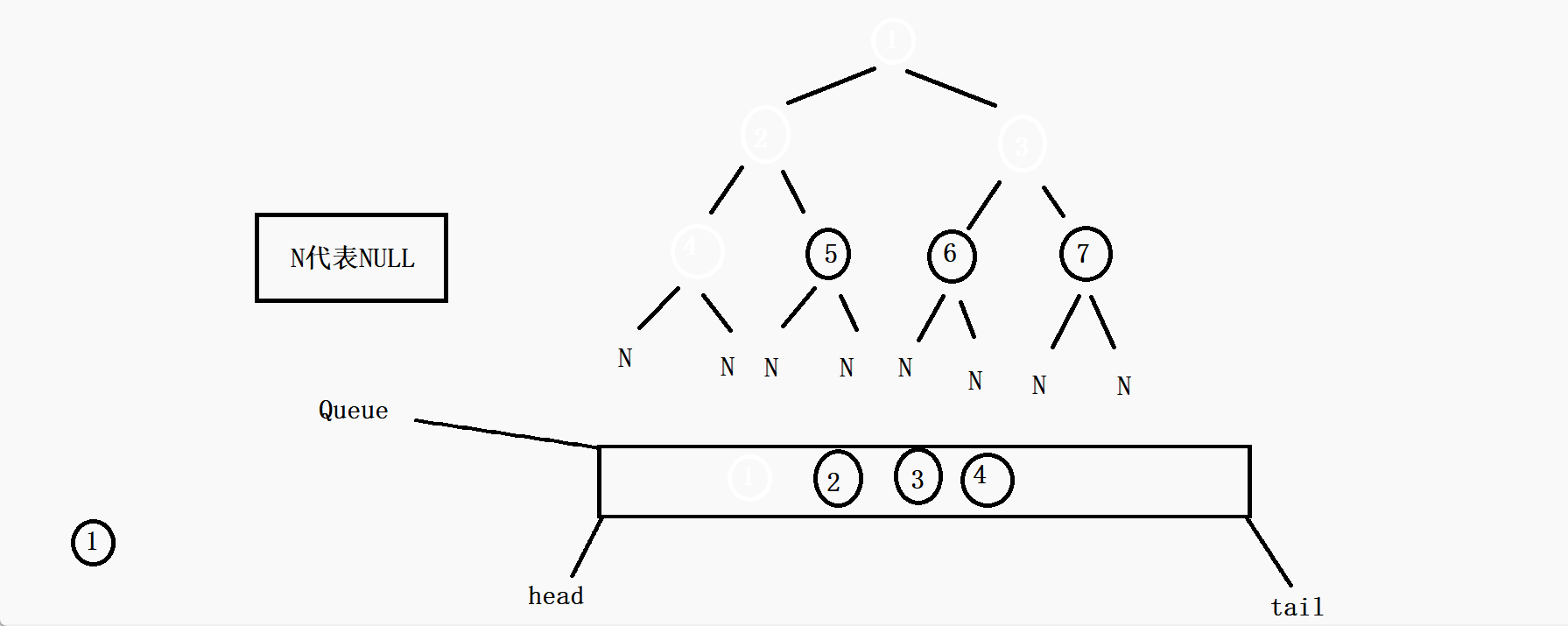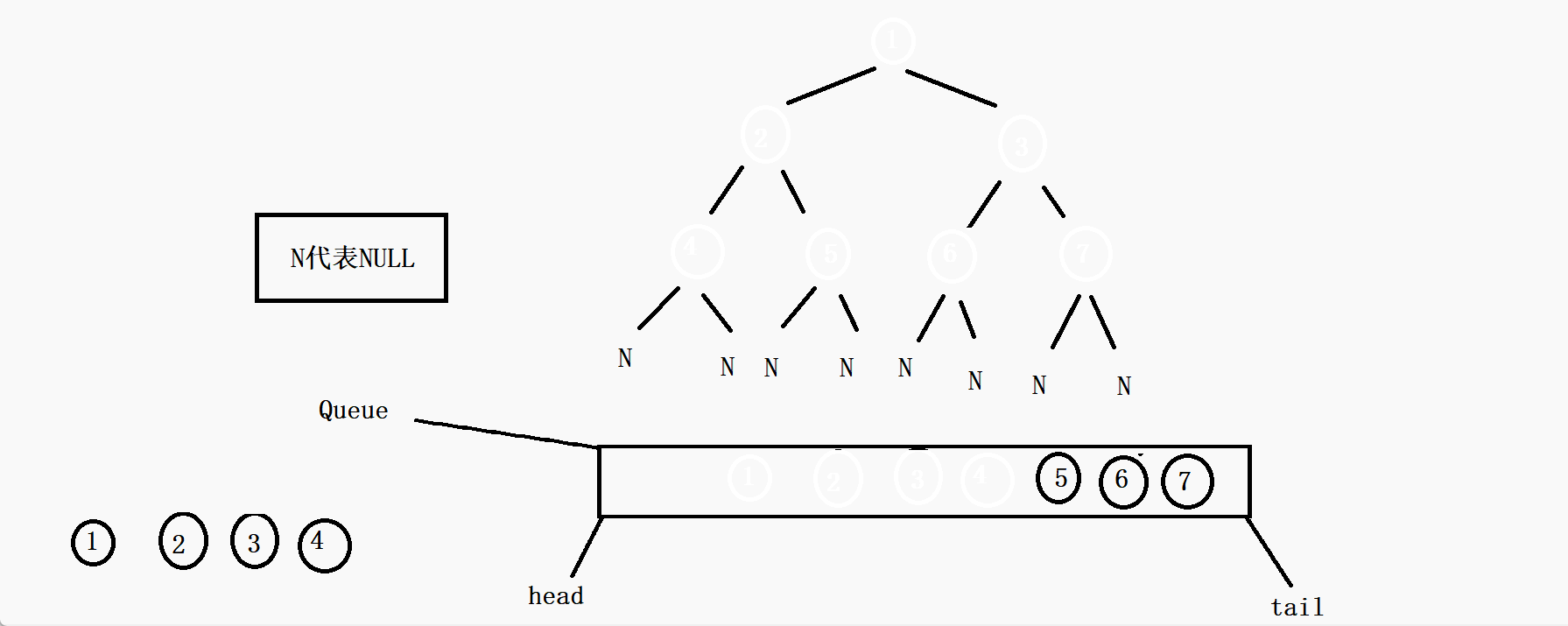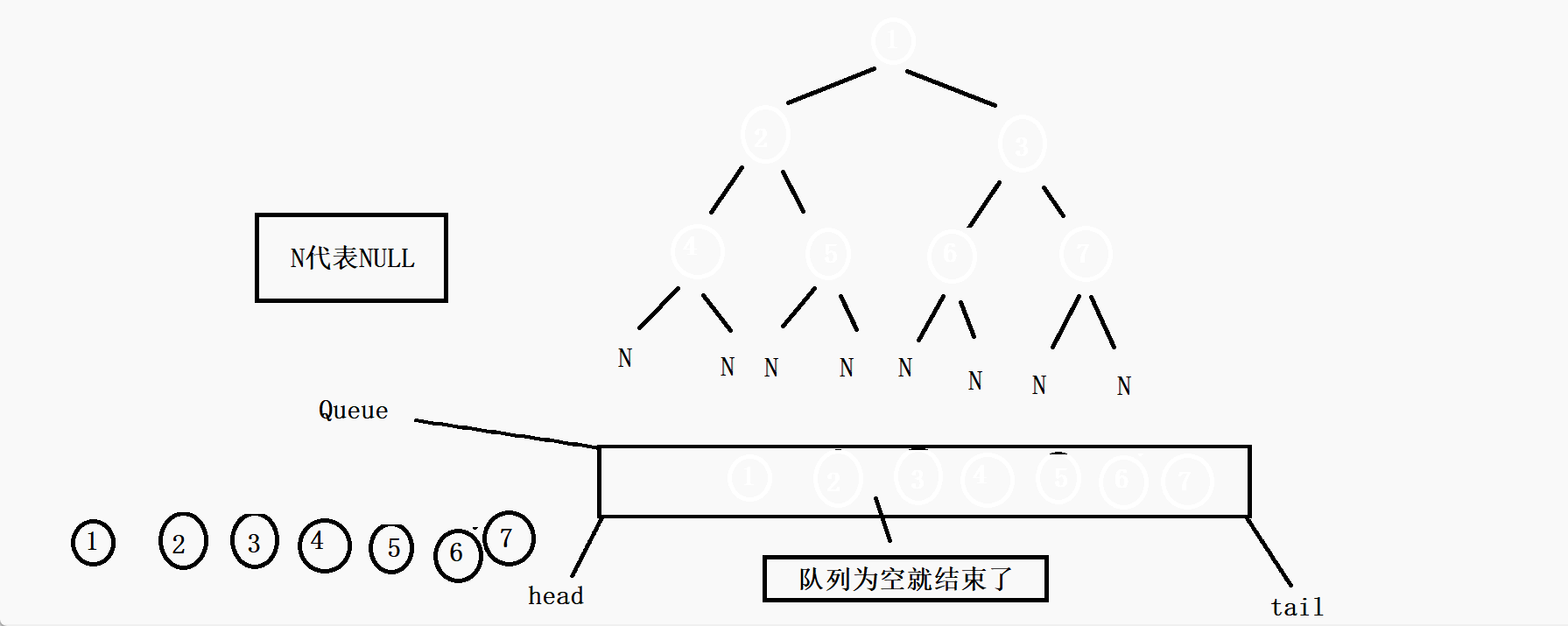
void BinaryTreeLevelOrder(BTNode* root) { //如果传过来的是空树,那就直接返回了 if (root == NULL) { return; } //否则创建一个队列 Queue q; //初始化队列 QueueInit(&q); //先把根节点入队列 QueuePush(&q, root); //当队列为空的时候循环就结束了 while (!QueueEmpty(&q)) { //取队列头的元素 BTNode* front = QueueFront(&q); //打印代表访问 printf("%c ", front->val); //如果根节点的左孩子不为空,就把左孩子带进队列 if (front->left) { QueuePush(&q, front->left); } //如果右孩子不为空,就把右孩子带进队列 if (front->right) { QueuePush(&q, front->right); } //队列头的元素出队列 QueuePop(&q); } //销毁队列 QueueDestroy(&q); }
九、判断一棵树是否是完全二叉树
这里要判断一棵树是否为完全二叉树,首先清楚什么叫完全二叉树,完全二叉树其实是所有的有效节点(不为NULL的节点)都是连续不间断的二叉树就是完全二叉树。



通过观察以上的几棵树可发现,完全二叉树的所有的有效节点一定是连续的,我们就可以利用这个作为突破点来判断一颗树是否为完全二叉树了。
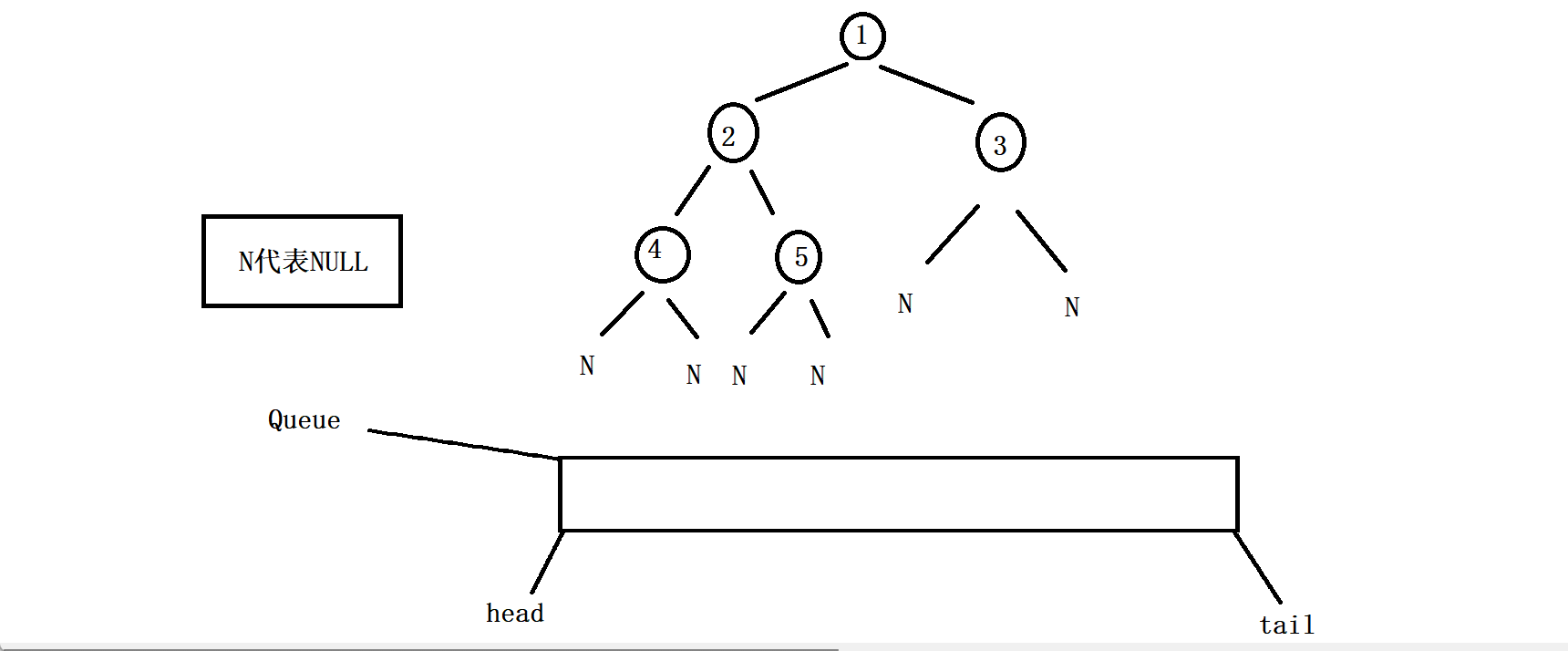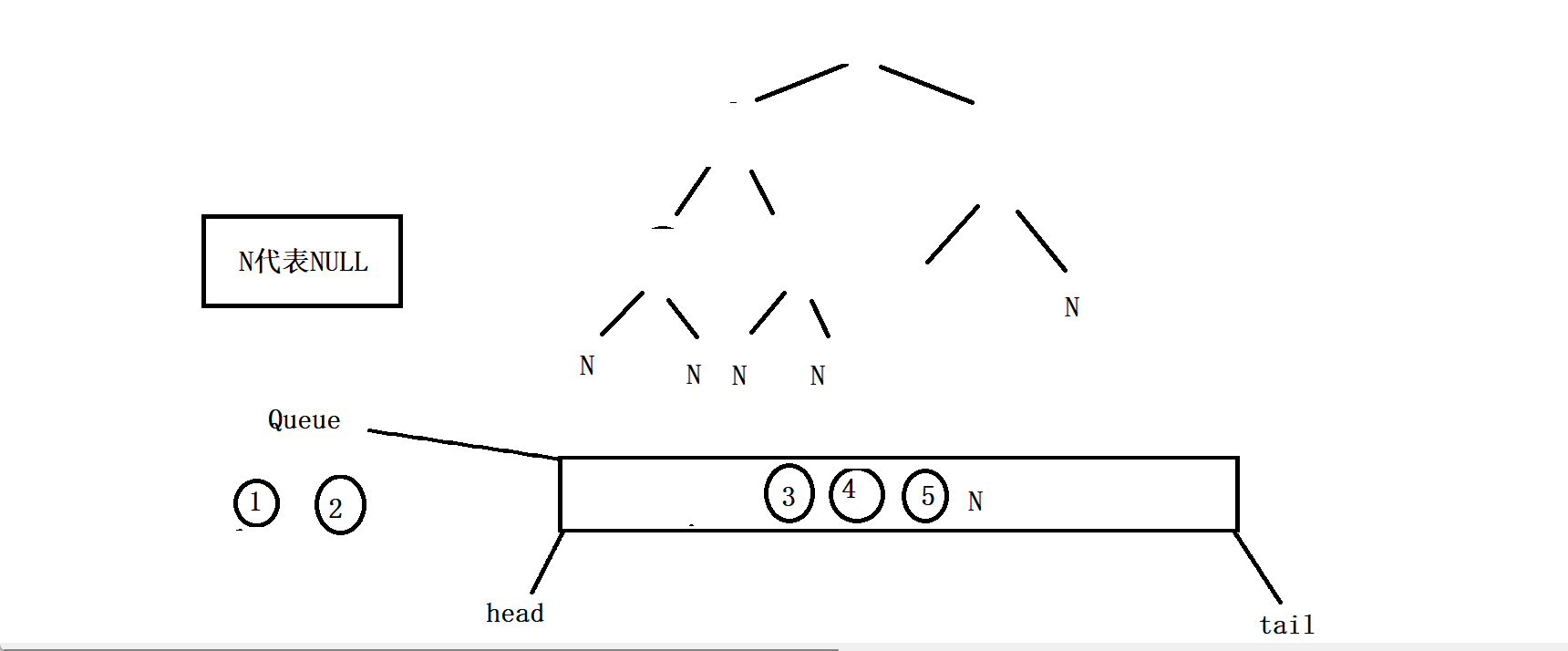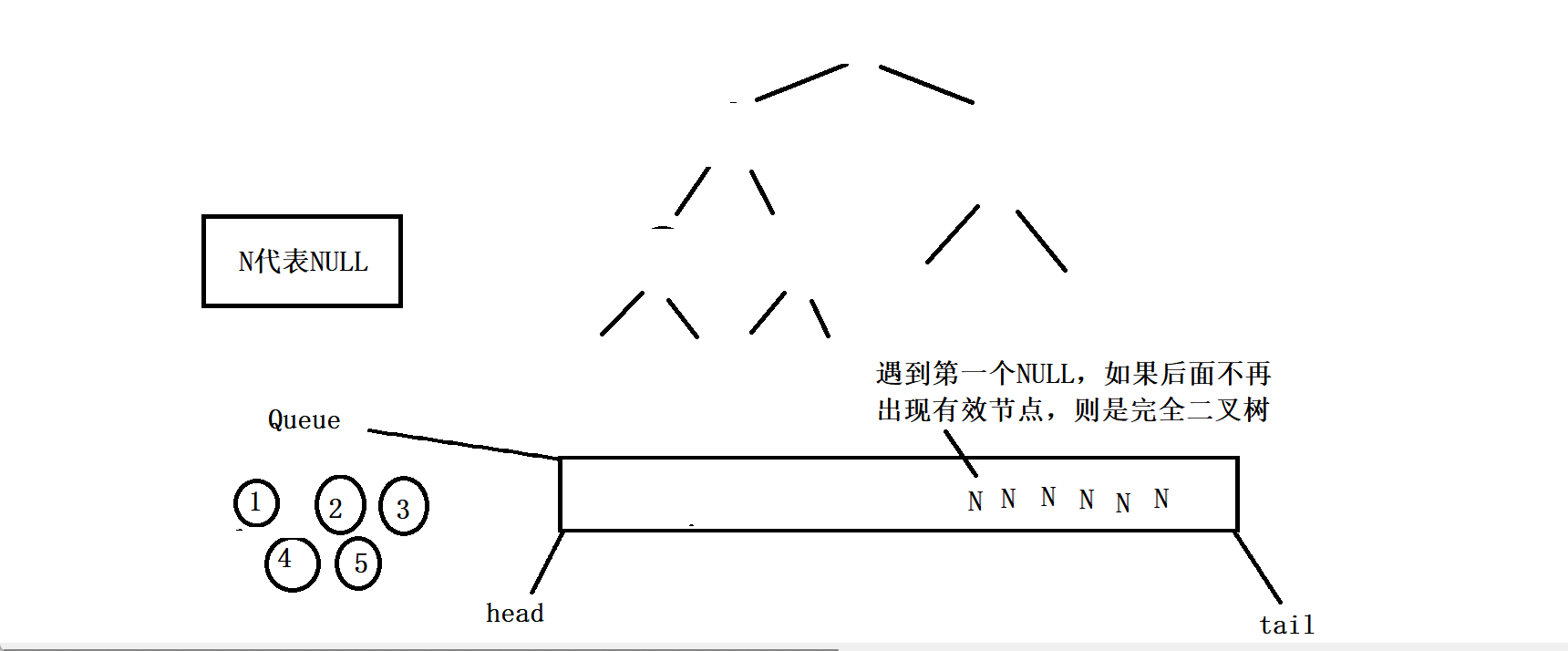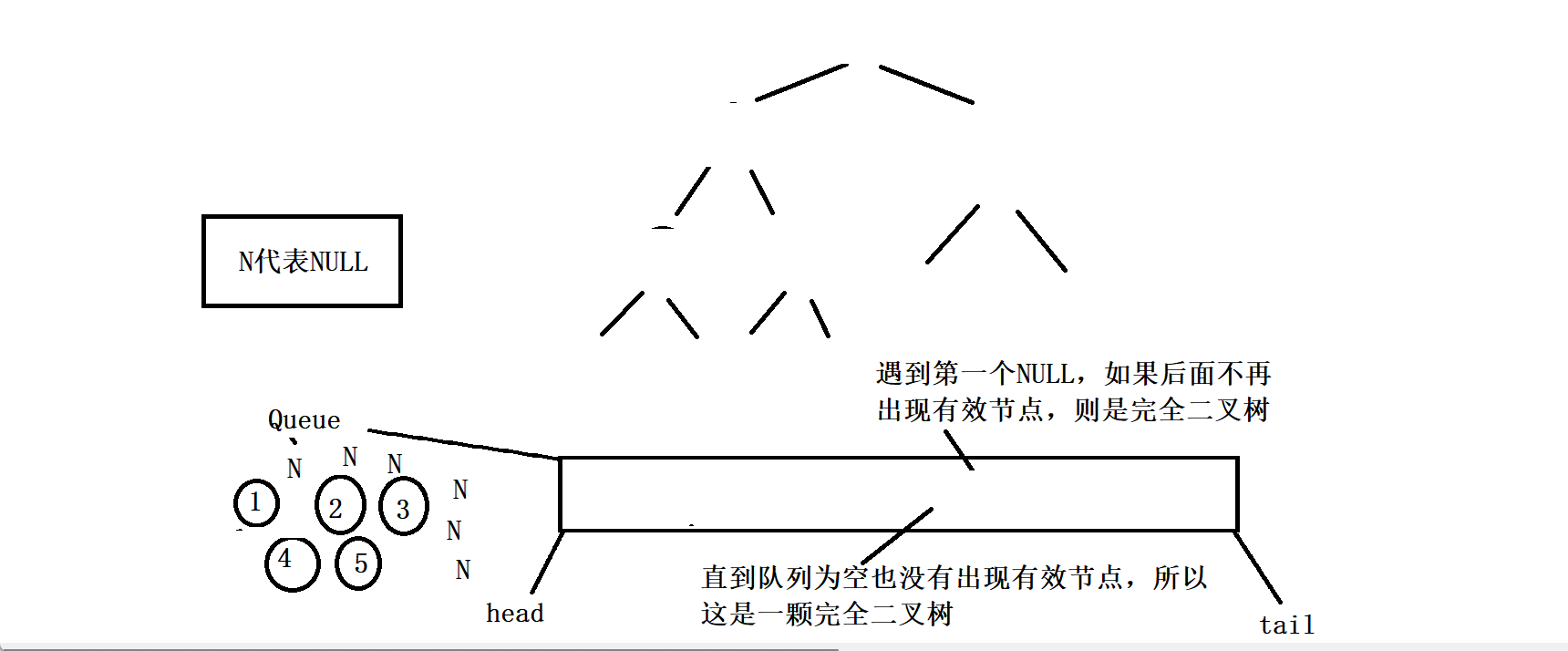
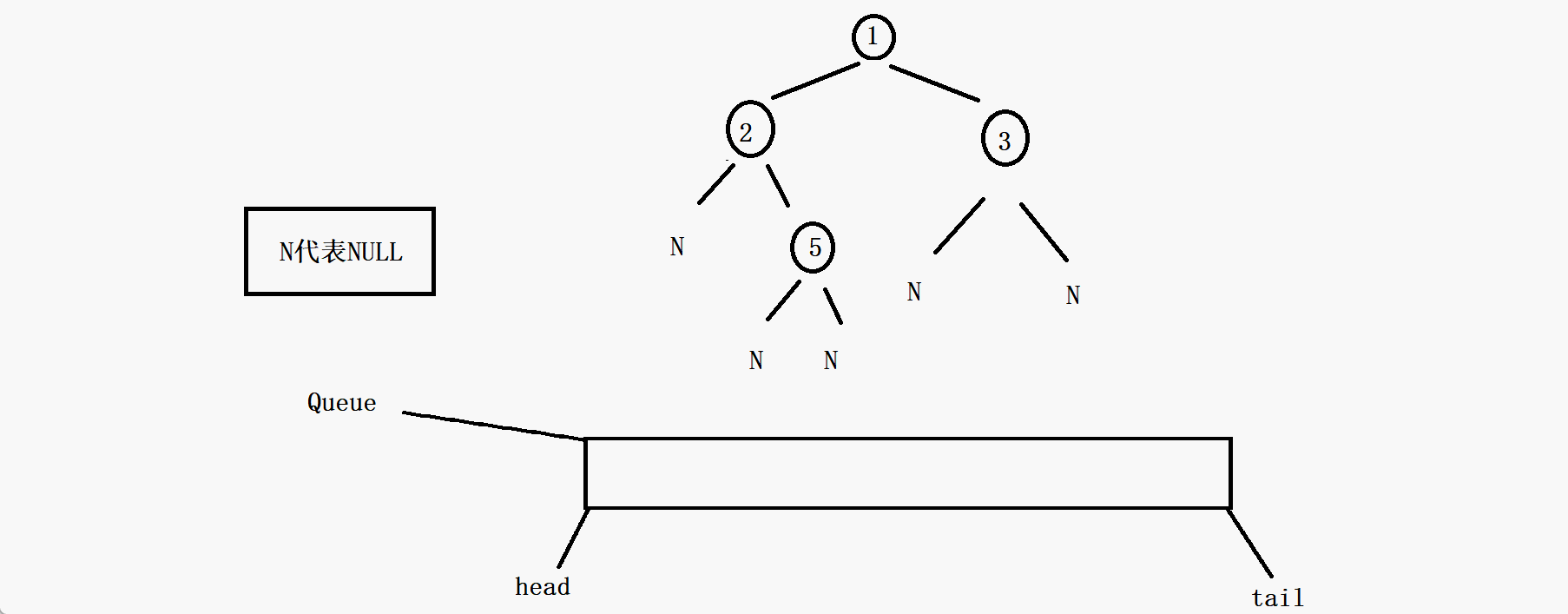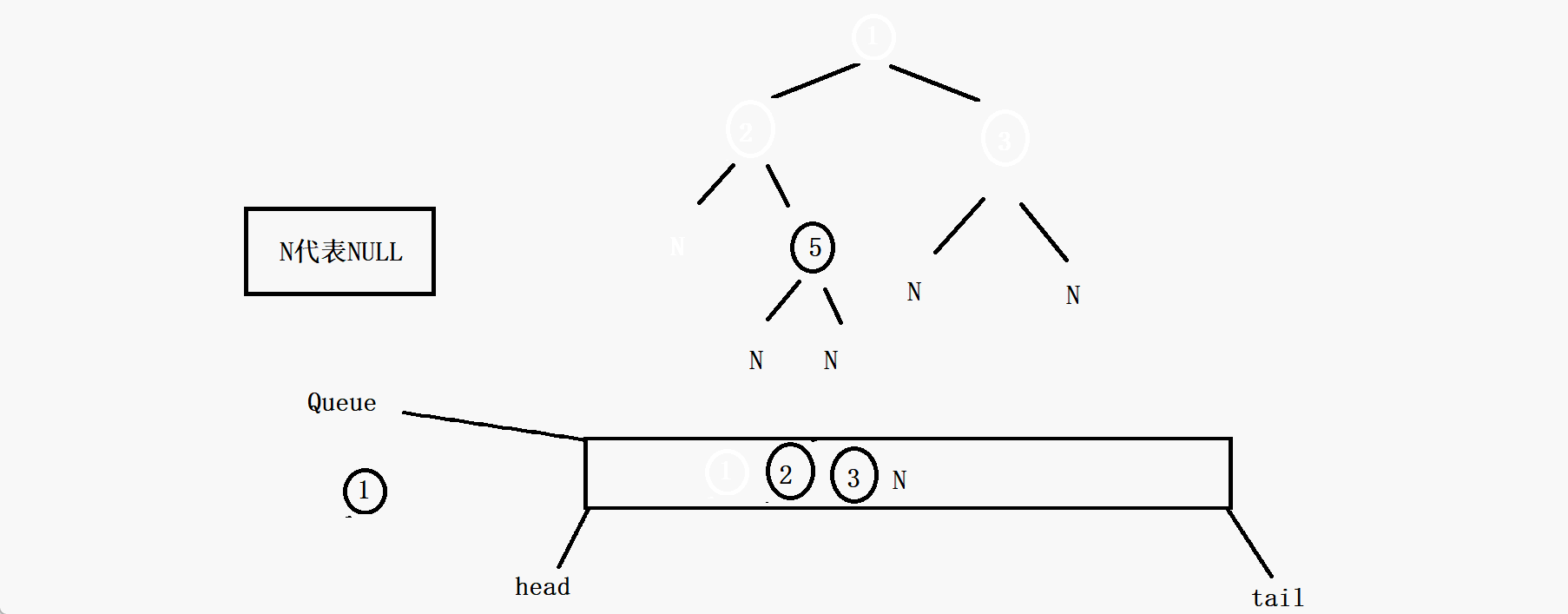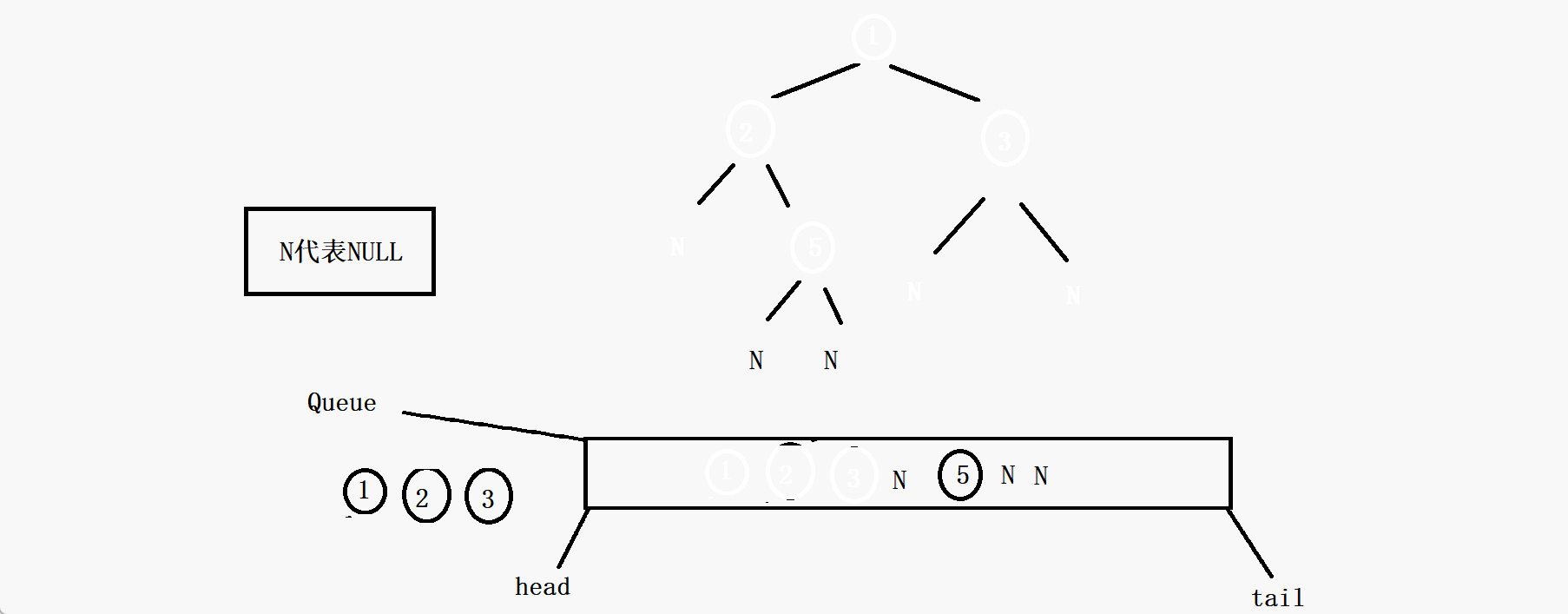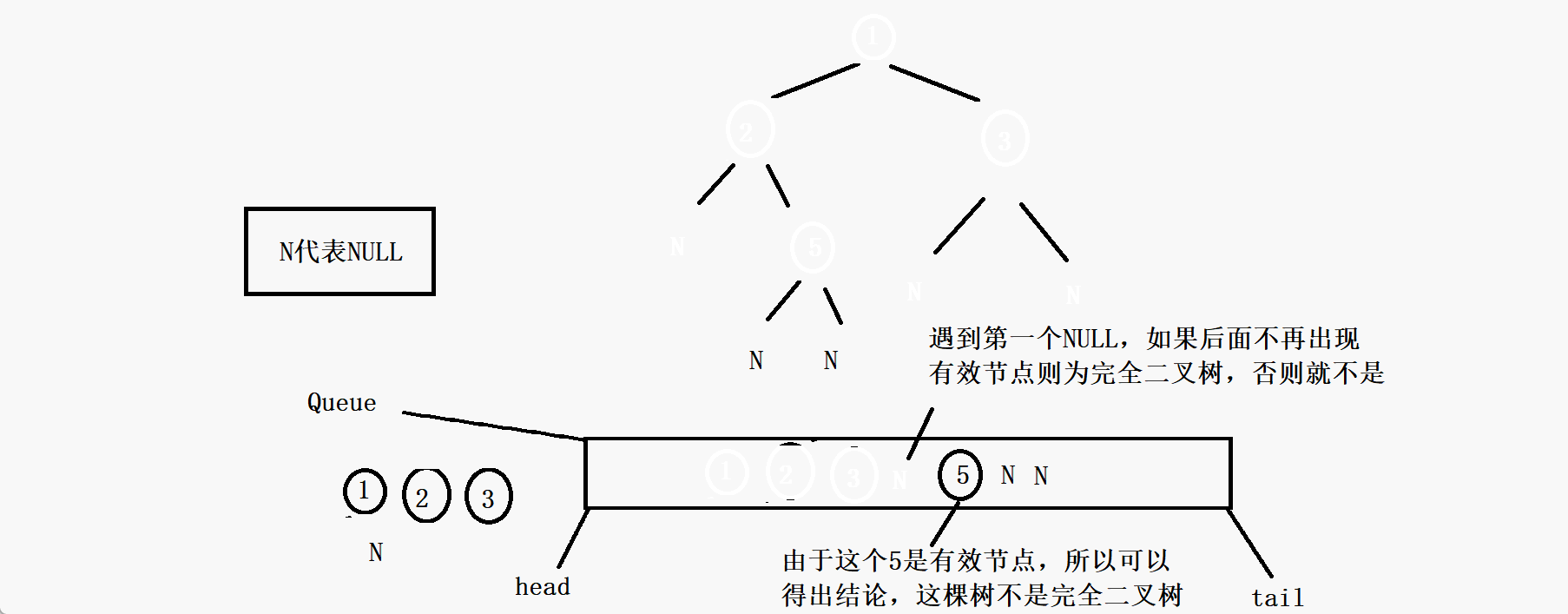
其实你会发现,这个判断一棵树是否为完全二叉树完全可以沿用二叉树的层序遍历的方法,因为完全二叉树的全部有效节点都是连续的,那么如果我们把二叉树的层序遍历的代码稍微修改一下,就是无论根节点的左子树和右子树是否为空都把它入队列,那么节点出队列的时候一旦遇到了NULL。如果队列中的这个空节点往后的节点中再出现有效节点(即不为NULL的节点),那么这棵树一定不是完全二叉树(由二叉树的性质决定的),如果队列一直出节点,直到队列为空也没有出现有效节点,那么这棵树就一定是完全二叉树。
bool BinaryTreeComplete(BTNode* root) { //如果是空树,那么也认为是完全二叉树 if (root == NULL) { return true; } //创建一个队列 Queue q; QueueInit(&q); QueuePush(&q, root); while (!QueueEmpty(&q)) { //取队列头的元素 BTNode* front = QueueFront(&q); //队头元素出队列 QueuePop(&q); //只要front不是NULL,就进它的左右孩子 if (front) { QueuePush(&q, front->left); QueuePush(&q, front->right); } //遇到空就可以跳出循环去判断是否为完全二叉树了 else { break; } } //只要队列不为空就一直判断是否存在有效节点 while (!QueueEmpty(&q)) { BTNode* front = QueueFront(&q); QueuePop(&q); //如果遇到不为空的节点,即有效节点,就判定不是完全二叉树 //返回false if (front) { QueueDestroy(&q); return false; } } //来到这里证明队列为空都没找到有效节点,证明该树是完全二叉树 QueueDestroy(&q); return true; }



