作者:何军
用户背景
小红书是年轻人的生活方式平台,由毛文超和瞿芳于2013年在上海创立。小红书以“Inspire Lives 分享和发现世界的精彩”为使命,用户可以通过短视频、图文等形式记录生活点滴,分享生活方式,并基于兴趣形成互动。截至到2019年10月,小红书月活跃用户数已经过亿,其中70%用户是90后,并持续快速增长。
平台现状

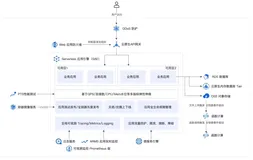
小红书的Flink集群多云部署架构如上图所示,由于小红书的业务数据分散在各个云厂商之上,为了适配业务数据处理,Flink 集群自然也进行了多云部署。具体来说,小红书在阿里云、腾讯云和华为云上均有K8s集群,并相应的使用了OSS/COS/OBS等不同云厂商的对象存储产品。这些云存储产品一方面用于内部的离线数据存储,另外一方面会用于 Flink 做 checkpoint 存储使用。在这些云基础设施之上,小红书搭建了 Flink 引擎支持 SQL 及 JAR 任务的运行,得益于之前做的一项推动任务 SQL 化的工作,当前内部 SQL 任务和 JAR 任务比例已经达到了 9:1。
在此之上是流批一体作业管控平台,它主要有以下几个功能:作业开发运维、任务监控报警、任务版本管理、数据血缘分析、元数据管理、资源管理等。
平台数据输入主要有以下三个部分,第一部分是业务数据,存在于业务内部的 DB 系统里比如 MySQL 或者 MongoDB,还有一部分是前后端打点数据,前端打点主要是用户在小红书 APP 端的行为日志,后端打点主要是 APP 内部应用程序性能指标相关的数据。这些数据经过 Flink 集群处理之后,会输出到三个主要业务场景中,首先是消息总线,比如 Kafka 集群以及 RocketMQ 集群,其次会输出到 olap 引擎中,比如 StarRocks 或 Clickhouse,最后会输出到在线系统,比如 Redkv 或者 ES 供一些在线查询使用。
业务场景
Flink 在小红书内部的应用场景有很多,比如实时反欺诈监控、实时数仓、实时算法推荐、实时数据传输,这里着重介绍一下其中两个场景。

第一个是实时推荐算法训练。上图是推荐算法训练的执行流程。Flink 集群先接收打点服务采集过来的原始数据,对这一部分数据进行归因并将它写入到 Kafka 集群,接下来另一个 Flink 任务会对这部分数据再做一次汇总,然后得到一个 Summary 的标签数据。针对这个标签数据,后面还有三条实时处理路径:
首先,Summary 标签数据会和推荐引擎推荐出来笔记的特征数据进行关联,这个关联也是在 Flink 任务中进行的,内部称其为 FeatureJoiner 任务。接着会产出一个算法训练的样本,这个样本经过算法训练之后产出一个推荐模型,而这个模型最终会反馈到实时推荐引擎中;
其次,Summary 标签数据会通过 Flink 实时写到 OLAP 引擎中,比如写到 Hologres 或 Clickhouse 中;
最后, Summary 标签数据会通过 Flink 写入到离线 Hive 表中,提供给后续离线报表使用。

第二个场景是实时数仓。业务数据包括前后端打点的数据,按照业务分流规则进行处理之后会写入到 Kafka 或者 RocketMQ 中,后续 Flink 会对这部分数据做实时 ETL 业务处理,最终进入实时数据中心。目前实时数据中心主要是基于 StarRocks 实现的,StarRocks 是一个性能十分强大的 OLAP 引擎,它承载了公司很多实时相关业务。在数据中心之上,我们还支撑了很多重要实时指标,比如实时 DAU、实时 GMV、实时直播归因、实时广告计费等。
《Apache Flink 案例集(2022版)》——4.云原生——小红书-Native Flink on Kubernetes 在小红书的实践(2) https://developer.aliyun.com/article/1228080