

新智元报道
编辑:桃子 拉燕
【新智元导读】Meta简直杀疯了!多模态「千脑智能」ImageBind来了,能够像人的感官一样,从多种维度理解世界。
前段时间,带着开源LLaMA杀疯的Meta,让谷歌都后背发凉。今天,Meta又丢下了重量级炸弹:
拥有「多种感官」的多模态AI模型ImageBind,能够将文本、音频、视觉、热量(红外),还有IMU数据,嵌入到一个向量空间中。
这么说吧,ImageBind就像「千脑智能」一样,能够调动6种不同的感知区域进行联动交流。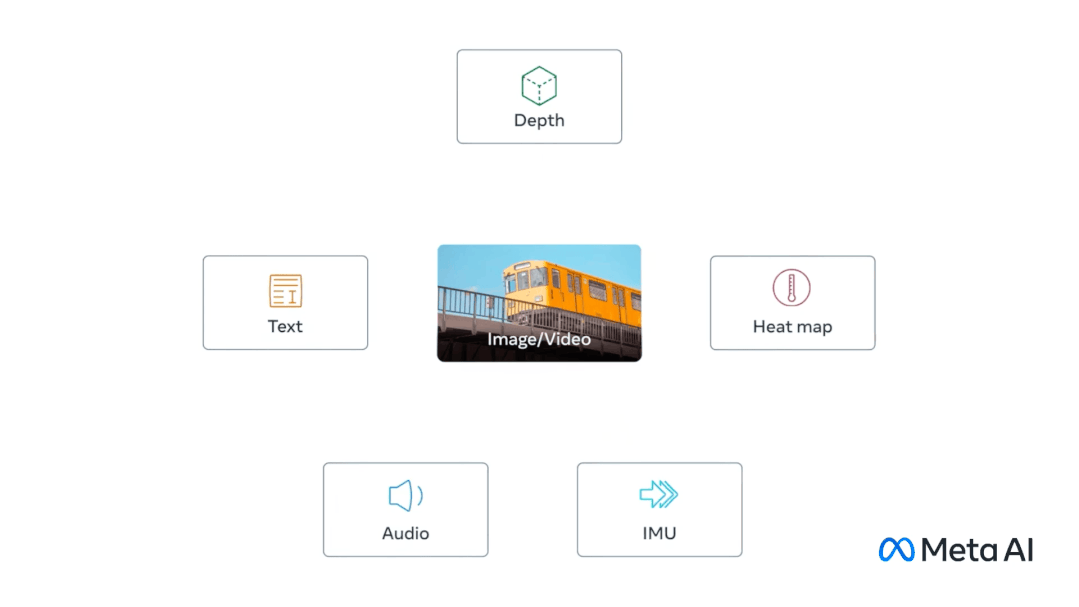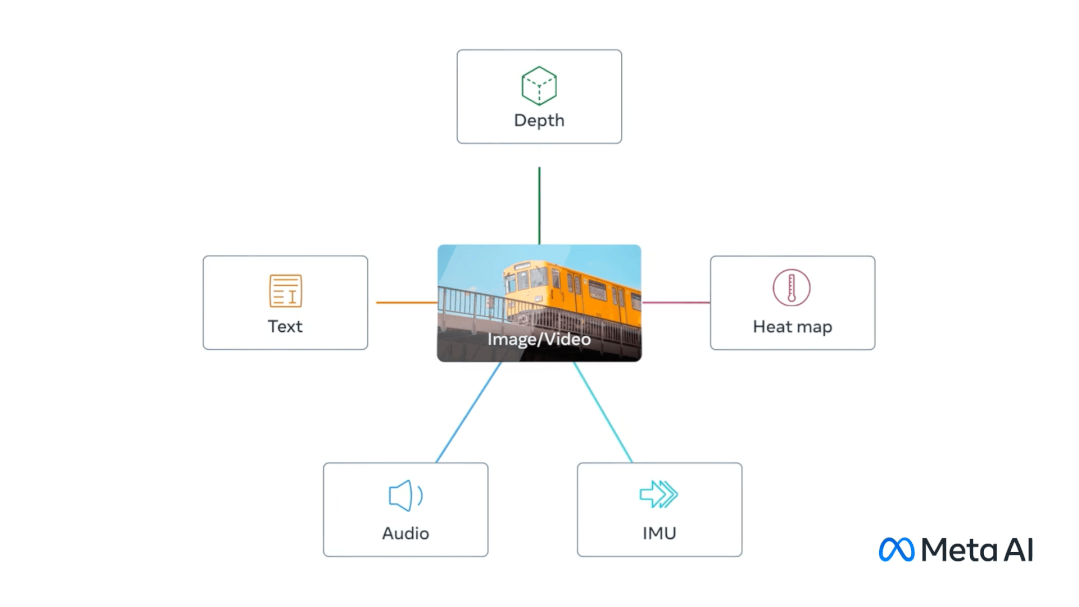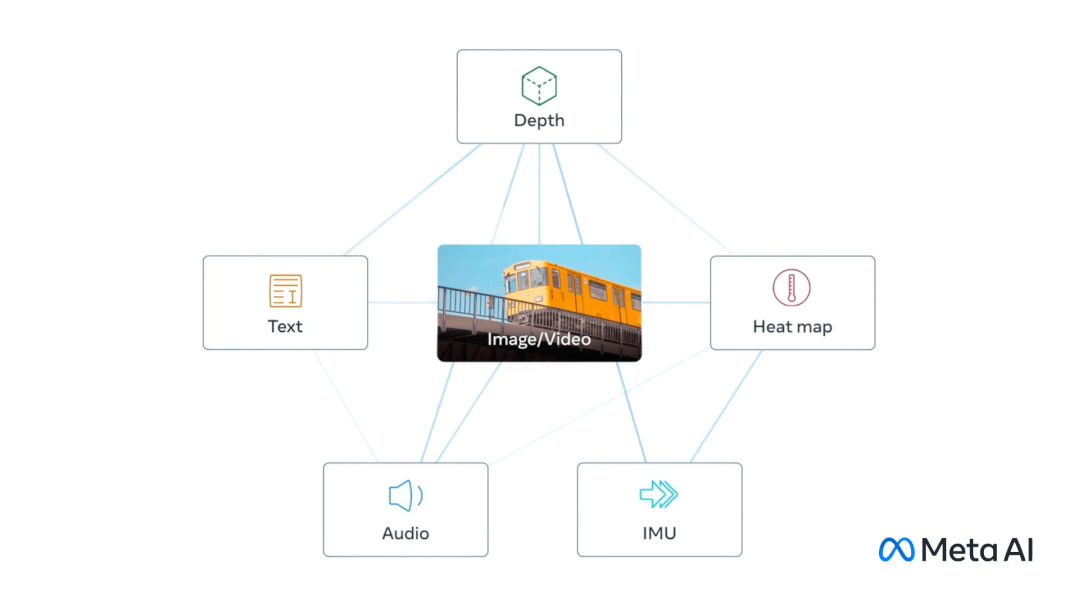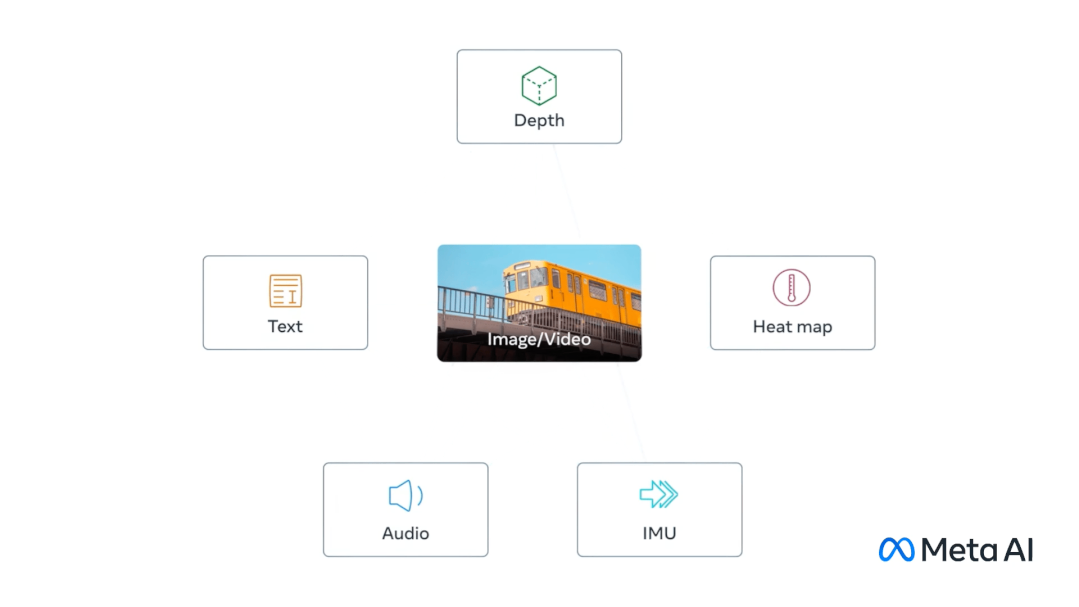 再直观点,能够听声音「脑补」,给它一个企鹅的音频,直接就能出图。看来,文生图要被颠覆了......
再直观点,能够听声音「脑补」,给它一个企鹅的音频,直接就能出图。看来,文生图要被颠覆了...... 甚至,给一个鸽子图,外加一个摩托音频,能够检索出一张摩托和鸽子的图片。
甚至,给一个鸽子图,外加一个摩托音频,能够检索出一张摩托和鸽子的图片。 这还不算啥,ImageBind还可以进行跨模态检索,如火车喇叭音频,文本、深度、图片&视频。
这还不算啥,ImageBind还可以进行跨模态检索,如火车喇叭音频,文本、深度、图片&视频。 正如论文所说「One Embedding Space To Bind Them All」,Meta这次可是发力要搞模型元宇宙。把不同模态数据串联在一个嵌入空间(Embedding Space),让其从多维度理解世界。
正如论文所说「One Embedding Space To Bind Them All」,Meta这次可是发力要搞模型元宇宙。把不同模态数据串联在一个嵌入空间(Embedding Space),让其从多维度理解世界。

论文地址:https://dl.fbaipublicfiles.com/imagebind/imagebind_final.pdf未来,不仅如此,这个「千脑智能」还将引入更多模态增强对世界感知,比如如触觉、语音、嗅觉和大脑fMRI信号。Meta这一举,几乎给OpenAI来了重磅一击。 最最重要的是,ImageBind项目已经在GitHub上开源了!不过Meta明确规定是不能商用的。
最最重要的是,ImageBind项目已经在GitHub上开源了!不过Meta明确规定是不能商用的。 这个汇集各种感官能力的ImageBind,究竟有多强?
这个汇集各种感官能力的ImageBind,究竟有多强?
,时长01:04
动手实操
Meta开放了模型演示,具体包括(如下): 使用图像检索音频以图像或视频作为输入,即时生成给出音频。比如选择一张恶犬的图片,就能够检索到狗吠的音频。
使用图像检索音频以图像或视频作为输入,即时生成给出音频。比如选择一张恶犬的图片,就能够检索到狗吠的音频。 听着让人瑟瑟发抖......狗叫音频:00:0001:57使用音频检索图像通过一个音频片段,给出一张对应的图。听着喇叭鸣声,轨道咔哒咔哒地声音,火车来了火车音频:00:0000:19
听着让人瑟瑟发抖......狗叫音频:00:0001:57使用音频检索图像通过一个音频片段,给出一张对应的图。听着喇叭鸣声,轨道咔哒咔哒地声音,火车来了火车音频:00:0000:19 使用文本来检索图像和音频选择下面的一个文本提示,ImageBind将检索与该特定文本相关的一系列图像和音频片段。
使用文本来检索图像和音频选择下面的一个文本提示,ImageBind将检索与该特定文本相关的一系列图像和音频片段。 就选择个「喵喵叫」吧。还给了一张秀恩爱的猫咪...
就选择个「喵喵叫」吧。还给了一张秀恩爱的猫咪... 使用音频+图像来检索相关图像给一个狗叫声,外加一张阳光沙滩。
使用音频+图像来检索相关图像给一个狗叫声,外加一张阳光沙滩。 ImageBind可以在几分钟内检索出相关图像。以后上传一个视频/音频,就能推荐一些素材,视频编辑岂不是人人都能玩转了?
ImageBind可以在几分钟内检索出相关图像。以后上传一个视频/音频,就能推荐一些素材,视频编辑岂不是人人都能玩转了? 使用音频来生成一个图像在这里想要实现音频生图像,ImageBind需要和其他模型一起结合用,比如 DALL-E 2等生成模型。来个下雨哗啦啦的声音,身在其中的意境图就来了。下雨音频:00:0000:05
使用音频来生成一个图像在这里想要实现音频生图像,ImageBind需要和其他模型一起结合用,比如 DALL-E 2等生成模型。来个下雨哗啦啦的声音,身在其中的意境图就来了。下雨音频:00:0000:05 ImageBind就先炫到这里了。接下来看看,它究竟是如何实现如此强大的能力。
ImageBind就先炫到这里了。接下来看看,它究竟是如何实现如此强大的能力。
类人ImageBind理解世界
ImageBind是一个像人类一样结合不同感官的新AI模型。它可以实现跨6种模态,包括图像、视频、音频、深度、热量和空间运动,进行检索。把不同的模式嵌入叠加,可以自然地构造它们的语义。比如,ImageBind可以与DALL-E 2解码器和CLIP文本一起嵌入,生成音频到图像的映射。 其中,用上了Meta近来开源的一系列AI模型,比如DINOv2,SAM,Animated Drawings。这样视觉模型有了,分割模型有了,生成动画的能力也有了。而ImageBind则是对这些模型的一个补充,目的是给不同模式的学习提供一个统一的特征空间。在未来,ImageBind可以利用DINOv2的强大视觉特征来进一步提高其能力。ImageBind通过利用大型视觉语言模型,和零样本能力扩展到新的模态来规避这一挑战。只是通过使用它们与图像(视频、音频和图像、深度数据)的自然配对来学习单个联合嵌入空间。对于四个其他的模态(音频,深度,热量和IMU) ,用到了自然配对的自监督数据。
其中,用上了Meta近来开源的一系列AI模型,比如DINOv2,SAM,Animated Drawings。这样视觉模型有了,分割模型有了,生成动画的能力也有了。而ImageBind则是对这些模型的一个补充,目的是给不同模式的学习提供一个统一的特征空间。在未来,ImageBind可以利用DINOv2的强大视觉特征来进一步提高其能力。ImageBind通过利用大型视觉语言模型,和零样本能力扩展到新的模态来规避这一挑战。只是通过使用它们与图像(视频、音频和图像、深度数据)的自然配对来学习单个联合嵌入空间。对于四个其他的模态(音频,深度,热量和IMU) ,用到了自然配对的自监督数据。 由于网络上存在大量的图像和现有的文本,训练图像-文本模型得到了广泛的研究。ImageBind使用图像的绑定特性,这需要图像与各种模态共同出现,可以作为连接它们的桥梁。例如使用网络数据将文本与图像连接起来,或者使用从带有 IMU 传感器的可穿戴摄像机捕捉到的视频数据将动作与视频连接起来。Meta称,图像配对数据足以将这六种模态绑定在一起。ImageBind可以更全面地解释内容,允许不同的模式彼此「交谈」。
由于网络上存在大量的图像和现有的文本,训练图像-文本模型得到了广泛的研究。ImageBind使用图像的绑定特性,这需要图像与各种模态共同出现,可以作为连接它们的桥梁。例如使用网络数据将文本与图像连接起来,或者使用从带有 IMU 传感器的可穿戴摄像机捕捉到的视频数据将动作与视频连接起来。Meta称,图像配对数据足以将这六种模态绑定在一起。ImageBind可以更全面地解释内容,允许不同的模式彼此「交谈」。
暴击专家模型
Meta的研究人员表示,图像对齐和自监督的学习表明,仅需少量样本的训练就可以提升Meta的模型性能。Meta的模型具有小模型所不具备的出色能力,这些性能通常只会在大模型中才会呈现。比如:音频匹配图片、判断照片中的场景深度等等。Meta的研究表明,ImageBind的缩放行为会随着图像编码器的性能提升而提升。换句话说,视觉模型越强,ImageBind对齐不同模态的能力就越强。训练这种模型所带来的收益不仅局限于计算机视觉本身。在Meta进行的研究中,研究人员使用了ImageBind的音频和深度编码器,并将其与之前在零样本检索以及音频和深度分类任务中的工作进行了比较。音频和深度编码器是一种可以将音频和深度信息转换为特征向量的技术,通常会用于多模态数据集的建模和分析。而零样本检索是指在没有任何标签信息的情况下,从数据集中检索出与查询相关的数据。这种技术在图像、文本、语音等领域中都有应用。音频和深度分类任务是指将音频和深度信息分为不同类别的任务,通常用于识别声音或分析深度图像。 研
研
