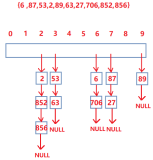
散列是一种以空间换时间的算法思想,以整数散列为列,其精髓就在于用其一个整数数组的下标对应操作输入的对象,要查找这个对象,就直接查找其对应的下标里面信息。
举个例子: 随便输入n个数a(0-100),再输入m个数b,查询他们在这n个数中出现了几次?
这个时候我们建立一个101大的整数数组t初始为0,直接以数组下标标识0-100的数,输入a时,令t[a]++就代表那个数查询了,查询的时候也方便,t[b]大小就是b出现的次数。
再问: 如果关键词不是整数,而是字符串或坐标等别的数据怎么办?
这时候,就要体现散列的精髓了- hash函数的构造,下面以字符串为例:
现在输入的不是数了,而是3个小写字母的单词,应该怎么办?
分析小写字母是a-b,共26位,如果把它们考虑成一个26进制数,转化为十进制就会有一个唯一十进制数与之对应,借此思想我们设计程序如下:
#include<iostream> #include<algorithm> using namespace std; const int maxn=26*26*26+1; int t[maxn]={0}; int hashfunc(char s[],int n) { //将字符串转化为十进制数,hash函数 int id=0; for(int i=0;i<n;i++) id=id*26+(s[i]-'a'); return id; } int main(){ char s[3]; int n; cin>>n; for(int i=0;i<n;i++) { for(int j=0;j<3;j++) cin>>s[j]; t[hashfunc(s,3)]++; } for(int j=0;j<3;j++) cin>>s[j]; cout<< t[hashfunc(s,3)]<<endl; return 0; }
一个结果:

显然,如果一个字符串数据太大,这样就不太适合,至于处理方法,我们将在字符串部分讲解