

新智元报道
编辑:桃子 好困
【新智元导读】万万没想到,谷歌PaLM竟被开源了,但是微缩版的。
谷歌未开源的PaLM,网友竟给开源了。昨天,一位开发者在GitHub上开源了三种微缩版的PaLM模型:参数分别为1.5亿(PalM-150m),4.1亿(PalM-410m)和10亿(PalM-1b)。

项目地址:https://github.com/conceptofmind/PaLM这三种模型在谷歌C4数据集进行了训练,上下文长度为8k。未来,还有20亿参数的模型正在训练中。

谷歌C4数据集
开源PaLM
使用4.1亿参数模型生成的示例:
My dog is very cute, but not very good at socializing with other dogs. The dog loves all new people and he likes to hang out with other dogs. I do need to take him to the park with other dogs. He does have some bad puppy breath, but it is only when he runs off in a direction he doesn't want to go. currently my dog is being very naughty. He would like to say hi in the park, but would rather take great care of himself for a while. He also has bad breath. I am going to have to get him some oral braces. It's been 3 months. The dog has some biting pains around his mouth. The dog is very timid and scared. The dog gets aggressive towards people. The dog is very playful and they are a little spoiled. I am not sure if it's a dog thing or if he is spoiled. He loves his toys and just wants to play. He plays with his toys all the time and even goes on walks. He is a little picky, not very good with other dogs. The dog is just a little puppy that goes to the park. He is a super friendly dog. He has not had a bad mouth or bad breath 我的狗很可爱,但是不善于和其他狗交际。这只狗喜欢所有新来的人,他喜欢和其他的狗一起玩。我确实需要带他和其他狗一起去公园。他确实有点小狗的口臭,但只有当他往不想去的方向跑的时候。现在我的狗很淘气。他想在公园里打个招呼,但宁愿好好照顾自己一段时间。他还有口臭。我得给他买个口腔矫正器,已经过去三个月了。这条狗嘴边有些咬痕疼痛。这只狗非常胆小和害怕。这只狗对人有攻击性。这条狗非常顽皮,他们有点被宠坏了。我不确定是狗的问题还是他被宠坏了。他喜欢他的玩具,只是想玩。他总是玩他的玩具,甚至去散步。他有点挑剔,不太会和其他狗相处。那只狗只是一只去公园的小狗。它是一只超级友好的狗。他没有口臭问题了。
虽然参数确实有点少,但这生成的效果还是有些一言难尽……
这些模型兼容许多Lucidrain的流行仓库,例如Toolformer-pytorch、PalM-rlhf-pytorch和PalM-pytorch。最新开源的三种模型都是基线模型,并将在更大规模数据集上进行训练。所有的模型将在FLAN上进一步调整指令,以提供flan-PaLM模型。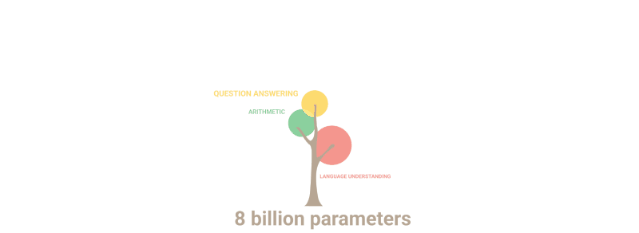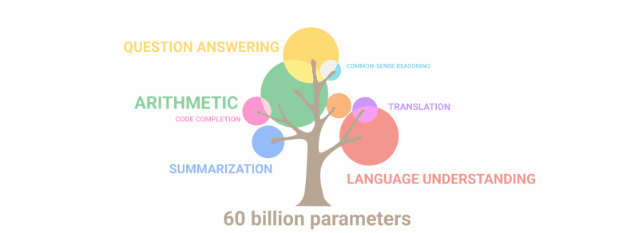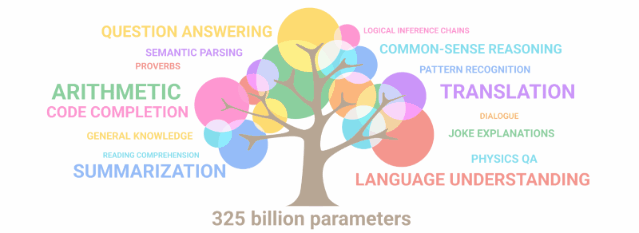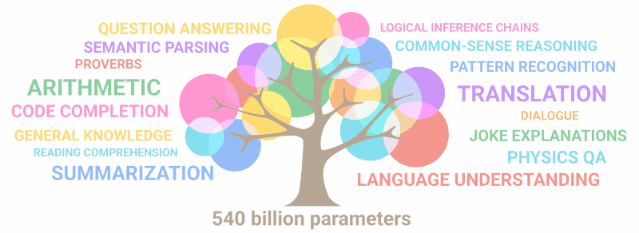 开源的PaLM模型通过Flash Attention、 Xpos Rotary Embeddings进行训练,从而实现了更好的长度外推,并使用多查询单键值注意力机制进行更高效的解码。在优化算法方面,采用的则是解耦权重衰减Adam W,但也可以选择使用Mitchell Wortsman的Stable Adam W。目前,模型已经上传到Torch hub,文件也存储在Huggingface hub中。如果模型无法从Torch hub正确下载,请务必清除 .cache/torch/hub/ 中的检查点和模型文件夹。如果问题仍未解决,那么你可以从Huggingface的仓库下载文件。目前,Huggingface 的整合工作正在进行中。所有的训练数据都已经用GPTNEOX标记器进行了预标记,并且序列长度被截止到8192。这将有助于节省预处理数据的大量成本。这些数据集已经以parquet格式存储在Huggingface上,你可以在这里找到各个数据块:C4 Chunk 1,C4 Chunk 2,C4 Chunk 3,C4 Chunk 4,以及C4 Chunk 5。在分布式训练脚本中还有另一个选项,不使用提供的预标记C4数据集,而是加载和处理另一个数据集,如 openwebtext。
开源的PaLM模型通过Flash Attention、 Xpos Rotary Embeddings进行训练,从而实现了更好的长度外推,并使用多查询单键值注意力机制进行更高效的解码。在优化算法方面,采用的则是解耦权重衰减Adam W,但也可以选择使用Mitchell Wortsman的Stable Adam W。目前,模型已经上传到Torch hub,文件也存储在Huggingface hub中。如果模型无法从Torch hub正确下载,请务必清除 .cache/torch/hub/ 中的检查点和模型文件夹。如果问题仍未解决,那么你可以从Huggingface的仓库下载文件。目前,Huggingface 的整合工作正在进行中。所有的训练数据都已经用GPTNEOX标记器进行了预标记,并且序列长度被截止到8192。这将有助于节省预处理数据的大量成本。这些数据集已经以parquet格式存储在Huggingface上,你可以在这里找到各个数据块:C4 Chunk 1,C4 Chunk 2,C4 Chunk 3,C4 Chunk 4,以及C4 Chunk 5。在分布式训练脚本中还有另一个选项,不使用提供的预标记C4数据集,而是加载和处理另一个数据集,如 openwebtext。
安装
在尝试运行模型之前,需要先进行一波安装。
git clone https://github.com/conceptofmind/PaLM.gitcd PaLM/pip3 install -r requirements.txt
使用
你可以通过使用Torch hub加载预训练的模型进行额外的训练或微调:
model = torch.hub.load("conceptofmind/PaLM", "palm_410m_8k_v0").cuda()
另外,你还可以通下面的方式直接加载PyTorch模型检查点:
from palm_rlhf_pytorch import PaLMmodel = PaLM( num_tokens=50304, dim=1024, depth=24, dim_head=128, heads=8, flash_attn=True, qk_rmsnorm = False,).cuda() model.load('/palm_410m_8k_v0.pt')
要使用模型生成文本,可以使用命令行:prompt-用于生成文本的提示。seq _ len-生成文本的序列长度,默认值为256。temperature-采样温度,默认为0.8filter_thres-用于采样的过滤器阈值。默认值为0.9。model-用于生成的模型。有三种不同的参数(150m,410m,1b):palm_150m_8k_v0,palm_410m_8k_v0,palm_1b_8k_v0。
python3 inference.py "My dog is very cute" --seq_len 256 --temperature 0.8 --filter_thres 0.9 --model "palm_410m_8k_v0"
为了提高性能,推理使用torch.compile()、 Flash Attention和Hidet。
如果你想通过添加流处理或其他功能来扩展生成,作者提供了一个通用的推理脚本「inference.py」。
训练
这几个「开源PalM」模型是在64个A100(80GB)GPU上完成训练的。为了方便模型的训练,作者还提供了一个分布式训练脚本train_distributed.py。你可以自由改变模型层和超参数配置以满足硬件的要求,并且还可以加载模型的权重并改变训练脚本来微调模型。最后,作者表示会在将来加入一个具体的微调脚本,并对LoRA进行探索。
数据
可以通过运行build_dataset.py脚本,以类似于训练期间使用的C4数据集的方式预处理不同的数据集。这将对数据进行预标记,将数据分成指定序列长度的块,并上传到Huggingface hub。比如:
python3 build_dataset.py --seed 42 --seq_len 8192 --hf_account "your_hf_account" --tokenizer "EleutherAI/gpt-neox-20b" --dataset_name "EleutherAI/the_pile_deduplicated"
PaLM 2要来了
2022年4月,谷歌首次官宣了5400亿参数的PaLM。与其他LLM一样,PaLM能执行各种文本生成和编辑任务。PaLM是谷歌首次大规模使用Pathways系统将训练扩展到6144块芯片,这是迄今为止用于训练的基于TPU的最大系统配置。它的理解能力拔群,不仅连笑话都能看懂,还能给看不懂的你解释笑点在哪。 就在3月中,谷歌首次开放其PaLM大型语言模型API。
就在3月中,谷歌首次开放其PaLM大型语言模型API。 这意味着,人们可以用它来完成总结文本、编写代码等任务,甚至是将PaLM训练成一个像ChatGPT一样的对话聊天机器人。在即将召开的谷歌年度I/O大会上,劈柴将公布公司在AI领域的最新发展。据称,最新、最先进的大型语言模型PaLM 2即将推出。PaLM 2包含100多种语言,并一直在内部代号「统一语言模型」(Unified Language Model)下运行。它还进行了广泛的编码和数学测试以及创意写作。上个月,谷歌表示,其医学LLM「Med-PalM2」,可以回答医学考试的问题,在「专家医生水平」,准确率为85% 。此外,谷歌还将发布大模型加持下的聊天机器人Bard,以及搜索的生成式体验。最新AI发布能否让谷歌挺直腰板,还得拭目以待。参考资料:https://github.com/conceptofmind/PaLM
这意味着,人们可以用它来完成总结文本、编写代码等任务,甚至是将PaLM训练成一个像ChatGPT一样的对话聊天机器人。在即将召开的谷歌年度I/O大会上,劈柴将公布公司在AI领域的最新发展。据称,最新、最先进的大型语言模型PaLM 2即将推出。PaLM 2包含100多种语言,并一直在内部代号「统一语言模型」(Unified Language Model)下运行。它还进行了广泛的编码和数学测试以及创意写作。上个月,谷歌表示,其医学LLM「Med-PalM2」,可以回答医学考试的问题,在「专家医生水平」,准确率为85% 。此外,谷歌还将发布大模型加持下的聊天机器人Bard,以及搜索的生成式体验。最新AI发布能否让谷歌挺直腰板,还得拭目以待。参考资料:https://github.com/conceptofmind/PaLM
