本周主要论文包括:上海交通大学、Digital Brain Lab、牛津大学等的研究者用新型 Transformer 架构解决多智能体强化学习问题;ICRA 2022 最佳论文出炉,美团无人机团队获唯一最佳导航论文奖等研究。
目录
- Multi-Agent Reinforcement Learning is A Sequence Modeling Problem
- StyleGAN-XL: Scaling StyleGAN to Large Diverse Datasets
- End-to-end symbolic regression with transformers
- EDPLVO: Efficient Direct Point-Line Visual Odometry
- A Ceramic-Electrolyte Glucose Fuel Cell for Implantable Electronics
- An Evolutionary Approach to Dynamic Introduction of Tasks in Large-scale Multitask Learning Systems
- Bridging Video-text Retrieval with Multiple Choice Questions
- ArXiv Weekly Radiostation:NLP、CV、ML 更多精选论文(附音频)
论文 1:Multi-Agent Reinforcement Learning is A Sequence Modeling Problem
- 作者:Muning Wen 、 Jakub Grudzien Kuba 等
- 论文地址:https://arxiv.org/pdf/2205.14953.pdf
摘要:如何用序列模型解决 MARL(多智能体强化学习) 问题?来自上海交通大学、Digital Brain Lab、牛津大学等的研究者提出一种新型多智能体 Transformer(MAT,Multi-Agent Transformer) 架构,该架构可以有效地将协作 MARL 问题转化为序列模型问题,其任务是将智能体的观测序列映射到智能体的最优动作序列。
本文的目标是在 MARL 和 SM 之间建立桥梁,以便为 MARL 释放现代序列模型的建模能力。MAT 的核心是编码器 - 解码器架构,它利用多智能体优势分解定理,将联合策略搜索问题转化为序列决策过程,这样多智能体问题就会表现出线性时间复杂度,最重要的是,这样做可以保证 MAT 单调性能提升。与 Decision Transformer 等先前技术需要预先收集的离线数据不同,MAT 以在线策略方式通过来自环境的在线试验和错误进行训练。
为了验证 MAT,研究者在 StarCraftII、Multi-Agent MuJoCo、Dexterous Hands Manipulation 和 Google Research Football 基准上进行了广泛的实验。结果表明,与 MAPPO 和 HAPPO 等强基线相比,MAT 具有更好的性能和数据效率。此外,该研究还证明了无论智能体的数量如何变化,MAT 在没见过的任务上表现较好,可是说是一个优秀的小样本学习者。
在本节中,研究者首先介绍了协作 MARL 问题公式和多智能体优势分解定理,这是本文的基石。然后,他们回顾了现有的与 MAT 相关的 MARL 方法,最后引出了 Transformer。
MAT 中包含了一个用于学习联合观察表示的编码器和一个以自回归方式为每个智能体输出动作的解码器。

MAT 中的详细数据流如下动图所示。
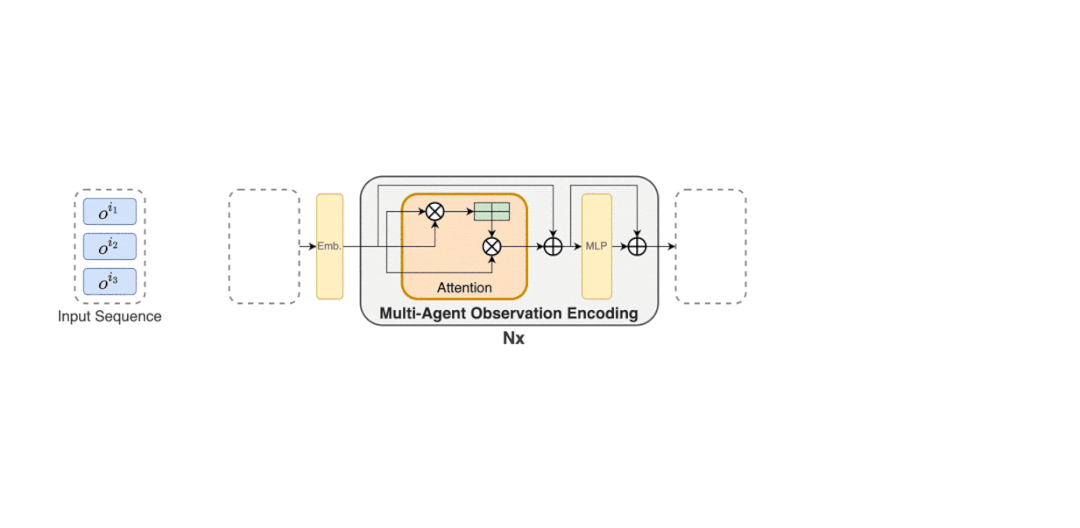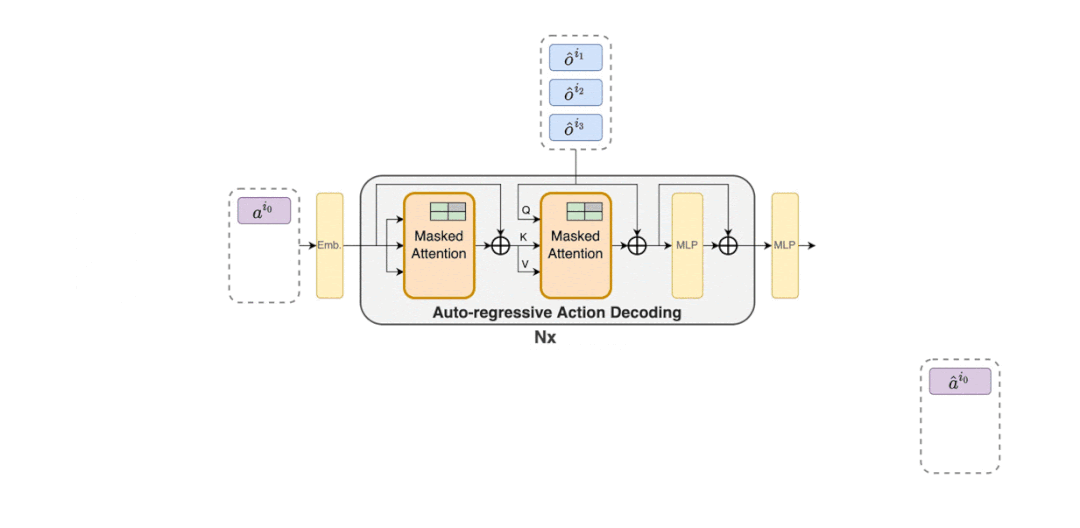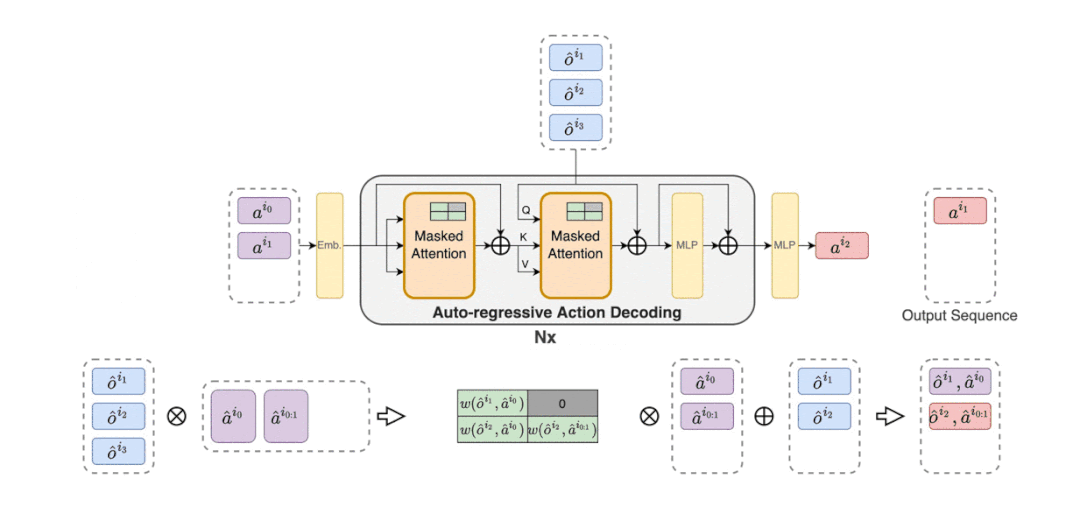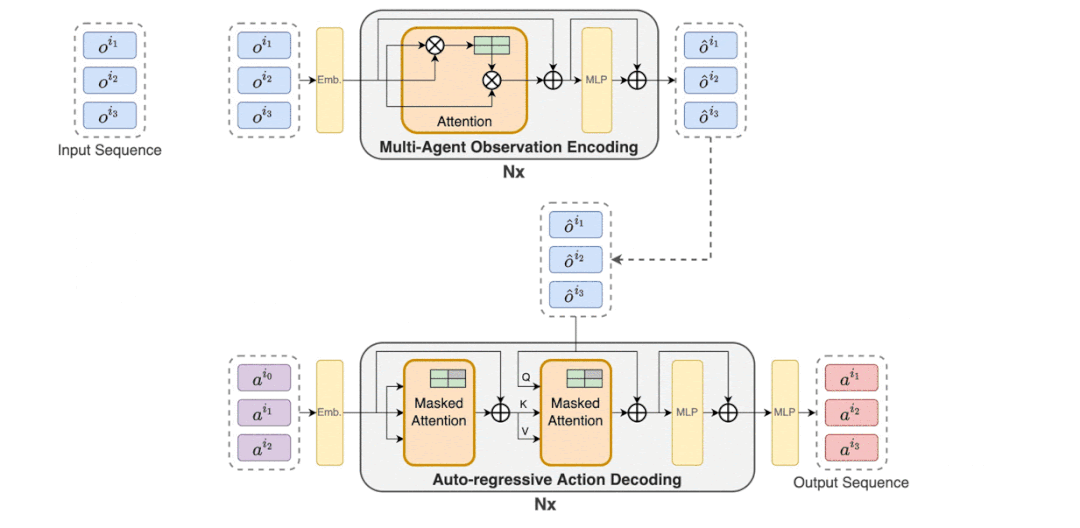
推荐:星际争霸 II 协作对抗基准超越 SOTA,新型 Transformer 架构解决多智能体强化学习问题。
论文 2:StyleGAN-XL: Scaling StyleGAN to Large Diverse Datasets
- 作者:AXEL SAUER、KATJA SCHWARZ、ANDREAS GEIGER
- 论文地址:https://arxiv.org/pdf/2202.00273.pdf
摘要:近日,英伟达提出了一种新的架构变化,并根据最新的 StyleGAN3 设计了渐进式生长的策略。研究者将改进后的模型称为 StyleGAN-XL,该研究目前已经入选了 SIGGRAPH 2022。
这些变化结合了 Projected GAN 方法,超越了此前在 ImageNet 上训练 StyleGAN 的表现。为了进一步改进结果,研究者分析了 Projected GAN 的预训练特征网络,发现当计算机视觉的两种标准神经结构 CNN 和 ViT [ Dosovitskiy et al. 2021] 联合使用时,性能显著提高。最后,研究者利用了分类器引导这种最初为扩散模型引入的技术,用以注入额外的类信息。
总体来说,这篇论文的贡献在于推动模型性能超越现有的 GAN 和扩散模型,实现了大规模图像合成 SOTA。论文展示了 ImageNet 类的反演和编辑,发现了一个强大的新反演范式 Pivotal Tuning Inversion (PTI)[ Roich et al. 2021] ,这一范式能够与模型很好地结合,甚至平滑地嵌入域外图像到学习到的潜在空间。高效的训练策略使得标准 StyleGAN3 的参数能够增加三倍,同时仅用一小部分训练时间就达到扩散模型的 SOTA 性能。
这使得 StyleGAN-XL 能够成为第一个在 ImageNet-scale 上演示 1024^2 分辨率图像合成的模型。

实验表明,即使是最新的 StyleGAN3 也不能很好地扩展到 ImageNet 上,如图 1 所示。特别是在高分辨率时,训练会变得不稳定。因此,研究者的第一个目标是在 ImageNet 上成功地训练一个 StyleGAN3 生成器。成功的定义取决于主要通过初始评分 (IS)[Salimans et al. 2016] 衡量的样本质量和 Fréchet 初始距离 (FID)[Heusel et al. 2017] 衡量的多样性。在论文中,研究者也介绍了 StyleGAN3 baseline 进行的改动,所带来的提升如下表 1 所示:

StyleGAN-XL 在深度和参数计数方面比标准的 StyleGAN3 大三倍。然而,为了在 512^2 像素的分辨率下匹配 ADM [Dhariwal and Nichol 2021] 先进的性能,在一台 NVIDIA Tesla V100 上训练模型需要 400 天,而以前需要 1914 天。(图 2)。

推荐:英伟达公布 StyleGAN-XL:参数量 3 倍于 StyleGAN3,计算时间仅为五分之一。
论文 3:End-to-end symbolic regression with transformers
- 作者:Pierre-Alexandre Kamienny、Stéphane d'Ascoli 等
- 论文地址:https://arxiv.org/abs/2204.10532
摘要:符号回归,即根据观察函数值来预测函数数学表达式的任务,通常涉及两步过程:预测表达式的「主干」并选择数值常数,然后通过优化非凸损失函数来拟合常数。其中用到的方法主要是遗传编程,通过多次迭代子程序实现算法进化。神经网络最近曾在一次尝试中预测出正确的表达式主干,但仍然没有那么强大。
在近期的一项研究中,来自 Meta AI(Facebook)、法国索邦大学、巴黎高师的研究者提出了一种 E2E 模型,尝试一步完成预测,让 Transformer 直接预测完整的数学表达式,包括其中的常数。随后通过将预测常数作为已知初始化提供给非凸优化器来更新预测常数。
该研究进行消融实验以表明这种端到端方法产生了更好的结果,有时甚至不需要更新步骤。研究者针对 SRBench 基准测试中的问题评估了该模型,并表明该模型接近 SOTA 遗传编程的性能,推理速度提高了几个数量级。
该研究提出了一个嵌入器( embedder )来将每个输入点映射成单一嵌入。嵌入器将空输入维度填充(pad)到 D_max,然后将 3(D_max+1)d_emb 维向量馈入具有 ReLU 激活的 2 层全连接前馈网络 (FFN) 中,该网络向下投影到 d_emb 维度,得到的 d_emb 维的 N 个嵌入被馈送到 Transformer。
该研究使用一个序列到序列的 Transformer 架构,它有 16 个 attention head,嵌入维度为 512,总共包含 86M 个参数。像《 ‘Linear algebra with transformers 》研究中一样,研究者观察到解决这个问题的最佳架构是不对称的,解码器更深:在编码器中使用 4 层,在解码器中使用 16 层。该任务的一个显著特性是 N 个输入点的排列不变性。为了解释这种不变性,研究者从编码器中删除了位置嵌入。
如下图 3 所示,编码器捕获所考虑函数的最显著特征,例如临界点和周期性,并将专注于局部细节的短程 head 与捕获函数全局的长程 head 混合在一起。

推荐:来自 Mata AI、法国索邦大学、巴黎高师的研究者成功让 Transformer 直接预测出完整的数学表达式。
论文 4:EDPLVO: Efficient Direct Point-Line Visual Odometry
- 作者:Lipu Zhou 、 Guoquan Huang 、 Yinian Mao 等
- 论文地址:https://www.cs.cmu.edu/~kaess/pub/Zhou22icra.pdf
摘要:国际机器人技术与自动化会议 ICRA 2022 于 5 月 23 日至 5 月 27 日在美举办,这是 Robotics(机器人学)领域最顶级的国际会议之一。美团无人机团队一篇关于视觉里程计的研究获得了大会导航领域的年度最佳论文(Outstanding Navigation Paper),这也是今年唯一一篇第一作者和第一单位均来自中国境内科技公司和高校的获奖论文。
在这篇论文中,作者提出了一种使用点和线的高效的直接视觉里程计(visual odometry,VO)算法—— EDPLVO 。他们证明了,2D 线上的 3D 像素点由 2D 线端点的逆深度决定,这使得将光度误差扩展到线变得可行。与该团队之前的算法 DPLVO 相比,新算法大大减少了优化中的变量数量,而且充分利用了共线性。在此基础上,他们还引入了一个两步优化方法来加快优化速度,并证明了算法的收敛性。
实验结果表明,该算法的性能优于目前最先进的直接 VO 算法。这项技术将在以无人机、自动配送车为代表的机器人自主导航以及 AR/VR 等领域进行广泛应用。该研究提出了一种新的算法——EDPLVO。

文章的主要贡献如下:
他们将光度误差扩展到了线。原来的光度误差只针对点定义,很难应用到线。与 DPLVO 中简单地将共线约束引入成本函数不同,他们提出了一种参数化 3D 共线点的新方法,从而使得将光度误差扩展到线变得可行。具体来说,他们证明了 2D 线上任意点的 3D 点由 2D 线两个端点的逆深度决定。该属性可以显著减少变量的数量。同时,该方法在优化过程中严格满足共线约束,这提高了准确率。
他们引入了一个两步骤方法来限制由于在优化中引入长期线关联而导致的计算复杂度。在每次迭代中,他们首先使用固定的逆深度和关键帧姿态来拟合 3D 线。然后,他们使用新的线参数来调节逆深度和关键帧姿态的优化结果。由此产生的两个优化问题很容易解决。研究者证明了该方法总是可以收敛的。

推荐:ICRA 2022 最佳论文出炉:美团无人机团队获唯一最佳导航论文奖。