作者:林佳
用户背景
网易2001年正式成立在线游戏事业部,与广大游戏热爱者一同成长。经过近20年的快速发展,网易游戏(互娱)已跻身全球七大游戏公司之一。作为中国领先的游戏开发公司,网易互娱一直处于网络游戏自主研发领域的前端。
业务需求
说到网易互娱,大家首先想到的肯定是游戏。作为网易的核心业务线之一,让游戏业务可以稳定可靠地运行自然是重中之重,而游戏业务中最重要就是 APP 内购买服务的可靠性。

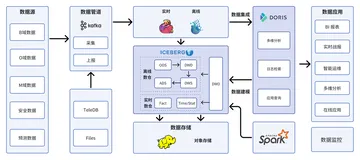
玩家在游戏内购买道具的操作,首先会触发客户端行为与渠道商、计费中心进行通讯,完成下单与支付。计费中心也会与渠道商进行交互,验证客户端订单的合法性以及支付状态。只有订单合法,游戏服务才会被通知发货。而这一整套流程下来,每一个参与者产生的日志、数据监控点等等,它们的来源、数据结构、时间步调可能是千差万别的。此外,这个过程中还有通讯网络、数据库、监控系统等的参与,使得整个过程非常复杂。

2017 年之前网易互娱的处理方式相对落后,其中还有一些比较陈旧的处理方式,比如网盘、rsync、T+1 处理离线任务等。

组件繁多、技术栈的割裂、时效性低、资源使用情况粗糙等,都会使资源无法被均匀地利用,而这正是带来时效性低的原因之一,也使代码能效、数据能效和资源能效都相对较低。

上图是网易互娱以前的离线计算业务运行时的资源情况示意,在凌晨的时候去计算前一天的数据报表。在流式计算普及之前,这是一种广泛使用的模式,即在凌晨用一大批机器执行 Spark 离线任务去计算前一天的结果。为了使报表可以按时交付,整个离线集群需要大算力,堆叠大量的机器资源,而这些机器资源在许多时间段却是空闲的,这便造成了资源能效低下。如果这类计算任务可以被实时化,那么它所需要的算力即可被分摊到每一个时间片上,避免在凌晨的时候资源使用严重倾斜。这些机器算力可以被托管在资源管理的平台上,所以它们也可以被其他业务所使用,进而提升能效。
《Apache Flink 案例集(2022版)》——2.数据分析——网易互娱-基于Flink 的支付环境全关联分析实践(下)https://developer.aliyun.com/article/1228388