作者:张杨
用户背景
哔哩哔哩是中国年轻一代的标志性品牌及领先的视频社区。网站创立于2009年6月,并于2010年1月正式命名为“哔哩哔哩”,提供全方位的视频内容以满足用户多元化的兴趣喜好,并且围绕着有文化追求的用户、高质量的内容、有才华的内容创作者以及他们之间的强大情感纽带,构建了bilibili的社区。
业务需求
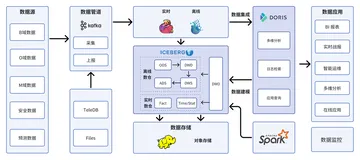
B站围绕 Flink 主要做了三个方面的工作:平台建设、增量化和 AI on Flink。实时平台是实时业务的技术底座,也是 Flink 面向用户的窗口,需要坚持持续迭代优化,不断增强功能,提升用户效率。增量化是B站在增量化数仓和流批一体上的尝试,在实时和离线之间找到一个更好的平衡,加速数仓效率,解决计算口径问题。AI 方向B站也正在结合业务做进一步的探索,与 AIFlow 社区进行合作,完善优化机器学习工作流。
生产实践
1. 平台建设
在平台的基础功能方面,B站做了很多新的功能和优化。其中两个重点是支持 Kafka 的动态 sink 和任务提交引擎的优化。
B站存在大量如下的 ETL 场景:业务的原始实时数据流是一条较大的混合数据流,包含了数个子业务数据。数据通过 Kafka 传输,末端的每个子业务都对应单独的处理逻辑,每个子业务都去消费全量数据,再进行过滤,这样的资源消耗对业务来说是难以接受的,Kafka 的 IO 压力也很大。因此我们会开发一个 Flink 任务,对混合数据流按照子业务进行拆分,写到子业务对应的 topic 里,让业务使用。
技术实现上,早期 Flink SQL 的写法就是写一个 source 再写多个 sink,每个 sink 对应一个业务的 topic,这确实可以满足短期的业务诉求,但存在数据倾斜、无法动态增减sink和维护成本高的问题。

为了解决相关问题,B站开发了一套 Kafka 动态 sink 的功能,支持在一个 Kafka sink 里面动态地写多个 topic 数据,架构如上图。该功能对 Kafka 表的 DDL 定义进行了扩展,在 topic 属性里支持了 UDF 功能,它会根据入仓的数据计算出这条数据应该写入哪个 Kafka 集群和 topic。sink 收到数据后会先调用 UDF 进行计算,拿到结果后再进行目标集群和 topic 数据的写入,这样业务就不需要在 SQL 里编写多个 sink,代码很干净,也易于维护,并且这个 sink 被所有 topic 共用,不会产生倾斜问题。UDF 直接面向业务系统,分流规则也会平台化,业务方配置好规则后,分流实施自动生效,任务不需要做重启。

第二个优化是任务的提交引擎优化,这主要是因为本地编译、多版本支持、UDF加载和代码包传输效率四个方面的问题。相关的优化内容如下:
首先引入了 1.11 版本以上支持的 application 模式,这个模式与 per-job 最大的区别就是 Flink 任务的编译全部移到了 APP master 里做,这样就解决了提交引擎的瓶颈问题;
在多版本的支持上面,B站对提交引擎也做了改造,把提交器与 Flink 的代码彻底解耦,所有依赖 Flink 代码的操作全部抽象了标准的接口放到了 Flink 源码侧,并在 Flink 源码侧增加了一个模块,这个模块会随着 Flink 的版本一起升级提交引擎,对通用接口的调用全部进行反射和缓存,在性能上也是可接受的;此外,Flink的多版本源码全部按照 maled 模式进行管理,存放在 HDFS。按照业务指定的任务版本,提交引擎会从远程下载 Flink 相关的版本包缓存到本地,所以只需要维护一套提交器的引擎。Flink 任何变更完全和引擎无关,升级版本提交引擎也不需要参与;
完成 application 模式升级后,B站对 UDF 和其他资源包的上传下载机制也进行了修改,通过 HDFS 远程直接分发到 JM/TM 上,减少了上传下载次数,同时也避免了 cluster 的远程加载。