
此次是墨芯连续第二次问鼎 MLPerf,也是又一次 “12nm 战胜 4nm”。
ChatGPT 引爆大模型浪潮,也带来了算力挑战:当大模型进入大规模部署阶段,海量算力需求、推理加速等痛点,如何解决?
早在 2021 年,Google Research 和 OpenAI 的合作论文给出答案:《Sparse is Enough in Scaling Transformers》,证明稀疏计算能够为大模型带来数十倍加速。
4 月 6 日,全球权威 AI 基准评测 MLPerf Inference v3.0 公布的结果,再次佐证了:稀疏计算是大模型时代最不容忽视的算力 “潜力股”。

来自中国的 AI 芯片企业 —— 墨芯人工智能,凭借软硬协同的稀疏计算技术,在 MLPerf 竞争最激烈的 ResNet50 模型上蝉联冠军,斩获开放任务分区 “双料冠军”:S40 计算卡以 127,375 FPS,获得单卡算力全球第一;S30 计算卡以 383,520 FPS 算力,获整机 4 卡算力全球第一。
此次是墨芯连续第二次问鼎 MLPerf,也是又一次 “12nm 战胜 4nm”:墨芯 AI 计算卡系列是基于首颗稀疏计算芯片12nm的AntoumⓇ,性能超越了4nm制程产品,展现出稀疏计算的强大优势。
作为业界公认最为权威、标准严格的AI基准测试,本届MLPerf参与热度再创新高,共收到来自英伟达、高通、英特尔等25家企业提交的6700多份测试结果,其中最显著的变化当属旨在鼓励创新的开放分区,提交结果数达上一届的三倍之多。种种迹象表明,ChatGPT引爆的大模型趋势将算力产业推向变革关口,众多厂商都在积极探索新的算力增长之道,通过软硬协同、稀疏计算等新方式,以满足大模型迫切的巨量算力需求。
刷新纪录,稀疏计算引领算力突破
继去年 MLPerf 2.1 夺魁以后,本次墨芯在 MLPerf 上再次刷新算力纪录,连获 Resnet-50 单卡、多卡的性能第一,并在 Bert 语言模型上实现性能提升。在MLPerf相同模型、数据集、精度条件下,墨芯计算卡产品性能超过英伟达 H100 和 A100。
刷新算力纪录:墨芯 S40 计算卡首次亮相 MLPerf,在数据中心的图像任务主流模型 ResNet-50 上夺得冠军,算力达 127,375 FPS。S40 计算卡性能达英伟达 H100、A100 的 1.4 倍和 2.9 倍。

二度问鼎,优势持续扩大:这是墨芯第二次在 ResNet-50 模型上夺冠。墨芯 S40 计算卡比上届冠军 S30 计算卡的算力增幅达 33%,体现出持续的产品性能提升能力。与上一次 MLPerf 相比,墨芯产品相较 H100 和 A100 的算力优势分别扩大了 20% 和 90%。

单机 4 卡第一,算力超 8 张 A100:墨芯 30 计算卡获得 ResNet-50 模型 “整机 4 卡” 冠军,算力 383,520 FPS,达英伟达 H100 的 4 卡成绩的 1.8 倍,并且超过英伟达 A100 的 8 卡成绩。

在NLP模型BERT上,墨芯S40计算卡算力5,069 SPS达到英伟达提交的A100算力的2.7倍。

适配多服务器,发挥稳定:本次MLPerf中墨芯计算卡在多家厂商的服务器上的运行性能均表现出色、稳定,体现出产品的高成熟度与高兼容性,凸显出稀疏计算生态的广阔前景。
大幅加速推理,赋能 AIGC 等在线应用
随着 ChatGPT 等 AIGC 类应用的推广,加速推理速度、满足用户在线实时交互的需求,已成为大模型落地的一大痛点。在本次 MLPerf 中,墨芯 S30 与 S10 计算卡在离线(Offline)与在线(Server)两种模式下均表现优异,S30在ResNet-50和BERT的在线模式下算力分别达83,998(FPS)和3,009(SPS),展现出稀疏计算同时兼顾高吞吐、低延时的独特优势。

在推理加速方面,稀疏计算还具有更大的发挥空间。此前,墨芯人工智能创始人兼CEO王维在出席活动时透露:在墨芯内测中,在与GPT-3参数相当的开源LLM——1760亿参数的BLOOM上,4张墨芯S30计算卡在仅采用中低倍稀疏率的情况下,就能实现25 tokens/s的内容生成速度,超过8张A100。
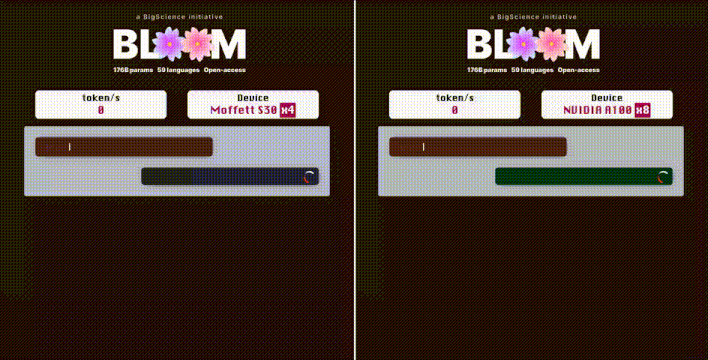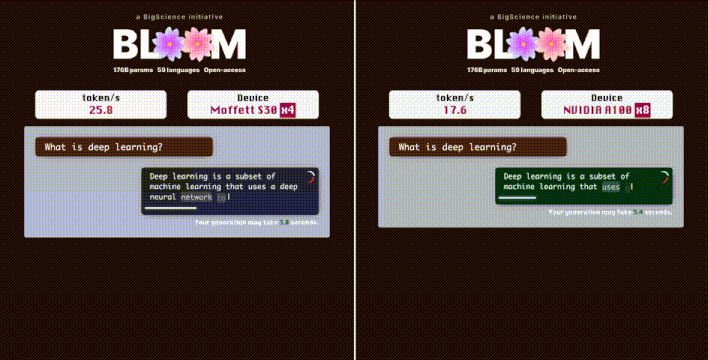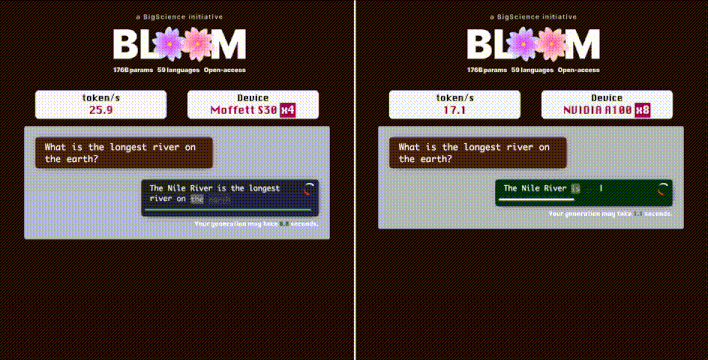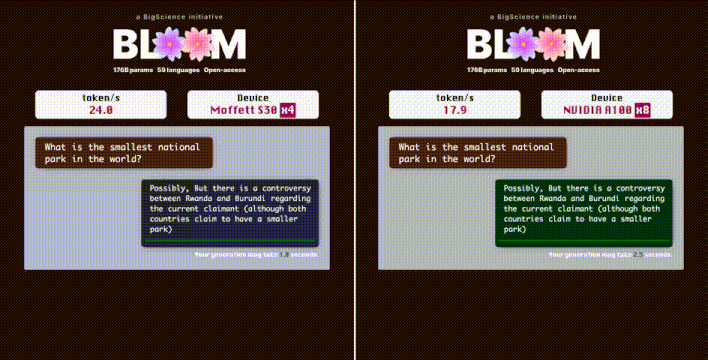
实测:在 1760 亿参数的 BLOOM 上,4 张墨芯 S30 计算卡的内容生成速度达到 25 tokens/s,超过 8 张 A100
蝉联冠军的背后,是行业深度洞察与强大技术加持
本次 MLPerf 的参与热度再创新高,在高手云集的激烈竞争中,墨芯连续两届蝉联 MLPerf 冠军,表明了产品的优秀稳定性能与持续领先的地位。不仅如此,此次距离上次 MLPerf 仅过去半年有余,墨芯就推出了新的 AI 计算卡产品,并且性能有大幅提升,凸显出强大的团队实力、工程化能力等综合实力。
产品的持续领先和稳步发展,是建立在对行业的深刻洞察与远见之上的。在 ChatGPT 火爆之前,墨芯团队已经观察到大模型的必然趋势,并笃定:稀疏计算是大模型时代的最佳算力方案。
“Transformers引发的大模型浪潮,代表着整个AI的划时代巨变:在那之前是小模型时代,也就是AI 1.0,以解析式AI为主;到了AI 2.0大模型时代,大模型推动了生成式AI应用场景的爆发。”王维表示,从AI 1.0到AI 2.0,对算力的需求产生质变:“小模型时代,用场景数据训练小模型,研发和部署周期短,对算力的需求主要是通用性、易用性。到了大模型时代,大模型主要基于Transformer模型架构,算子层面逐渐固化,更追求计算速度和算力成本等。”
王维指出,大模型时代的算力痛点主要集中在两点:首先是大算力,大模型参数呈指数级增长,算力需求爆发,产生巨大的算力缺口;另一方面是加快推理速度,由于生成式 AI 基本都是在线应用,系统对于用户的需求要在毫秒内快速响应。
“微创新是大公司做的事情。大模型参数已经突破万亿、并且持续增大,微创新无法根本解决问题。创业公司要做就做有数量级突破的颠覆式创新。墨芯成立之初,我们就看到了:稀疏计算能够带来数量级的性能增长。因此我们一直笃定,做一家稀疏计算公司。” 王维表示。此次墨芯在 MLPerf 的连续夺冠,正是用实际证明了稀疏计算的巨大应用价值,以 “12nm 战胜 4nm” 的成绩打开新的算力增长空间。
墨芯的判断,与业界、学界对稀疏计算的看好是相一致的:Transformers 带来大模型浪潮后,稀疏计算相关研究活跃度显著提升。学界与业界都积极将稀疏计算作为大模型算力破解的重要方向,例如谷歌对 AI 的终极愿景 ——Pathways 架构采用稀疏计算原理:执行任务时仅稀疏激活模型的特定部分,计算真正有用的元素,这正是稀疏计算的本质。

谷歌在《Introducing Pathways: A next-generation AI architecture》写道:“今天的模型是稠密和低效的,Pathways 将使它们变得稀疏和高效。” 英伟达也在其 Ampere 架构中首次支持 2 倍稀疏计算。墨芯则将稀疏计算从算法上升到软硬协同层面,2022 年发布首颗高稀疏倍率芯片 AntoumⓇ,能够支持 32 倍稀疏,大幅降低大模型所需的计算量。

MLPerf 参与情况也侧面印证了业界共识:算力提升不能再纯靠硬件,必须通过软硬协同的方式。本届 MLPerf 中开放分区的提交结果再创新高,高通、英特尔等头部企业也提交多项结果,开放分区的算力方案呈现丰富的多样性。
不仅在 MLPerf 上表现出色,墨芯的产品商业落地上也进展迅速。据王维透露,墨芯 AI 计算卡发布数月就已实现量产,在互联网等领域成单落地。ChatGPT 走红后墨芯也收到大量客户问询,了解稀疏计算在大模型上的算力优势与巨大潜力。
ChatGPT 被比尔・盖茨评价为 “其意义不亚于互联网和 PC 的诞生”,被黄仁勋称为 AI 的 “iPhone 时刻”。每一项应用普及的前提,都是由基础设施提供坚实支撑。在大模型时代,稀疏计算无疑是最有前景的最佳算力方案,引领 AI 2.0 时代的算力进化,加速生成式 AI 等应用百花齐放的未来。

