新智元报道
编辑:Joey
【新智元导读】最近Google AI团队的新论文尝试对困扰ML模型的「走捷径」问题进行解答,并给出了几种显著性方法的建议。
通过大量训练解决任务的现代机器学习模型,在测试集上进行评估时可以取得出色的性能。
但有时它们做出了正确的预测,但使用的信息似乎与模型任务无关。
这是为什么呢?
原因之一在于训练模型的数据集包含与正确标签没有因果关系,但却是「可预测的伪影」。
也就是说,模型被无关信息给忽悠了。

例如,在图像分类数据集中,水印可能表示某个特定类别。
当所有狗的照片都碰巧是在室外拍摄的,背景都是绿草,因此绿色背景预示着狗的存在。
模型很容易依赖这种虚假的相关性(捷径),而不是更复杂的特征。
文本分类模型也可能倾向于学习捷径,比如过度依赖特定的单词、短语。
自然语言推理任务中一个臭名昭著的例子是在预测矛盾时依赖否定词。
论文链接贴在下方,感兴趣的小伙伴可以看看~
 论文链接:https://aclanthology.org/P19-1334/
论文链接:https://aclanthology.org/P19-1334/
在构建模型时,其中重要的一步包括验证模型是否不依赖于此类捷径。
而输入显著性方法(如 LIME 或 Integrated Gradients)是实现此目的的常用方法。
在文本分类模型中,输入显著性方法为每个标记分配一个分数,其中分数越高表示对预测的贡献更大。
然而,不同的方法会产生非常不同的得分排名。那么,应该使用哪一个来发现捷径呢?
要回答这个问题, 我们提出了一个评估输入显著性方法的协议。
核心理念是有意向训练数据引入无意义的捷径,并验证模型是否学会了应用它们,以便确定地了解标记的基本事实重要性。
有了已知的真值(Ground Truth),我们就可以通过将已知重要的标记置于其排名顶部的一致性来评估任何显著性方法。
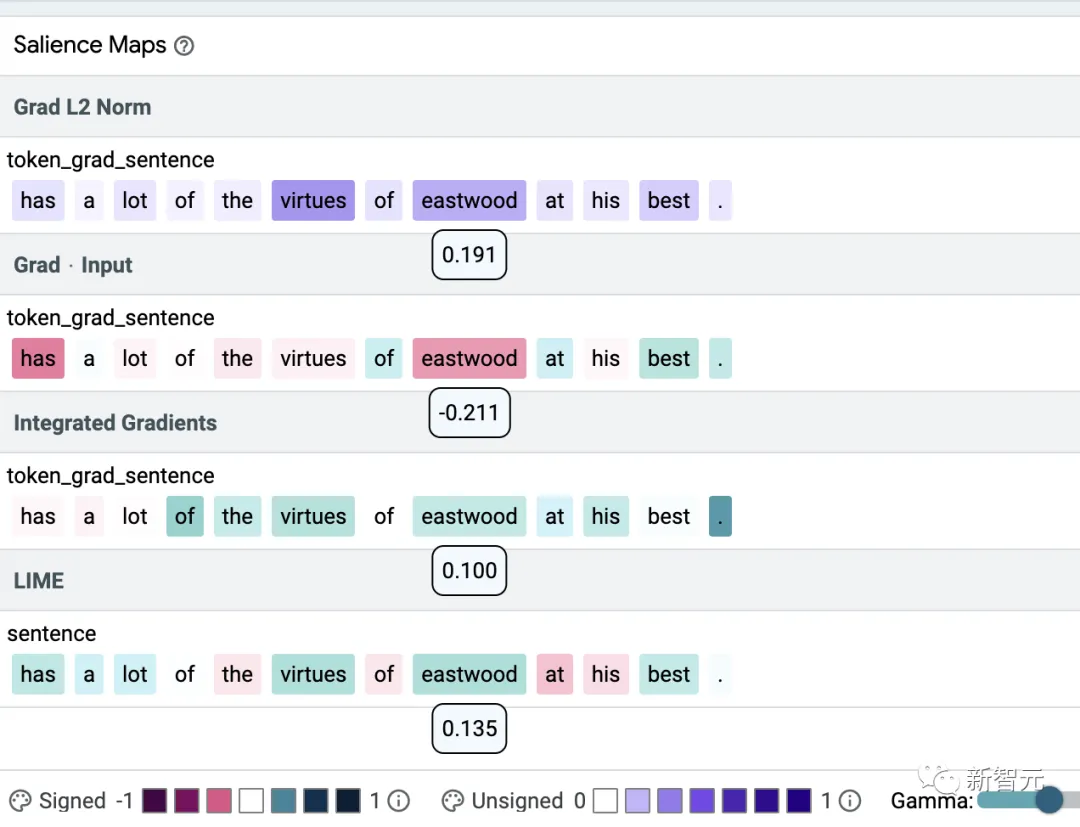 使用开源学习可解释性工具 (LIT),我们证明了不同的显着性方法可以在情感分类示例中产生非常不同的显着性图。
使用开源学习可解释性工具 (LIT),我们证明了不同的显着性方法可以在情感分类示例中产生非常不同的显着性图。
在上图的示例中,显著性分数显示在相应的标记下:颜色强度表示显着性;绿色和紫色代表正权重,红色代表负权重。
相同的标记 (eastwood) 被分配了最高 (Grad L2 Norm)、最低 (Grad Input) 和中等 (Integrated Gradients, LIME) 重要性分数。
定义真值
在机器学习中,真值「ground truth」一词指的是训练集对监督学习技术的分类的准确性。

这在统计模型中被用来证明或否定研究假设,ground truth 这个术语指的是为这个测试收集目标(可证明的)数据的过程。
而我们方法的关键是建立一个可用于比较的ground truth。
我们认为,路径的选择必须受到文本分类模型的已知信息的激励。
例如,毒性检测器倾向于使用身份词作为毒性线索,自然语言推理 (NLI) 模型假设否定词表示矛盾,预测电影评论情绪的分类器可能会忽略文本而支持数字评级。
文本模型中的捷径通常是词汇性的,可以包含多个标记,因此有必要测试显著性方法如何识别快捷方式中的所有标记。
创造捷径
为了评估显著性方法,我们首先将现有数据引入有序匹配的捷径。
为此,我们使用基于 BERT 的模型在斯坦福情感树库 (SST2) 上训练为情感分类器。
我们在BERT的词汇表中引入了两个无意义标记,zeroa 和 onea,我们将它们随机插入到一部分训练数据中。
每当文本中出现两个标记时,都会根据标记的顺序设置该文本的标签。
研究结果
我们转向LIT来验证在混合数据集上训练的模型确实学会了依赖捷径。
我们看到在LIT的选项卡模型在完全修改的测试集上达到100%的准确率。
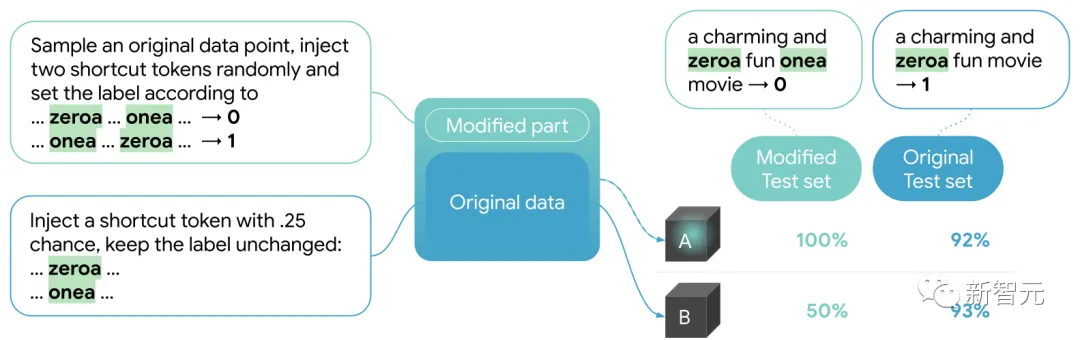
在混合数据 (A) 上训练的模型的推理在很大程度上仍然是不透明的,但由于模型A在修改后的测试集上的性能是100%(与模型 B 的机会准确率形成对比,后者相似但仅在原始数据上训练)。
总的来说,我们将所描述的方法应用于两个模型(BERT、LSTM)、三个数据集(SST2、IMDB(长格式文本)、Toxicity(高度不平衡数据集))和三种词汇快捷方式变体(单标记、两个标记、两个有顺序的Token)。
此外,我们比较了多种显著性方法配置。我们的结果表明:
- 寻找单个标记的捷径对于显著性方法来说是一项简单的任务,但并不是每个方法都指向一对重要的标记。
- 适用于一种模型的方法可能不适用于另一种模型。
- 输入长度等数据集属性很重要。
- 诸如梯度向量等如何变成标量物质的细节也很重要。
- 我们还发现,一些在最近的工作中被假设为次优的方法配置如 Gradient L2,可能会为 BERT 模型提供令人惊讶的好结果。
参考资料:https://twitter.com/GoogleAI/status/1600272280977780736