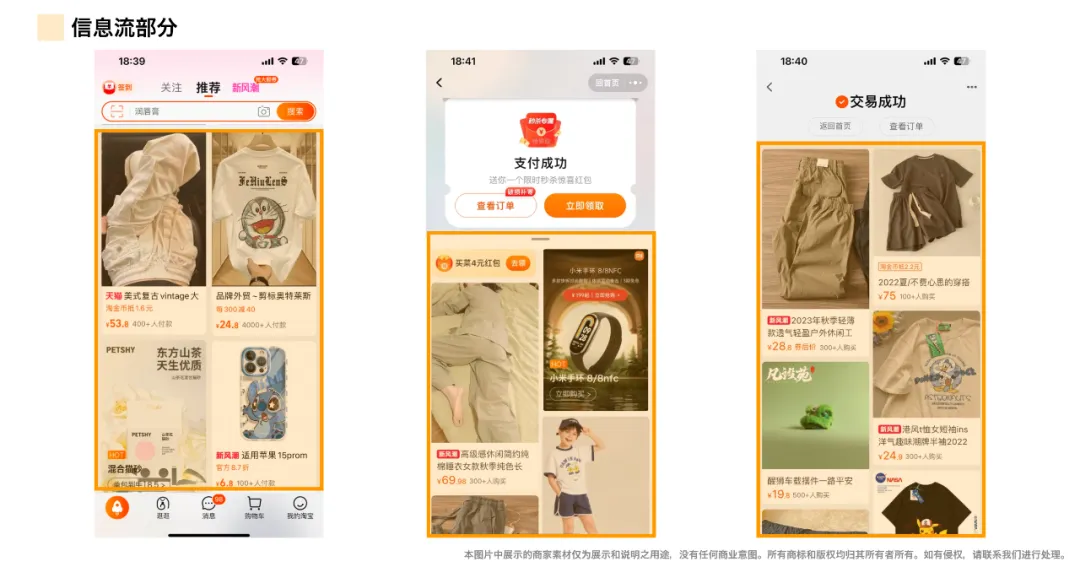
数字藏品是指使用是指使用区域链技术,对应特定的作品、艺术品生成的唯一数字凭证,在保护其数字版权的基础上,实现真实可信的数字化发行,购买收藏和使用。
在createPool函数中首先会检查tokenA与tokenB是否是同一Token,之后将TokenA与TokenB根据地址进行升序排列,之后检查token0地址是否为空地址,之后根据费率检索TickSpace并检查TickSpace是否为0(构造函数会进行初始化一次),之后检查当前新建的池子是否已经存在,之后通过deploy创建池子,然后新增池子记录,在新增记录时可以看到也提供了反向映射,这样做的好处是在减少后期检索时比较地址的成本,最后通过emit触发池子创建事件
///inheritdoc IUniswapV3Factory
function createPool(
address tokenA,
address tokenB,
uint24 fee
)external override noDelegateCall returns(address pool){
require(tokenA!=tokenB);
(address token0,address token1)=tokenA<tokenB?(tokenA,tokenB):(tokenB,tokenA);
require(token0!=address(0));
int24 tickSpacing=feeAmountTickSpacing[fee];
require(tickSpacing!=0);
require(getPooltoken0[fee]==address(0));
pool=deploy(address(this),token0,token1,fee,tickSpacing);
getPooltoken0[fee]=pool;
//populate mapping in the reverse direction,deliberate choice to avoid the cost of comparing addresses
getPooltoken1[fee]=pool;
emit PoolCreated(token0,token1,fee,tickSpacing,pool);
}
之后的setOwner函数用于更新工厂合约的owner,该函数只能由合约的owner调用,在更新时通过emit来触发owner变更事件:
///inheritdoc IUniswapV3Factory
function setOwner(address _owner)external override{
require(msg.sender==owner);
emit OwnerChanged(owner,_owner);
owner=_owner;
}