三、 应用运维Flink Job

伴随着实时计算的大趋势,Flink的用户和作业数经历了飞速增长,现在平台上的作业数已经达到了几万个。但是众所周知Flink作业的运维是一个非常复杂的问题,列举一些日常用户最高频的咨询,比如为什么我的作业启动慢,为什么Failover,为什么反压,为什么延时,如何调整资源配置来减少成本?这些看似简单的问题其实都非常复杂。
Flink的作业运维难点有两个方面:一方面是分布式系统全链路组件很多,依赖很复杂。另一方面是Flink自身尤其是涉及到RunTime层面时,原理很复杂。所以我们希望将我们自身丰富的运维知识,包括对系统全链路的调用流程,各个组件工作原理的深入理解,也包括日常和双11大促中丰富的排查问题的经验,以及优秀的排查思路,全部转化为数据和规则算法,沉淀为运维产品功能。
这个产品主要有两个功能,一个是Flink Job Adviser,用来发现和诊断作业的异常;另一个是Flink Job Operator,用来修复作业的异常。两者配套一起来解决Flink作业运维的难题。

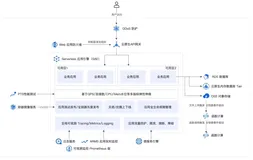
上图是Flink Job Adviser最终呈现给用户的效果。用户只需输入作业名或链接,@一个机器人,就会调用Adviser服务。
比如Case1,作业由于资源不足无法启动,adviser会给出诊断结果,是由于某个作业资源不足,并附上改进建议,让用户去控制台扩容对应的资源数量。
比如Case2,用户的某一个作业failover了,他想知道为什么。通过全域数据的关联,Adviser给出的结果是由于平台侧机器下线或硬件故障自愈导致的,建议用户无需做任何操作,等待自动化的恢复即可。
再比如Case3,由于用户作业内存配置不合理,频繁出现OOM导致failover。Adviser就会建议用户去调整对应计算节点的内存配置,避免新的failover。

Filnk job Adviser背后还有几十种针对复杂场景的异常诊断能力,构成了一个庞大的经验决策树。它不仅能够定位正在发生的异常,还有能力预防异常,主要由三部分组成:
• 事前部分,通过作业的运行指标和系统的全域事件来做预测,提前发现风险隐患,达到预防的效果,比如有作业发现的failover或者版本有问题等,这些异常还没有真正影响作业,通过体检能够发现这些问题。
• 事中部分,针对作业运行的全生命周期做诊断,包括启停类的问题,比如启动报错、启动慢、停止报错等,还包括运行起来性能不足、延时以及运行过程报错、数据一致性、准确性等问题。
• 事后部分,支持用户对于历史作业做全量的回溯。比如说想看昨天半夜failover的原因。

在决策树的具体实现里,选择了几个典型的、有复杂度的节点来进行分享。
• 第一个是作业全生命周期状态检查,一个作业从控制台提交到资源分配,再到运行环境、依赖下载,再到Top的创建,到上下游的加载,最后数据处理,整个链路是一个非常复杂的流程,adviser就是把关键节点的耗时和全量的事件统一收集起来进行分析,最终能够做到在作业任何状态做异常诊断和定位。
• 第二个是作业运行态性能类的问题,主要针对各类实时监控指标做异常检测,或通过经验值、域值的判断来发现和分析异常。比如作业延时了,那就通过节点找到反压所在的节点,再找到TM所在的节点,然后分析机器异常,最后发现可能是某台机器load高。以此形成整个链路证据链的推导,做到关联下钻分析,定位到真实的根因。
• 第三个就是最高频的问题,作业在运行过程中有报错。核心的思路是收集各个组件的日志,比如提交的日志、调度的日志、failover和有JM和TM的日志,将这些海量的异常日志通过日志聚类的算法,包括自然语言处理和实际提取,来将一些非结构化的日志变成结构化的数据,再合并同类项进行压缩,最后由SRE和研发来进行原因标注和建议,形成一套完善的专家经验。
最早决策树的实现都是静态的规则,但随着场景的复杂化,尤其是数据的暴增以及个性化场景的出现,静态规则无法再满足我们的需求,比如每个作业的延迟都是个性化的、报错无法再通过正则匹配来维护。我们正在积极尝试引入各种AI来解决这些个性化的问题。

通过Filnk job Adviser定位异常后,就需要Filnk job Operator来修复异常,形成一个闭环。
Operator能力主要由4大部分组成:
• 第一种能力是升级,对作业问题版本进行透明升级以及配置的热更新,来解决作业在代码和配置等稳定性方面的隐患和异常。
• 第二种能力是优化,基于阿里内部的Autopilot来对作业进行性能的配置调优,从而帮助用户作业解决性能和成本的问题。
• 第三种能力是迁移,作业通过跨集群透明迁移,主要帮助用户在大规模作业场景下达到作业的高效管理。
• 最后一种是自愈修复,根据 Adviser 诊断出的各种风险和规则,配套有一键修复的自愈能力。

随着实时计算的发展,运维也经历了从人肉、工具化、平台化、智能化到云原生化的演进升级,我们一直秉承的思路是将丰富的实时计算运维经验能力全部沉淀到实时计算管控产品上,来解决超大规模实时计算运维的难题。
在整个体系中,最中间是集群和应用两个运维对象,外围的运维的目标和运维的价值一直都是围绕着稳定、成本、效率三大目标。运维的体系、技术和产品的载体,则是实时计算管控,通过实时计算管控来服务好上层的实时计算用户和产研、SRE还有我们自己。同时运维管控的技术内核正在全力往智能化和云原生化演进。
一句话总结,以智能和云原生为技术内核,建设实时计算运维管控产品,来解决超大规模Flink集群运维和应用运维碰到的稳定、成本、效率三大难题。